声明:本文参考了淘宝/滴滴/美团发表的关于大数据平台建设的文章基础上予以整理。参考链接和作者在文末给出。
在此对三家公司的技术人员无私奉献精神表示感谢,如果文章造成了侵权行为,请联系本人删除。本人在尊重事实的基础上重新组织了语言和内容,旨在给读者揭开一个完善的大数据平台的组成和发展过程。
本文在未经本人允许情况下不得转载,否则追究版权责任。
By 大数据技术与架构
场景描述:希望本文对那些正在建设大数据平台的同学们有所启发。
关键词:大数据平台
大数据平台是为了计算,现今社会所产生的越来越大的数据量,以存储、运算、展现作为目的的平台。大数据技术是指从各种各样类型的数据中,快速获得有价值信息的能力。适用于大数据的技术,包括大规模并行处理(MPP)数据库,数据挖掘电网,分布式文件系统,分布式数据库,云计算平台,互联网,和可扩展的存储系统。
总结,大数据平台的出现伴随着业务的不断发展,数据的不断增长,数据需求的不断增加,数据分析及挖掘的场景而逐步形成。本文讲述淘宝、滴滴和美团三家互联网公司的大数据平台的发展历程,为大家提供建设大数据平台的基本思路。
淘宝
淘宝可能是中国互联网业界较早搭建了自己大数据平台的公司,下图是淘宝早期的Hadoop大数据平台,比较典型。
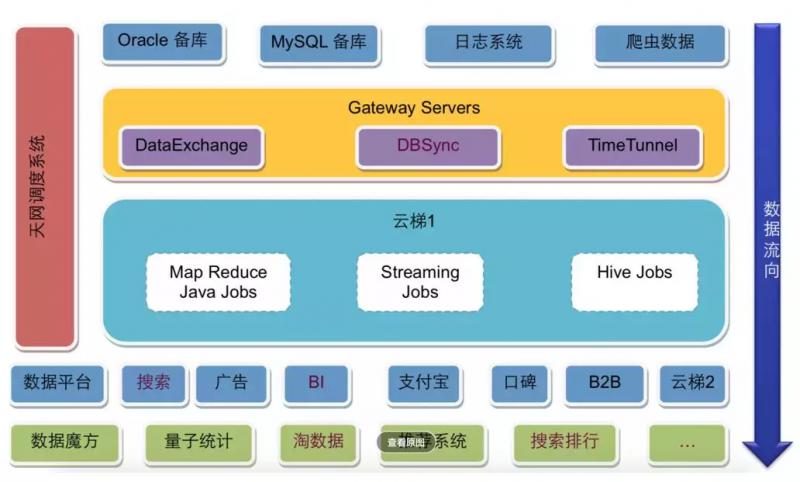
云梯数据仓库架构-图来源于《淘宝大数据平台之路》
淘宝的大数据平台基本也是分成三个部分,上面是数据源与数据同步;中间是云梯1,也就是淘宝的Hadoop大数据集群;下面是大数据的应用,使用大数据集群的计算结果。
数据源主要来自Oracle和mysql的备库,以及日志系统和爬虫系统,这些数据通过数据同步网关服务器导入到Hadoop集群中。其中DataExchange非实时全量同步数据库数据,DBSync实时同步数据库增量数据,TimeTunnel实时同步日志和爬虫数据。数据全部写入到HDFS中。
