SQL——存储过程与函数
Posted the Secrets of Programming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL——存储过程与函数相关的知识,希望对你有一定的参考价值。
环境
DBMS:mysql 8.0.17
工具:Navicat Premium 11.2.16
存储过程
存储过程是由过程化SQL语言书写的过程,这个过程经编译和优化后存储在数据库服务器中,使用时调用即可。
优点:
- 运行效率高。提供了在服务器端快速执行SQL语句的有效途径。
- 降低了客户机和服务器之间的通信量。客户机上的应用程序只要通过网络向服务器发出调用存储过程的名字和参数,就可以执行其中的多条SQL语句并进行数据处理。只有最终的处理结果才返回客户端。
- 方便实施企业规则。可以把企业规则的运算程序写成存储过程放入数据库服务器中,既有利于集中控制,又能够方便地进行维护。当企业规则发生变化时只要修改存储过程即可,无须修改其他应用程序。
创建
CREATE PROCEDURE <存储过程名>([<参数模式> <参数名> <参数类型>]) BEGIN <SQL块> END;
存储过程的参数模式有3种:
- in:参数需要传入值。
- out:参数可以作为返回值。
- inout:参数既需要传入值,又可以作为返回值。
调用
CALL <存储过程名>([<参数>]);
若存储过程定义了参数,则在调用前需要先声明变量,然后在调用存储过程时传入变量。
定义一个可以根据学号查询学生信息的存储过程getStudentBySno,如果传入的sno为空,则取学号为201215121的学生信息:

声明用户变量sno:

调用存储过程getStudentBySno:

可以看到,传入的sno为空值,所以查询的是学号为201215121的学生信息。
也就是说,模式为in的参数能获取传入变量的值。
查看用户变量sno:
可以看到,虽然存储过程中改变参数sno的值,但并不影响传入的用户变量sno的值。
也就是说,作为模式为in的参数传入存储过程的变量,在调用存储过程后不会改变变量的值。
定义一个可以获取学生人数的存储过程getCount:
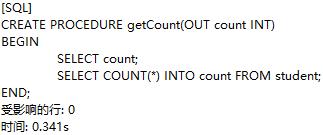
定义用户变量count:

调用存储过程getCount:


可以看到,用户变量的值并没有传入存储过程中。
也就是说,模式为out的参数不能获取传入变量的值。
查看用户变量count:

可以看到,count的值发生了改变。
也就是说,作为模式为out的参数传入存储过程的变量,在调用存储过程后会改变变量的值。
定义一个可以用于求传入值的平方的存储过程:
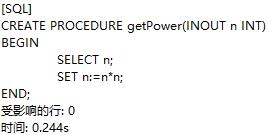
设置用户变量n:

调用存储过程getPower:

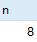
可以看到,用户变量的值传入了存储过程中。
也就是说,模式为inout的参数能获取传入变量的值。
查看用户变量n:

可以看到,n的值发生了改变。
也就是说,作为模式inout的参数传入存储过程的变量,在调用存储过程后会改变变量的值。
删除
DROP PROCEDURE <存储过程名>;
函数
函数与存储过程类似,都是由过程化SQL语言书写的过程,这个过程经编译和优化后存储在数据库服务器中。
与存储过程不同的是:
- 函数有1个返回值,存储过程没有返回值。
- 函数是通过select调用,存储过程是通过call调用。
函数可以分为两种:
- 单行函数:对应一个记录就会有一个返回值。
- 统计函数:对应多个记录有一个返回值。
内置函数
MySQL中有许多内置函数,可以在每个数据库中直接使用。
单行函数
数值相关
ceil(X):返回数值X上取整的结果。
floor(X):返回数值X下取整的结果。
round(X):返回数值X四舍五入后的整数结果。
round(X, D):返回数值X保留D位小数四舍五入后的结果。
字符串相关
concat(str1, str2, ...):返回拼接后的字符串。
instr(str, substr):返回substr在str中第一次出现的位置,如果没有出现则返回0。
length(str):返回str的字节个数。
lower(str):将str中的大写字母变为小写字母并返回。
lpad(str, len, padstr):若str的长度大于len,则截断后面的字符,保留前面len个字符并返回;若str的长度小于len,则在str前使用padstr填充直到长度为len并返回。
replace(str, from_str, to_str):将str中的from_str全部替换成to_str并返回。
rpad(str, len, padstr):若str的长度大于len,则截断前面的字符,保留后面len个字符并返回;若str的长度小于len,则在str后使用padstr填充直到长度为len并返回。
substr(str, pos, len):从第pos个字符开始截取str中之后的至多len个字符并返回。
trim(str):去掉str前后“ ”。
trim(remstr from str):去掉str前后的remstr。
upper(str):将str中的小写字母变为大写字母并返回。
日期时间相关
curdate():返回系统日期。
curtime():返回系统时间。
date_format(date, format):将日期按format进行格式化并返回。
datediff(expr1, expr2):返回expr1和expr2相差的天数。
now():返回系统日期时间。
str_to_date(str, format):将日期字符串按format进行解析并返回。
常用日期格式符号
| 格式 | 描述 |
| %Y | 年份(4位) |
| %y | 年份(2位) |
| %m | 月份(01-12) |
| %d | 天数(01-31) |
| %H | 时(00-23) |
| %i | 分(00-59) |
| %s | 秒(00-59) |
| %M | 月名 |
| %a | 缩写月名 |
| %W | 星期名 |
| %b | 缩写星期名 |
| %p | 上午、下午 |
| %h | 小时(01-12) |
| %T | 24小时制—hh:mm:ss |
| %r | 12小时制—hh:mm:ss AM|PM |
其他
database():返回当前数据库。
if(expr1, expr2, expr3):判断expr1,如果为真返回expr2,否则返回expr3。
ifnull(expr1, expr2):判断expr1是否为空值,如果是空值就返回expr2。
user():返回当前用户。
version():返回版本号。
统计函数
avg([DISTINCT ]expr):统计多个记录中指定字段的均值(不计空值)。只适用于数值类型的字段。distinct关键字用于去掉重复数据的记录。
count(*):统计记录数。
count([DISTINCT ]expr):统计多个记录中指定字段的值的个数(不计空值)。distinct关键字用于去掉重复数据的记录。
max(expr):统计多个记录中指定字段的最大值(不计空值)。
min(expr):统计多个记录中指定字段的最小值(不计空值)。
sum([DISTINCT ]expr):统计多个记录中指定字段的总和(不计空值)。只适用于数值类型的字段。distinct关键字用于去掉重复数据的记录。
创建
CREATE FUNCTION <函数名>([<参数名> <数据类型>]) RETURNS <数据类型> BEGIN <SQL块> RETURN <返回值>; END;
需要注意的有:
- MySQL中有一些内置函数,所以自定义函数的函数名不能与内置函数的函数名一致。
- SQL块中return后的返回值的数据类型必须与returns后定义的数据类型一致。
如果创建时出现以下报错信息:

解决方法是将全局变量log_bin_trust_function_creators置为ON:
SET @@global.log_bin_trust_function_creators=ON;
调用
SELECT <函数名>([<参数>]);
定义一个可以计算传入值的平方的函数:
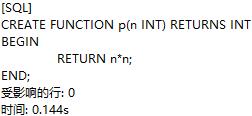
调用函数p:

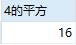
删除
DROP FUNCTION <函数名>;
以上是关于SQL——存储过程与函数的主要内容,如果未能解决你的问题,请参考以下文章