Redis学习
Posted 疯子姓张
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习相关的知识,希望对你有一定的参考价值。
一、是什么
二、Java配置Redis
1下载
下载地址:https://github.com/MSOpenTech/redis/releases

2 解压到自己想要的目录下
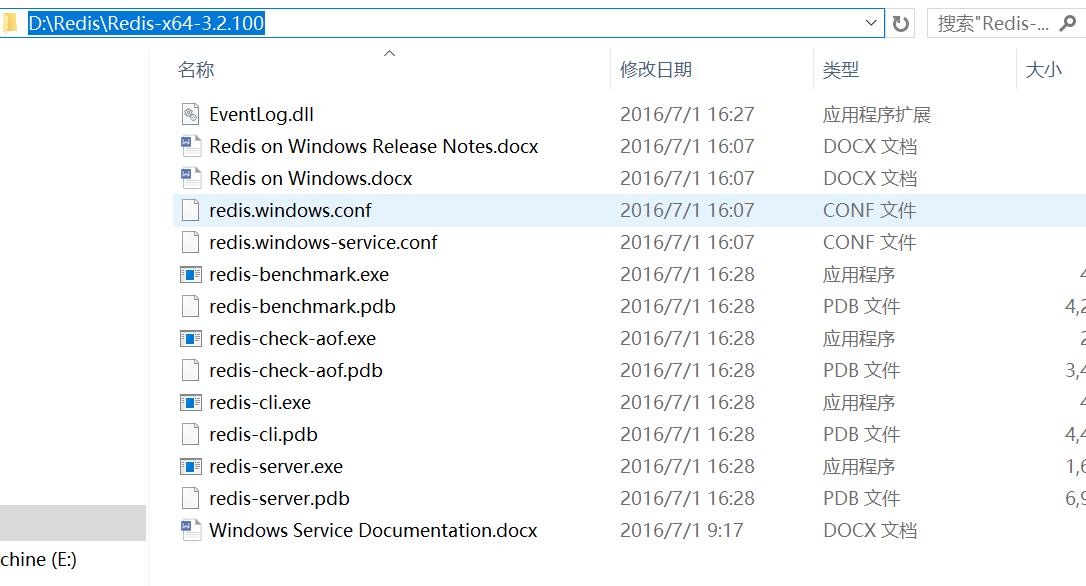
3 打开一个CMD窗口,执行如下命令,显示如下图形,说明rendis服务器启动成功了

4 再打开一个CMD窗口,执行redis客户端命令,(这是独立操作客户端,如果在java里面配置使用redis,就不需要进行这一步)

三、Java配置Redis
1 确保已经安装Reids服务器
2 导入 java redis 驱动包,pom文件中加入以下:

四、连接到Redis服务器
import redis.clients.jedis.Jedis; public class RedisJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); } }
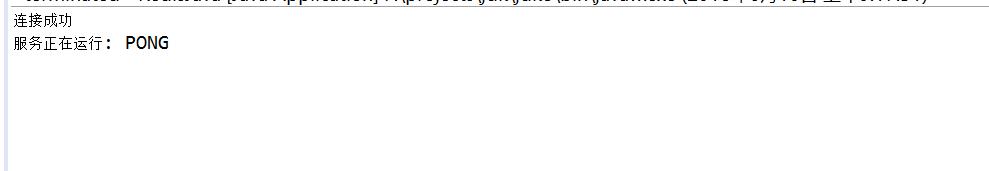
五、值为字符串
import redis.clients.jedis.Jedis; public class RedisJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); //设置 redis 字符串数据 jedis.set("love", "familly"); // 获取存储的数据并输出 System.out.println("redis 存储的字符串为: "+ jedis.get("love")); } }

六、获取所有
import java.util.Iterator; import java.util.Set; import redis.clients.jedis.Jedis; public class RedisJava { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); // 获取数据并输出 Set<String> keys = jedis.keys("*"); Iterator<String> it=keys.iterator() ; while(it.hasNext()){ String key = it.next(); System.out.println(key); } } }

四、有哪些功能?