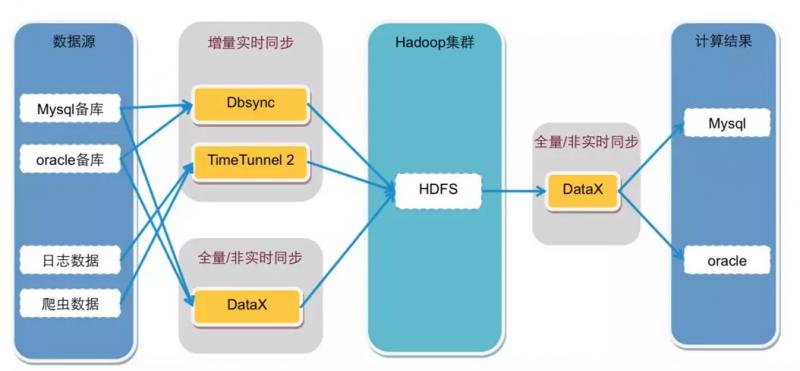
数据同步工具-图来源于《淘宝大数据平台之路》
在Hadoop中的计算任务会通过天网调度系统,根据集群资源和作业优先级,调度作业的提交和执行。计算结果写入到HDFS,再经过DataExchange同步到MySQL和Oracle数据库。处于平台下方的数据魔方、推荐系统等从数据库中读取数据,就可以实时响应用户的操作请求。
淘宝大数据平台的核心是位于架构图左侧的天网调度系统,提交到Hadoop集群上的任务需要按序按优先级调度执行,Hadoop集群上已经定义好的任务也需要调度执行,何时从数据库、日志、爬虫系统导入数据也需要调度执行,何时将Hadoop执行结果导出到应用系统的数据库,也需要调度执行。可以说,整个大数据平台都是在天网调度系统的统一规划和安排下进行运作的。
DBSync、TimeTunnel、DataExchange这些数据同步组件也是淘宝内部开发的,可以针对不同的数据源和同步需求进行数据导入导出。这些组件淘宝大都已经开源,我们可以参考使用。
滴滴
到目前为止大概经历了三个阶段,第一阶段是业务方自建小集群;第二阶段是集中式大集群、平台化;第三阶段是 SQL 化。
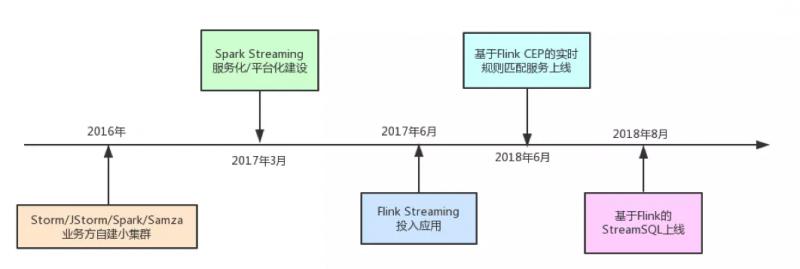
图来源于《滴滴大数据平台演进之路》
离线计算平台架构如下。滴滴的离线大数据平台是基于Hadoo 2(HDFS、Yarn、MapReduce)和Spark以及Hive构建,在此基础上开发了自己的调度系统和开发系统。调度系统和前面其他系统一样,调度大数据作业的优先级和执行顺序。开发平台是一个可视化的SQL编辑器,可以方便地查询表结构、开发SQL,并发布到大数据集群上。
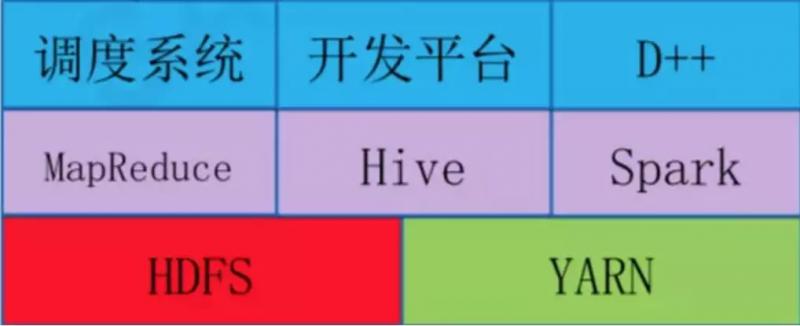
图来源于《滴滴大数据平台演进之路》
