mysql的索引的学习
Posted 清风徐徐而来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql的索引的学习相关的知识,希望对你有一定的参考价值。
优秀相关博客地址
1. https://www.cnblogs.com/liqiangchn/p/9060521.html 通俗易懂
一、索引的分类
1:从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。
hash索引和B+索引的区别:1)hash使用于等值查询,而b索引可以进行排序、范围、组合。
2:从应用层次来分:普通索引,唯一索引,复合索引
3:根据中数据的物理顺序与键值的逻辑(索引)顺序关系:聚集索引,非聚集索引。
1中所描述的是索引存储时保存的形式,2是索引使用过程中进行的分类,两者是不同层次上的划分。
不过平时讲的索引类型一般是指在应用层次的划分。
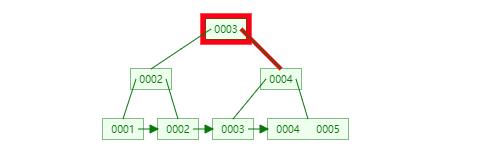
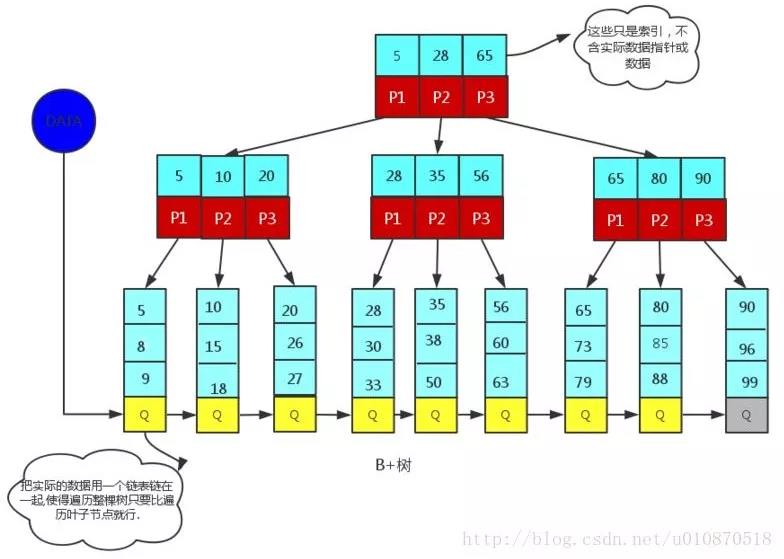
二、B、B+树
B+树是B-树的优化,B+树是非叶子节点做索引项,叶子节点做数据信息项,并且叶子节点每M个也就是一个数据页之间是使用指针进行关联,也就是B+树只需要遍历叶子节点就可以实现整个树的遍历,可以更加好地使用范围查询。
B+树增加和删除是符合B树的特性,当子孩子项大于M时,数据就会分裂,中间的节点就会充当父节点。
基于主键进行创建索引,可以减少当增加和删除时候产生的数据分裂的数据更新的操作。
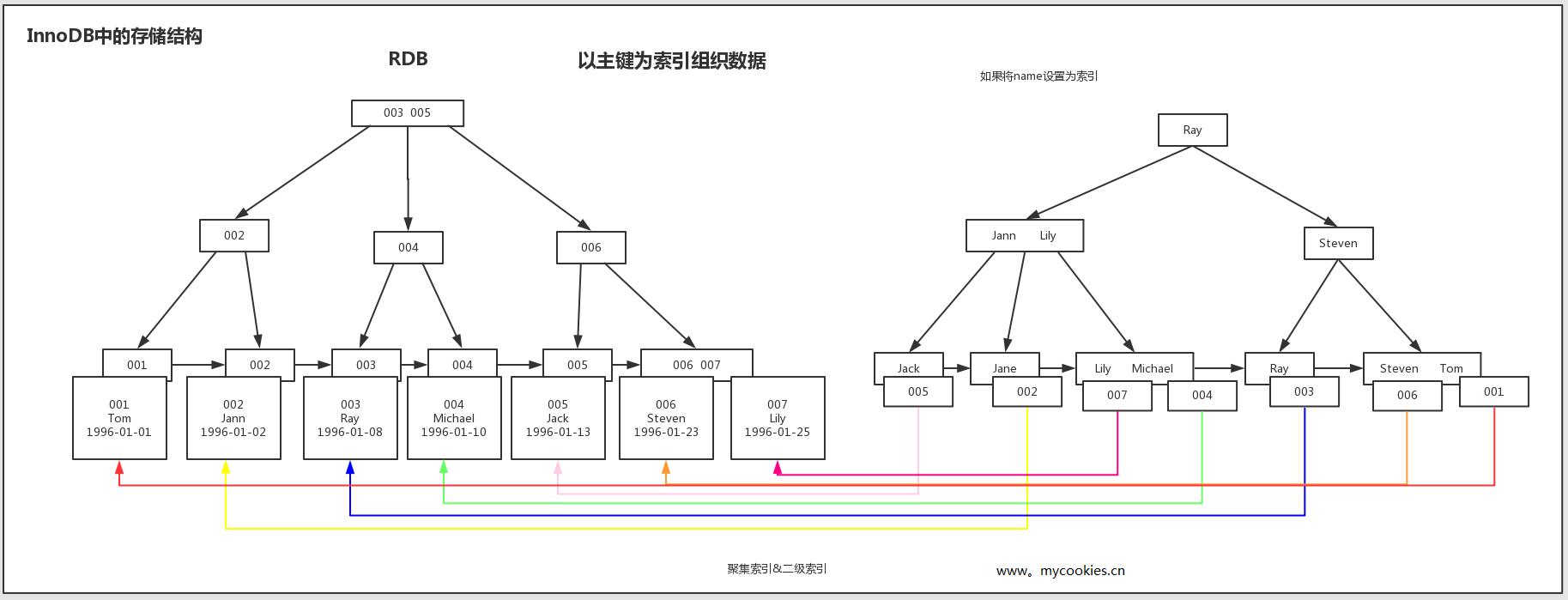
三、聚集索引以及辅组索引
mysql 是使用B+树作为数据结构索引,并且再数据的物理量顺序和索引的顺序使用了聚集索引,也就是叶子节点是存储数据信息,而辅组索引是存储聚集索引的索引项,找到索引项之后又要进行二次索引再一次进行查询
四、顺序主键的策略:
