MySQL索引实践
Posted 心动如雷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引实践相关的知识,希望对你有一定的参考价值。
数据库索引本质上是一种数据结构(B+存储结构+算法),目的是为了加快数据检索速度。
1、索引的类型
主键索引:给表设置主键,这个表就拥有主键索引。
唯一索引:unique
普通索引:增加某个字段的索引,比如用户表根据用户名查询。
组合索引:使用多个字段创建索引,遵循最左原则,比如创建索引(col1 + col2 + col3),相当于创建了(col1)、(col1,col2)、(col,col2,col3)三个索引。
全文索引:
2、聚簇索引与非聚簇索引
mysql的InnoDB引擎主键使用的是聚簇索引;MyISAM引擎不管是主键索引,还是二级索引使用的都是非聚簇索引。
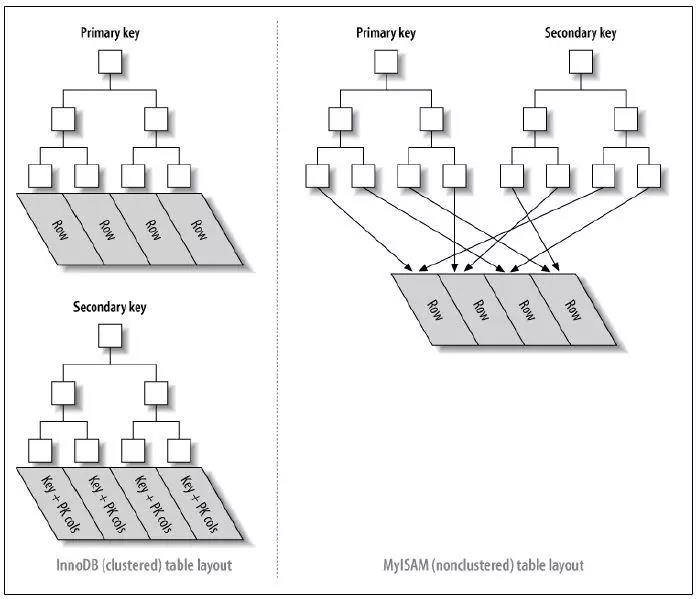
非聚簇索引(右图):数据和索引分开存储结构。
主键索引和二级索引存储上没有任何区别。
所有的节点都是索引,叶子节点存储数据(key)和数据地址。
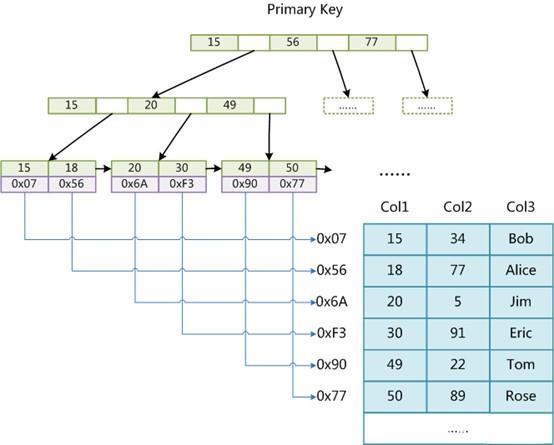
聚簇索引(左图):数据和索引一起存储结构,找到索引就找到数据。
主键索引的叶结点存储数据记录(包含主键值)。
二级(其他)索引的叶结点存储key值和对应数据记录的主键值。非叶子节点只存储索引(key)关键字,不存储对应数据记录的具体内容或内容地址。叶子节点上的数据是主键与具体记录(数据内容)。
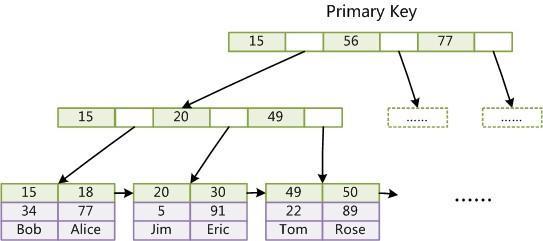
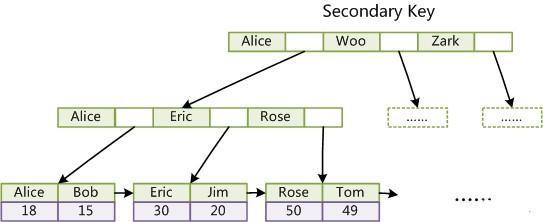
聚簇索引优点:
①如果需要查询一定范围内的数据,聚簇索引比非聚簇索引好。
②当通过聚簇索引查找目标数据时,理论上比非聚簇索引要快(因为非聚簇索引定位到对应主键后,还要多一次目标记录寻址,即多一次I/O)。
聚簇索引缺点:
①插入速度严重依赖于插入顺序,按照主键顺序插入是最快的方式;否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
②同时更新主键的代价很高,因为将会导致被更新的行数据移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
③二级(其他)索引访问需要两次索引查找,第一次找到数据记录主键值,第二次根据主键值在主键索引中检索数据记录。二级索引的叶节点存储的是主键值,而不是行指针(非聚簇索引存储的是指针或者说是地址),这是为了减少在出现行移动或数据页分裂时的二级索引的维护工作,但会让二级索引占用更多的空间。
④采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多(因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距:聚簇索引遍历所有的叶子节点;非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有数据记录,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
3、索引实践
#创建班级表
1 CREATE TABLE class ( 2 pid INTEGER not null AUTO_INCREMENT, 3 code VARCHAR(200) not null, 4 name VARCHAR(200) not null, 5 created_by VARCHAR(200), 6 created_date DATE, 7 updated_by VARCHAR(200), 8 updated_date DATE, 9 CONSTRAINT pk_class_pid PRIMARY KEY(pid) 10 );
#插入数据
insert into stu.class (code,name,created_by,created_date,updated_by,updated_date)
values
( \'1-001\', \'一年级1班\',\'system\', NOW(),\'system\',NOW()),
( \'1-002\', \'一年级2班\',\'system\', NOW(),\'system\',NOW()),
( \'2-001\', \'二年级1班\',\'system\', NOW(),\'system\',NOW()),
( \'2-002\', \'二年级2班\',\'system\', NOW(),\'system\',NOW());
#使用主键索引
EXPLAIN
select * from class where pid = 2;