A Redis 配置(所有配置信息都在这个配置文件里面)
1 查看配置
两种方式,一种是 直接打开配置文件查看,另一种是命令查看。
CONFIG GET 配置项名称

配置名称用 * ,表示所有配置项
2 修改配置
CONFIG SET 配置项名称 新的值
3 Redis有哪些配置项(这里只例举常用的)
redis.conf 配置项说明如下: 1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程 daemonize no 2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定 pidfile /var/run/redis.pid 3. 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字 port 6379 4. 绑定的主机地址 bind 127.0.0.1 5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能 timeout 300 6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose loglevel verbose 7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null logfile stdout 8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id databases 16 9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合 save <seconds> <changes> Redis默认配置文件中提供了三个条件: save 900 1 save 300 10 save 60 10000 分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。 10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大 rdbcompression yes 11. 指定本地数据库文件名,默认值为dump.rdb dbfilename dump.rdb 12. 指定本地数据库存放目录 dir ./ 13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步 slaveof <masterip> <masterport> 14. 当master服务设置了密码保护时,slav服务连接master的密码 masterauth <master-password> 15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭 requirepass foobared 16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息 maxclients 128 17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区 maxmemory <bytes> 18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no appendonly no 19. 指定更新日志文件名,默认为appendonly.aof appendfilename appendonly.aof 20. 