在InnoDB表中使用自增主键是既简单性能又高的策略,这样可以保证数据按顺序写入。最好避免随机的聚集索引,从性能的角度考虑,使用UUID来作为聚集索引是很糟糕的,这样不仅插入行花费的时间长,而且索引占用的空间也更大。
五、mysql索引IO操作
mysql索引采用的是b+树,一个节点是横向扩展关键字,而mysql默认一个节点存储16k的大小,那就是一次io操作读取一个节点也就是16k的数据到达内存中,而第一个非叶子节点是索引值以及索引值左右的指针,如果索引值是int类型也就是8B和指针6B 总14B 16k/14B 大概可以存储1170个关键词,而第二行具有1170个子节点,然后叶子节点是存储数据的,如果一行数据是1k大小那么可以存储16个,那么最多经过3次IO操作可以找到叶子节点的数据,并且这个数据结构可以存储1170*1170*16 大概2千万条数据 ,仅仅只需要执行3次IO的操作。
六、执行查询时什么情况下不用使用到索引
1. 列具有null ---> MySQL难以优化引用了可空列的查询,它会使索引、索引统计和值更加复杂。
2. 列重复值超过数据的20%不适合使用索引 ---> mysql具有优化 ,重复太多走索引的时间大于顺序查找
3. 复合索引的查找不符合最左侧原理 --> 也就是组合索引(a,b,c)如果不查询从where开始,a不是在最左的条件的话是不走索引的
4. or前后的列都要具有索引结构才会走索引
5. 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6. LIKE \'%abc\' | != | NULL 不走索引
7. 数据太少了,全表扫描更快
七、有关索引的相关sql命令
1. explain select 查询是否走索引
2. create index indexName on tablename (field) | (field1 ,fileld2)
3. 查看表中已经存在 index:show index from table_name;
以上是关于mysql的索引的学习的主要内容,如果未能解决你的问题,请参考以下文章