#创建普通索引
CREATE INDEX idx_class_class_code ON class(class_code);
#使用索引
EXPLAIN
select * from class where code = \'2-001\';

IN查询:
EXPLAIN SELECT * FROM class WHERE code in (\'1-001\',\'1-002\',\'2-001\');

LIKE查询:
EXPLAIN SELECT * FROM class WHERE code like \'%-001%\'; #左右like

EXPLAIN
SELECT * FROM class WHERE code like \'%-001\'; #右like

EXPLAIN
SELECT * FROM class WHERE code like \'1-001%\'; #左like

创建组合索引
CREATE INDEX idx_class_class_code_name ON class(code,name);
#使用索引
EXPLAIN
select * from class where code = \'2-001\' and name = \'一年级2班\';
#使用索引,组合索引所有字段与顺序无关
EXPLAIN
select * from class where name = \'一年级2班\' and code = \'2-001\';

我自己想:应该是数据在执行时会进行SQL优化。
#组合索引只使用第一个字段时,索引可生效
EXPLAIN SELECT * FROM class WHERE code = \'1-001\';

EXPLAIN SELECT * FROM class WHERE name = \'一年级1班\';

查询时,组合索引中间有其他字段条件:
EXPLAIN SELECT * FROM class WHERE code = \'1-001\' and created_by = \'system\' and name = \'一年级1班\';

可以看到,此时查询时索引也生效了。
#删除索引
DROP INDEX idx_class_class_code ON class;
EXPLAIN
select * from class where code = \'2-001\';

#未使用索引,遵循最左原则
EXPLAIN
select * from class where name = \'一年级2班\';

#创建唯一索引
CREATE UNIQUE INDEX idx_uq_class_class_code ON class(code);
#删除已有的组合索引
DROP INDEX idx_class_class_code_name ON class;
#使用唯一索引
EXPLAIN
select * from class where code = \'2-001\';

以上是关于MySQL索引实践的主要内容,如果未能解决你的问题,请参考以下文章