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折衷,默认值) appendfsync everysec 21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制) vm-enabled no 22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享 vm-swap-file /tmp/redis.swap 23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0 vm-max-memory 0 24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值 vm-page-size 32 25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。 vm-pages 134217728 26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 vm-max-threads 4 27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启 glueoutputbuf yes 28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法 hash-max-zipmap-entries 64 hash-max-zipmap-value 512 29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍) activerehashing yes 30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件 include /path/to/local.conf
M Redis 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。 发送者可以是多个。多对多

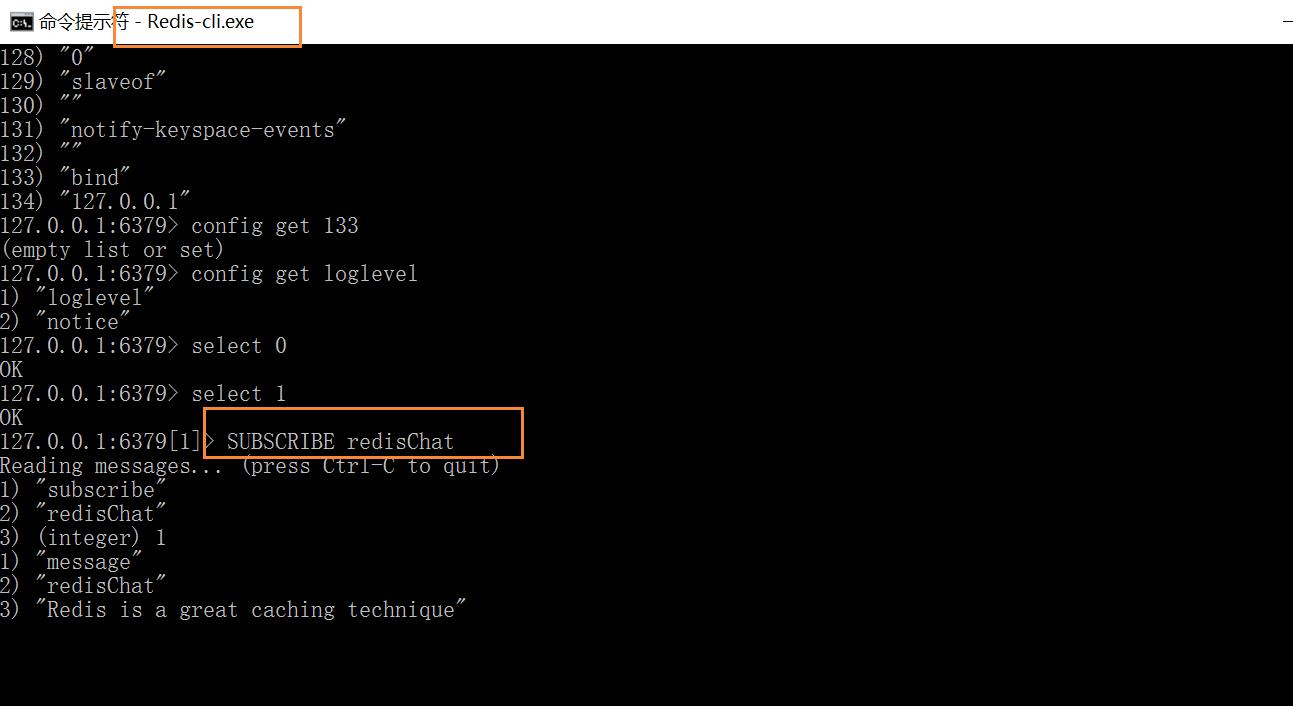
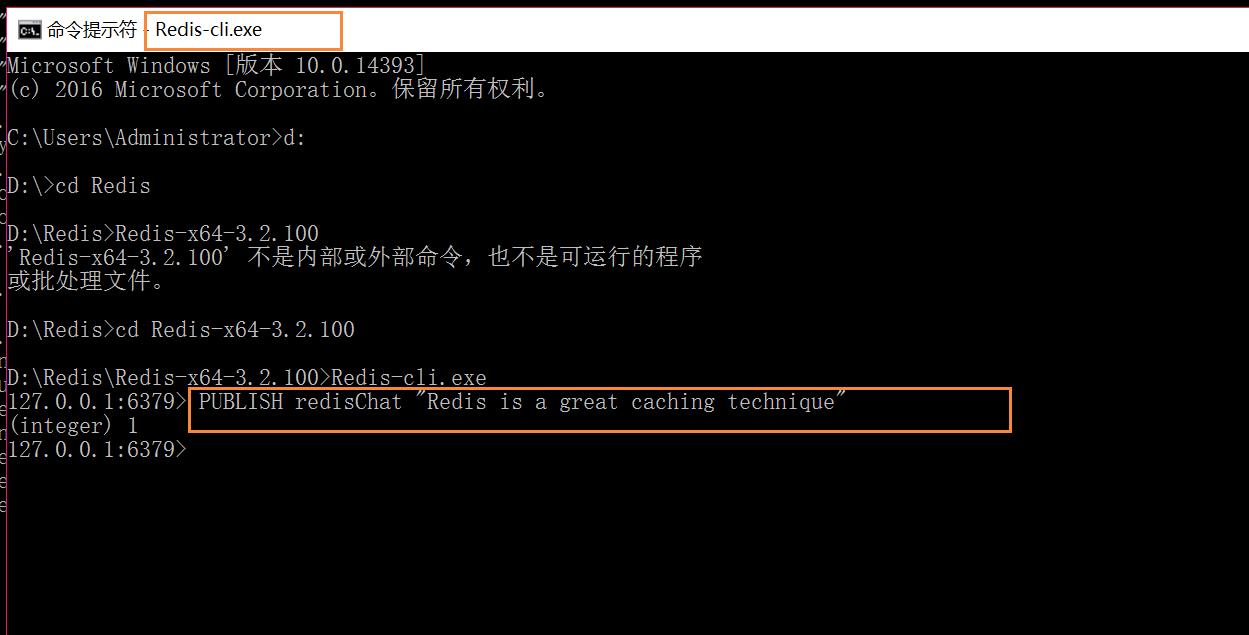
1 创建了订阅频道名为 redisChat:(这个窗口订阅了并创建了这个频道) SUBSCRIBE redisChat 2 重新开启个 redis 客户端,然后在同一个频道 redisChat 发布消息,订阅者就能接收到消息。(发送者) PUBLISH redisChat "Redis is a great caching technique"
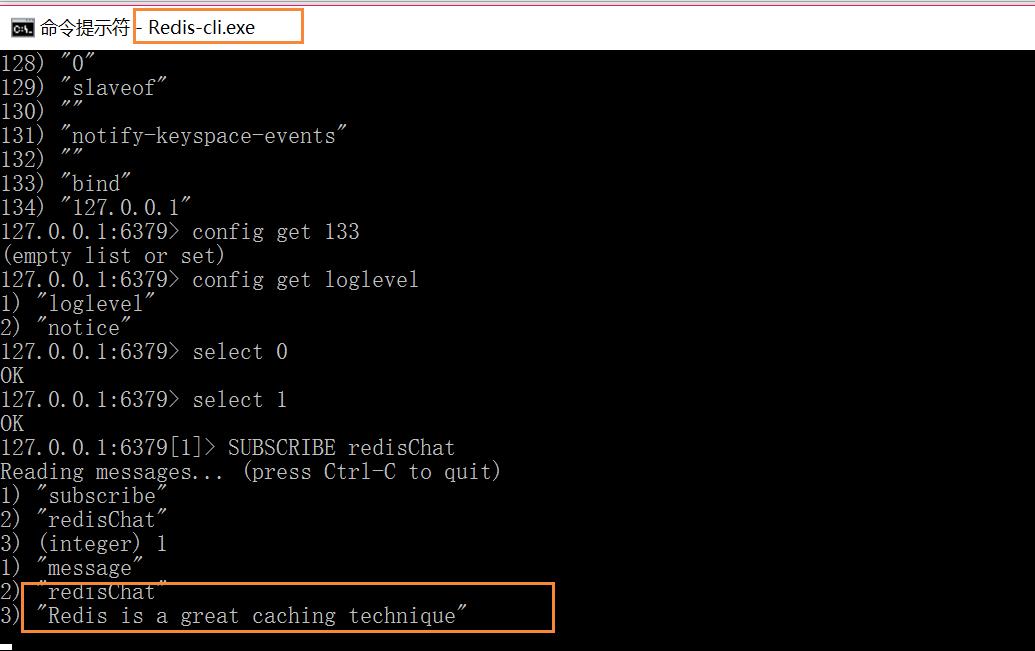
SUBSCRIBE channel [channel ...] //订阅给定的一个或多个频道的信息。 UNSUBSCRIBE channel [channel ...] //退订给定的一个或多个频道的信息。 PSUBSCRIBE pattern [pattern ...] //订阅一个或多个符合给定模式的频道 PUNSUBSCRIBE [pattern [pattern ...]] // 退订所有给定模式的频道 PUBLISH channel message //将信息发送到指定的频道 PUBSUB <subcommand> [argument [argument ...]] //用于查看订阅与发布系统状态,它由数个不同格式的子命令组成 .返回:由活跃频道组成的列表。
N Redis 事务(并不是真的事务,只是批处理)