此外,滴滴还对HBase重度使用,并对相关产品(HBase、Phoenix)做了一些自定义的开发,维护着一个和实时、离线两个大数据平台同级别的HBase平台,它的架构图如下。
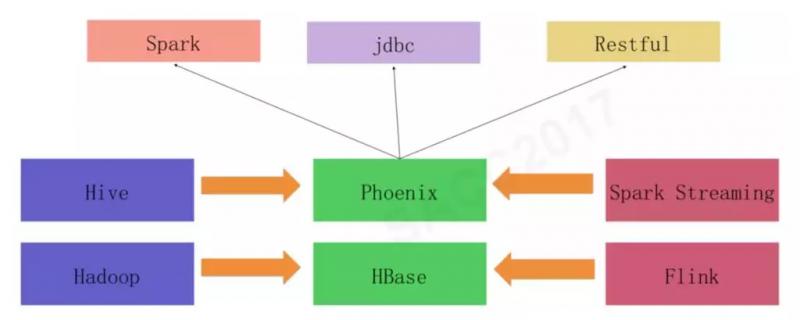
图来源于《滴滴大数据平台演进之路》
来自于实时计算平台和离线计算平台的计算结果被保存到HBase中,然后应用程序通过Phoenix访问HBase。而Phoenix是一个构建在HBase上的SQL引擎,可以通过SQL方式访问HBase上的数据。
为了最大程度方便业务方开发和管理流计算任务,滴滴构建了如下图所示的实时计算平台。在流计算引擎基础上提供了 StreamSQL IDE、监控报警、诊断体系、血缘关系、任务管控等能力。
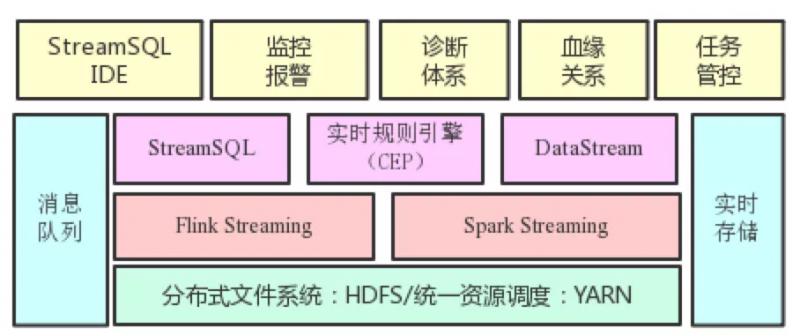
图来源于《滴滴大数据平台演进之路》
美团
我们以数据流的架构角度介绍一下整个美团数据平台的架构,大数据平台的数据源来自MySQL数据库和日志,数据库通过Canal获得MySQL的binlog,输出给消息队列Kafka,日志通过Flume也输出到Kafka,同时也会回流到ODPS。
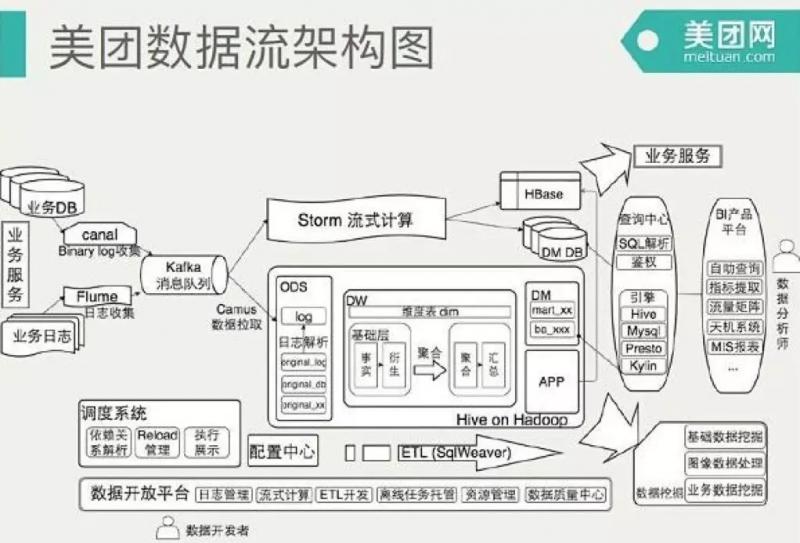
图来源于《美团大数据平台》
Kafka的数据会被流式计算和批处理计算两个引擎分别消费。流处理使用Storm进行计算,结果输出到HBase或者数据库。批处理计算使用Hive进行分析计算,结果输出到查询系统和BI(商业智能)平台。
数据分析师可以通过BI产品平台进行交互式的数据查询访问,也可以通过可视化的报表工具查看已经处理好的常用分析指标。公司高管也是通过这个平台上的天机系统查看公司主要业务指标和报表。
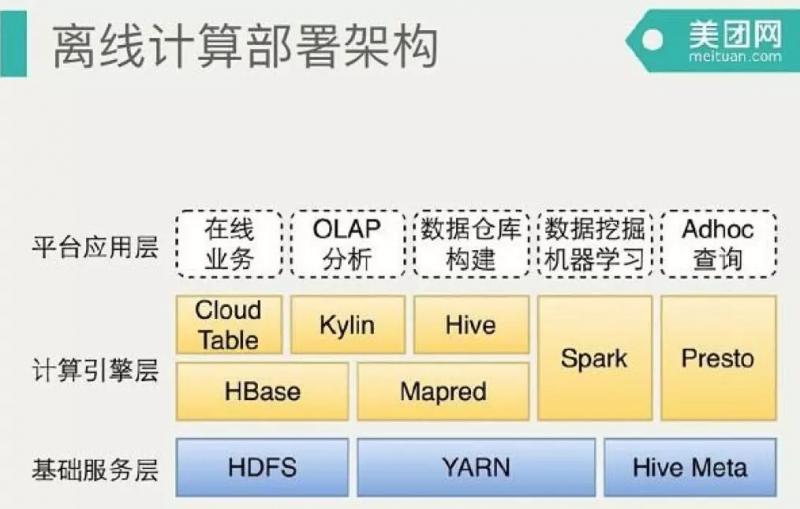
