理解n-gram及神经网络语言模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解n-gram及神经网络语言模型相关的知识,希望对你有一定的参考价值。
参考技术A语言模型 定义了自然语言中标记序列的概率分布,简单的说就是定义了任何一个句子可能出现的概率,比如“小明吃了个苹果”每100个句子中就会出现1次,那它的概率就是 , 而"苹果吃了个小明"这个句子从古至今从来就不会有,那么就可以认为它的概率是 .
一般的,假设一个句子有一连串的词 组成,那么我们要怎么计算它在语言模型中的概率 呢?
最简单的想法就是我们构建一个巨大无比的语料库,把全人类从古至今讲过的话都放在里面,然后通过统计这句话出现的频率就可以了,但是显然是行不通的,我们没有这么大的语料库。
就算是有一个相对来说比较大的库,在其中的句子的概率相对来说还好算,只要频率除以总数就可以了,但是没有在这个库中的句子就会都变成0,显然这是不合理的。比如说在我们的库里,“小明吃了个苹果”概率0.01是可以理解的,但是“小明吃了个橘子”这句话并不在库里,那它的概率就应该为0吗?根据我们的直觉,“小明吃了个橘子”这个句子也是一个正常人类表达的句子,它不应该为0。
既然句子不行,那要不我们试试更细粒度的词汇,词汇在一个比较大的语料库中总归基本都是有出现的吧,于是我们可以定义一个条件概率:
观察上面的公式,前面的 还算比较好算,但是越后面...越没法算了....
这该如何是好?
于是有人就想出了 n-gram语言模型,它是最早成功的基于固定长度序列的标记模型。
它的思想来源于马尔可夫假设,它假设任意一个词 出现的概率只和它前面的 个词有关,而不是跟前面的所有词都有关,这样一来,前面的条件概率就变得简单了:
特别的,当n=1时称为 一元语法 (unigram),n=2时称为 二元语法 (bigram),n=3时称为 三元语法 (trigram),其中,三元语法是用的比较多的。显然,要训练 n-gram 语言模型是简单的,因为它的最大似然估计可以通过简单的统计每个可能的n-gram在语料库中出现的频率来获得。
通常我们同时训练n-gram模型和n-1 gram模型,这使得下面的式子可以简单的通过查找两个存储的概率来计算:
举个例子,我们演示一下三元模型是如何计算句子“苹果 吃了 个 小明”的概率的,套用上面的公式:
显然,n-gram模型的最大似然有一个基本限制,就是有可能在语料库中的统计数据 可能是 ,这将导致两种灾难性的后果。当 时,分母为0无法产生有意义输出,而当 时,测试样本的对数似然为 ,主要有两种方式来避免这种灾难性的后果:
n-gram模型特别容易引起维数灾难,因为存在 可能的n-gram,而 通常很大,即使有大量训练数据和适当的 ,大多数的n-gram也不会在训练集中出现。另外还有一个缺点就是模型词与词之间并没有什么关联,无法体现不同语义词汇之间的不同。
NNLM是一类用来克服位数灾难的语言模型,它使用词的分布式表示来对自然语言序列建模,其中词的分布式表示其实就是众所周知的 词向量 。
下面我们就来介绍一下NNLM的网络结构。
它的本质其实是一个前馈网络,就是用一个句子词序列 来预测下1个词(就记为 吧),因此它的输入是 , 标签是 ,模型训练的目的就是预测接近 分布的 ,因为输出层用的softmax激活,因此也可以理解成是输出 的概率分布。
下面,通过这个图,来看一下输入是怎么一步步到输出的。
是one-hot形式表示的词汇向量,它的维度等于总的词汇数。比如语料库只有4个词"小明","吃了", “个”,"苹果",那它们的one-hot向量就可以是4维向量:
总之就是词库有多少个不同的词, 就有几维,一般的词库而言可能会有几万维,然后每个次分别在自己的索引为为1,其余为0。
而look-up的作用就是要将one-hot的大维向量映射到一个分布式表示的相对低维的向量上,各自共享一个参数相同的全连接网络,通常会由200个左右的神经元,这里我们假设是 个,也就是从 维映射到 维:
这样的映射过程有 -1个,把 拼接在一起,就得到了一个 维的向量 ,然后继续往前传播,传到一个全连接的隐层,有h个神经元,并通过 激活,得到一个h维的向量:
之后就是输出层了,输出的虽然是一个和输入 一样的|V|维向量,但是这个输出层的连接比较特殊,并不是普通的全连接,它和隐藏层的输入和输出都有关系 , 就是词库中所有词的概率分布,然后用它和真实分布 计算交叉熵就是损失函数。
n-gram
n-gram
- 介绍语言模型
- 什么是N-gram模型
- N-Gram模型详解
- 应用n-gram模型语言来评估
- n-gram 模型其他应用举例
- 总结
介绍语言模型