redis的事务并不是真正的事务,只是批处理。
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
1 批量操作在发送 EXEC 命令前被放入队列缓存。
2 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
3 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
1 开始事务。
2 命令入队。
3 执行事务。
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
MULTI //标记一个事务块的开始。 EXEC //执行所有事务块内的命令。 DISCARD //取消事务,放弃执行事务块内的所有命令。 WATCH key [key ...] //监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。总是返回ok UNWATCH //取消 WATCH 命令对所有 key 的监视。
O Redis 脚本
Redis 脚本使用 Lua 解释器来执行脚本。
EVAL script numkeys key [key ...] arg [arg ...] //执行 Lua 脚本。 EVALSHA sha1 numkeys key [key ...] arg [arg ...] SCRIPT LOAD script //将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。 SCRIPT FLUSH //从脚本缓存中移除所有脚本。 SCRIPT EXISTS script [script ...] //查看指定的脚本是否已经被保存在缓存当中。 SCRIPT KILL //杀死当前正在运行的 Lua 脚本。
P Redis 连接
Redis 连接命令主要是用于连接 redis 服务。
AUTH PASSWORD //验证密码是否正确:用于检测给定的密码和配置文件中的密码是否相符。成功ok,否则报错 PING //查看服务是否运行:使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG 。否则报错 QUIT //关闭当前连接 SELECT index //切换到指定的数据库:数据库索引号 index 用数字值指定,以 0 作为起始索引值。 ECHO message //打印字符串
Q Redis 服务器
Redis 服务器命令主要是用于管理 redis 服务。
具体命令略
R Redis 数据备份与恢复
备份(两种命令)
用于创建当前数据库的备份。
SAVE
该命令将在 redis 安装目录中创建dump.rdb文件。
BGSAVE
创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行。
恢复
如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令,如下所示:
redis 127.0.0.1:6379> CONFIG GET dir 1) "dir" 2) "/usr/local/redis/bin" //以上命令 CONFIG GET dir 输出的 redis 安装目录为 /usr/local/redis/bin。
R Redis 安全
我们可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全。
//查看是否设置了密码验证: CONFIG get requirepass //设置密码 CONFIG set requirepass "runoob" //用密码登录 AUTH password