这幅图是离线数据平台的部署架构图,最下面是三个基础服务,包括Yarn、HDFS、HiveMeta。不同的计算场景提供不同的计算引擎支持。如果是新建的公司,其实这里是有一些架构选型的。Cloud Table是自己做的HBase分装封口。我们使用Hive构建数据仓库,用Spark在数据挖掘和机器学习,Presto支持Adhoc上查询,也可能写一些复杂的SQL。对应关系这里Presto没有部署到Yarn,跟Yarn是同步的,Spark 是 on Yarn跑。目前Hive还是依赖Mapreduce的,目前尝试着Hive on tez的测试和部署上线。
另外我们得知,在实时数仓的建设中,美团已经从原来的Storm迁移至Flink,Flink的API、容错机制与状态持久化机制都可以解决一部分使用Storm中遇到的问题。Flink不仅支持了大量常用的SQL语句,基本覆盖了常用开发场景。而且Flink的Table可以通过TableSchema进行管理,支持丰富的数据类型和数据结构以及数据源。可以很容易的和现有的元数据管理系统或配置管理系统结合。
美团大数据平台的整个过程管理通过调度平台进行管理。公司内部开发者使用数据开发平台访问大数据平台,进行ETL(数据提取、转换、装载)开发,提交任务作业并进行数据管理。
参考链接和作者:
威少Java
https://www.jianshu.com/p/58869272944b
淘宝大数据之路
http://www.raincent.com/content-85-7736-1.html
滴滴的大数据计算平台演进之路
https://blog.csdn.net/yulidrff/article/details/85680731
美团大数据平台
https://blog.csdn.net/love284969214/article/details/83652012

欢迎扫码关注我的公众号,回复【JAVAPDF】可以获得一份200页秋招面试题!