java 中文一,二,到十,怎么排序
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 中文一,二,到十,怎么排序相关的知识,希望对你有一定的参考价值。
具体是:数据库中有个属性是class:A级一班、A级二班。。。到A级十班;B级一班,B级二班。。。;C级一班。。。排序使得它是我们熟知的顺序。A到Z,一到十,首要A在前面,然后考虑一到十
不知道说得明白么。。。
你的建议挺好
参考技术A 截取字符串啊,A级一班 B级一班,截取第一个字符substring(0,1);,AB可以直接排序。截取第三个字符串,然后变成数字的排序,字母的随便
String ss0="A级一班";
ss0=ss0.substring(2,3);
if(ss0.equals("一"))
ss0 = "0";
追问
这个稍显麻烦,不过可以解决
参考技术B常用数据库都有排序引擎,用sql语句排序就ok
select * from myTable order by 'class' asc追问这个我试过用按笔画 by nlssort(columnName,'NLS_SORT=SCHINESE_STROKE_M')
按部首 by nlssort(columnName,'NLS_SORT=SCHINESE_RADICAL_M')
按拼音 by nlssort(columnName,'NLS_SORT=SCHINESE_PINYIN_M');
都不能适用我,你的不知道为什么是:二三四一
对于这样的情况,我有个建议
你可以单独建立一个表用来索引汉字,比如
create table index_char_Chinese(charIndex int primary key,charChinese not null unique);insert into index_char_Chinese values(0,'零');
insert into index_char_Chinese values(1,'一');
insert into index_char_Chinese values(2,'二');
insert into index_char_Chinese values(3,'三');
insert into index_char_Chinese values(4,'四');
insert into index_char_Chinese values(5,'五');
insert into index_char_Chinese values(6,'六');
insert into index_char_Chinese values(7,'七');
insert into index_char_Chinese values(8,'八');
insert into index_char_Chinese values(9,'九');
然后用连接表查询,
用 grounp by substring(‘class’,0,1)对年级分组,
order by table index_char_Chinese.charIndex asc
这样会比你自己写算法好好一些
算法---JAVA实现堆排序(大顶堆)
堆排序是一种树形选择排序方法,它的特点是:在排序的过程中,将array[0,...,n-1]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(最小)的元素。
1. 若array[0,...,n-1]表示一颗完全二叉树的顺序存储模式,则双亲节点指针和孩子结点指针之间的内在关系如下:
任意一节点指针 i:父节点:i==0 ? null : (i-1)/2
左孩子:2*i + 1
右孩子:2*i + 2
2. 堆的定义:n个关键字序列array[0,...,n-1],当且仅当满足下列要求:(0 <= i <= (n-1)/2)
① array[i] <= array[2*i + 1] 且 array[i] <= array[2*i + 2]; 称为小根堆;
② array[i] >= array[2*i + 1] 且 array[i] >= array[2*i + 2]; 称为大根堆;
3. 建立大根堆:
n个节点的完全二叉树array[0,...,n-1],最后一个节点n-1是第(n-1-1)/2个节点的孩子。对第(n-1-1)/2个节点为根的子树调整,使该子树称为堆。
对于大根堆,调整方法为:若【根节点的关键字】小于【左右子女中关键字较大者】,则交换。
之后向前依次对各节点((n-2)/2 - 1)~ 0为根的子树进行调整,看该节点值是否大于其左右子节点的值,若不是,将左右子节点中较大值与之交换,交换后可能会破坏下一级堆,于是继续采用上述方法构建下一级的堆,直到以该节点为根的子树构成堆为止。
反复利用上述调整堆的方法建堆,直到根节点。
4.堆排序:(大根堆)
①将存放在array[0,...,n-1]中的n个元素建成初始堆;
②将堆顶元素与堆底元素进行交换,则序列的最大值即已放到正确的位置;
③但此时堆被破坏,将堆顶元素向下调整使其继续保持大根堆的性质,再重复第②③步,直到堆中仅剩下一个元素为止。
堆排序算法的性能分析:
空间复杂度:o(1);
时间复杂度:建堆:o(n),每次调整o(log n),故最好、最坏、平均情况下:o(n*logn);
稳定性:不稳定
建立大根堆的方法:
建立完成后进行堆排序:

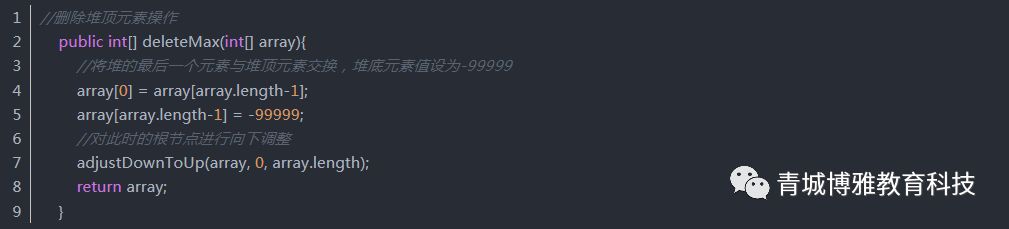
删除堆顶元素:
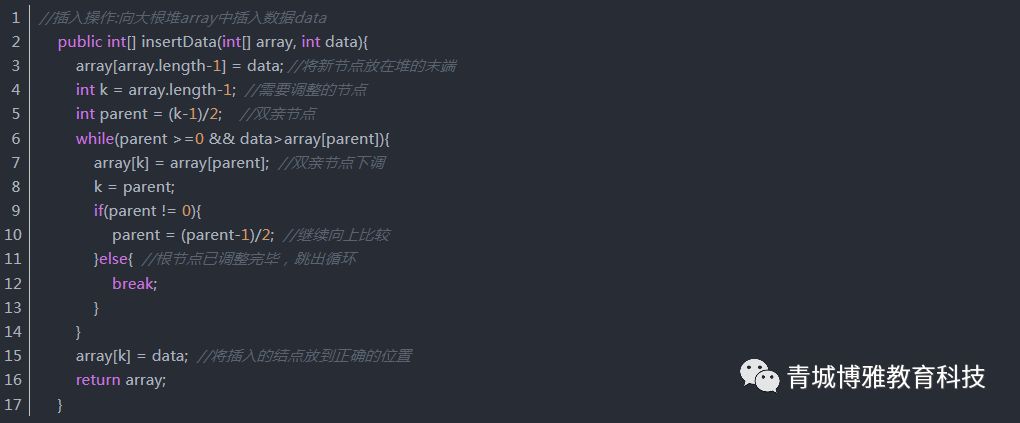
对堆的插入操作:先将新节点放在堆的末端,再对这个新节点执行向上调整操作。
假设数组的最后一个元素array[array.length-1]为空,新插入的结点初始时放置在此处。
进行测试:
以上是关于java 中文一,二,到十,怎么排序的主要内容,如果未能解决你的问题,请参考以下文章