T Redis性能测试
就是看看每秒执行多少请求啊之类的,命令略。
U Redis 客户端连接
Redis 通过监听一个 TCP 端口或者 Unix socket 的方式来接收来自客户端的连接,当一个连接建立后,Redis 内部会进行以下一些操作:
首先,客户端 socket 会被设置为非阻塞模式,因为 Redis 在网络事件处理上采用的是非阻塞多路复用模型。
然后为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
然后创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
config get maxclients //最大连接数 CLIENT LIST //返回连接到 redis 服务的客户端列表 CLIENT SETNAME //设置当前连接的名称 CLIENT GETNAME //获取通过 CLIENT SETNAME 命令设置的服务名称 CLIENT PAUSE //挂起客户端连接,指定挂起的时间以毫秒计 CLIENT KILL //关闭客户端连接
V Redis 管道技术(个人感觉高效率的批处理)
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
服务端处理命令,并将结果返回给客户端
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
W Redis 分区
分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。
分区的优势
通过利用多台计算机内存的和值,允许我们构造更大的数据库。
通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
分区的不足
涉及多个key的操作通常是不被支持的。举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
涉及多个key的redis事务不能使用。
当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
增加或删除容量也比较复杂。redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端分区、代理等其他系统则不支持这项特性。然而,一种叫做presharding的技术对此是有帮助的。
分区类型
范围分区
最简单的分区方式是按范围分区,就是映射一定范围的对象到特定的Redis实例。
比如,ID从0到10000的用户会保存到实例R0,ID从10001到 20000的用户会保存到R1,以此类推。
这种方式是可行的,并且在实际中使用,不足就是要有一个区间范围到实例的映射表。这个表要被管理,同时还需要各 种对象的映射表,通常对Redis来说并非是好的方法。
另外一种分区方法是hash分区。这对任何key都适用,也无需是object_name:这种形式,像下面描述的一样简单:
用一个hash函数将key转换为一个数字,比如使用crc32 hash函数。对key foobar执行crc32(foobar)会输出类似93024922的整数。
对这个整数取模,将其转化为0-3之间的数字,就可以将这个整数映射到4个Redis实例中的一个了。93024922 % 4 = 2,就是说key foobar应该被存到R2实例中。注意:取模操作是取除的余数,通常在多种编程语言中用%操作符实现。
以上是关于Redis学习的主要内容,如果未能解决你的问题,请参考以下文章