什么是语言模型?简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否合理的概率?说说其应用,一直以来,如何让计算机可以理解我们人类的语言,都是人工智能领域的大问题。而机器翻译,问答系统,语音识别,分词,输入法,搜索引擎的自动补全等也都应用到了语言模型。当然,一开始人们都是进行基于规则的语言模型的研究,但这样往往有很大的问题,后来有人发明了基于统计的语言模型,并发现了其巨大的效果,而今天我们要讲的N-gram语言模型,也正是一种于基于统计的语言模型
N-gram语言模型可以说是当下应用最广的语言模型,当然了,随着深度学习的发展,现在也有用RNN/LSTM这样的神经网络语言模型,效果比N-gram有时候要更好一些,但RNN解码出每一个词都得现算语言模型分数,有较慢的劣势。
N-Gram模型详解
既然要做语言模型,基于统计概率来说,我们需要计算句子的概率大小:,这个也就是最终要求的一句话的概率了,概率大,说明更合理,概率小,说明不合理,不是人话。。。。
因为是不能直接计算,所以我们先应用条件概率得到
中间插入下条件概率: P(B|A):A 条件下 B 发生的概率。从一个大的空间进入到一个子空间(切片),计算在子空间中的占比。
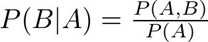
然而,如果直接算条件概率转化后的式子的话,对每个词要考虑它前面的所有词,这在实际中意义不大,显然并不好算。那这个时候我们可以添加什么假设来简化吗?可以的,我们可以基于马尔科夫假设来做简化。
什么是马尔科夫假设?
马尔科夫假设是指,每个词出现的概率只跟它前面的少数几个词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元模型。引入了马尔科夫假设的语言模型,也可以叫做马尔科夫模型。
马尔可夫链(Markov chain)为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备"无记忆"的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
也就是说,应用了这个假设表明了当前这个词仅仅跟前面几个有限的词相关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。即式子变成了这样:
注:这里的m表示前m个词相关
然后,我们就可以设置m=1,2,3,....得到相应的一元模型,二元模型,三元模型了,关于
当 m=1, 一个一元模型(unigram model)即为 :
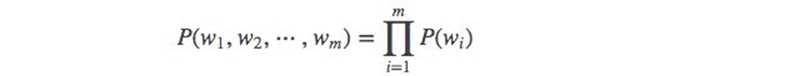
当 m=2, 一个二元模型(bigram model)即为 :
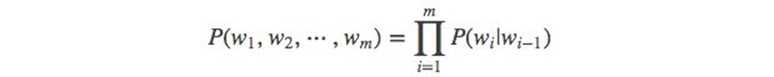
当 m=3, 一个三元模型(trigram model)即为
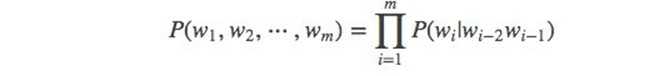
而N-Gram模型也就是这样,当m=1,叫1-gram或者unigram ;m=2,叫2-gram或者bigram ;当 m=3叫3-gram或者trigram ;当m=N时,就表示的是N-gram啦。
说明了什么是N-Gram模型之后,下面说说N-Gram经典应用,同时更深入的理解下:
利用N-Gram模型评估语句是否合理
假设现在有一个语料库,我们统计了下面的一些词出现的数量

下面的这些概率值作为已知条件:
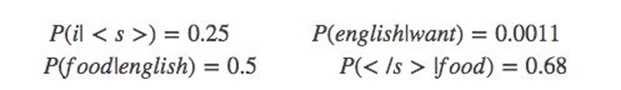
p(want|<s>) = 0.25
下面这个表给出的是基于Bigram模型进行计数之结果
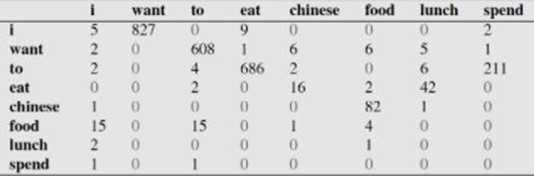
例如,其中第一行,第二列 表示给定前一个词是 "i" 时,当前词为"want"的情况一共出现了827次。据此,我们便可以算得相应的频率分布表如下。
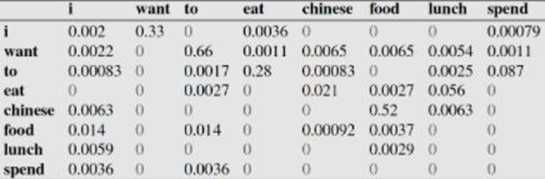
比如说,我们就以表中的p(eat|i)=0.0036这个概率值讲解,从表一得出"i"一共出现了2533次,而其后出现eat的次数一共有9次,p(eat|i)=p(eat,i)/p(i)=count(eat,i)/count(i)=9/2533 = 0.0036
下面我们通过基于这个语料库来判断s1="<s> i want english food</s>" 与s2 = "<s> want i english food</s>"哪个句子更合理:
首先来判断p(s1)
P(s1)=P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
再来求p(s2)?
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
通过比较我们可以明显发现0.00000002057<0.000031,也就是说s1= "i want english food</s>"更合理。
当然,以上是对于二元语言模型(bigram model)的,大家也可以算下三元,或者1元语言模型的概率,不过结果都应该是一样的,
再深层次的分析,我们可以发现这两个句子的概率的不同,主要是由于顺序i want还是want i的问题,根据我们的直觉和常用搭配语法,i want要比want i出现的几率要大很多。所以两者的差异,第一个概率大,第二个概率小,也就能说的通了。
注意,以上的例子来自:自然语言处理中的N-Gram模型详解 - 白马负金羁 - CSDN博客
n-gram 模型其他应用举例
n-gram模型也有其他很多应用,以下一一举例:
1.研究人类文明:n-gram模型催生了一门新学科(Culturomics)的成立,通过数字化的文本,来研究人类行为和文化趋势。《可视化未来》这本书有详细介绍,也可以通过知乎上的详细介绍,还有就是TED上的视频:what_we_learned_from_5_million_books 。
2.搜索引擎:当你在谷歌或者百度的时候,输入一个或几个词,搜索框通常会以下拉菜单的形式给出几个像下图一样的备选,这些备选其实是在猜想你想要搜索的那个词串。如下图:
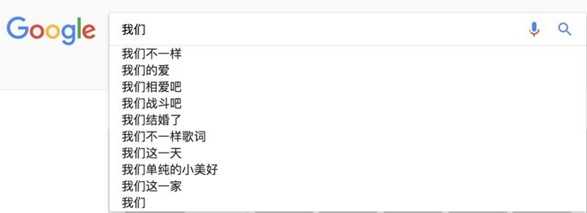
实际上这些都是根据语言模型得出。比如使用的是二元语言模型预测下一个单词:排序的过程就是:
p("不一样"|"我们")>p("的爱"|"我们")>p("相爱吧"|"我们")>.......>p("这一家"|"我们"),这些概率值的求法和上面提到的完全一样,数据的来源可以是用户搜索的log。
3.输入法:比如输入"zhongguo",可能的输出有:中国,种过,中过等等....这背后的技术就要用到n-gram语言模型了。item就是每一个拼音对应的可能的字。
.......(还有很多,只有有关语言模型,都可以应用)
总结
以上就是今天我们了解的所有内容了。当然,对于n-gram,我们可能需要知道语料库的规模越大,做出的n-gram对统计语言模型才更有用,或者n-gram的n大小对性能的影响也是很大的,比如n更大的时候对下一个词出现的约束性信息更多,有更大的辨别力,n更小的时候在训练语料库中出现的次数更多,有更高的可靠性 ,等等,这些有兴趣的童鞋就自己去查查吧,最后推荐一些书籍:
吴军. 2012. 《数学之美》.
关毅. 2007. 哈工大:统计自然语言处理.
fandywang, 2012,《NLP&统计语言模型》.
等等,都有对n-gram或者语言模型的讲述,值得一看的!
以上是关于理解n-gram及神经网络语言模型的主要内容,如果未能解决你的问题,请参考以下文章