『Rethinking the Inception Architecture for Computer Vision』论文笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『Rethinking the Inception Architecture for Computer Vision』论文笔记相关的知识,希望对你有一定的参考价值。
参考技术AInception系列的v1,v2读完了,该v3了,当年在渣浪做的视频推荐,提取视频特征的网络用的就是Inception v3。不过作者的标题没用v3,而是开始『Rethinking』了。
2018.12.29 2777次。和v1,v2完全不在一个量级上。
2015年12月刊发于arXiv。比后来横空出世的ResNet也就早了几天。一作回归到了v1的作者Christian Szegedy,v2的作者Sergey Ioffe这次是三作,看来两人好基友,每次都是组团出现
1 提出一些设计网络架构的通用准则
2 各种分解卷积的骚套路
本文探索了各种扩大网络的方式,目标是通过合适的卷积分解和有效的正则化来尽可能有效地利用所增加的计算。
相比VGG和AlexNet,Inception的计算量和参数量都大大降低,因此可以用于大数据和移动设备。不过,如果架构只是简单的缩放,大部分计算带来的收益可能会立即丢失。
本文将介绍一些通用的准则和优化理念用来更有效的扩大卷积网络。
作者反复强调以上只是部分经验,实际使用时需根据具体情况抉择。。
GoogLeNet最初的收益大多数来自广泛使用的降维。这可以被视为以一种更有效的计算来分解卷积的特例。
因为Inception网络是全卷积的,每个权重对应于每次激活的一次乘法,因此任何计算代价的减少也会引起总参数量的减少。这意味着可以通过合适的分解,得到更可分的参数并因此加速训练。
较大的filter(例如,5×5或7×7)在计算方面往往不成比例地昂贵。
用两个3x3卷积代替一个5x5卷积
做了控制实验证明这种策略有效。
很自然的想到能不能把3x3继续缩小为2x2,作为比较,将3x3分解为2个2x2只能节约11%的计算,不过用3x1和1x3能节约33%。
理论上,还可以更进一步,将nxn都用1xn和nx1来代替。实践发现这种分解在早期的层效果并不好,但在中间的层效果非常好(对于m x m的特征图,m在12到20之间)
Inception-v1中使用的辅助分类器最初动机就是为了克服深层网络中的梯度消失问题,将有用的梯度使浅层立即可以使用。不过,经实验发现,在训练早期这样并不能改进收敛,只是在训练后期,比没有辅助分类器的网络稍微好一点。这说明在Inception-v1中的假设是错误的(自己打自己脸,佩服,有勇气承认,没有混过去)
传统上,卷积网络通过池化操作来减小feature map的大小。为了避免表示性的bottleneck,在执行平均或最大池化前都会扩展filter的维度。
图9的左图虽然减小了网格尺寸,不过违反了通用原则1,过早的引入了bottleneck,右图倒是没违反,不过带来了3倍的计算量。
图10给出了解决办法,即引入两个并行的stride都为2的block:P和C,之后再联结起来。这样不仅代价更低而且避免了表示性的bottleneck。
(虽然这里是官方定义的v2,不过大家貌似都将BN-Inception认为是v2?)
把起初的7x7卷积分解为3个3x3卷积,用了不同结构的Inception块(图5,6,7),总共42层,计算代价只比v1高2.5倍。
提出了一种机制,通过估计训练期间标签丢失的边缘化效应来给分类层加正则。
分析了交叉熵损失过于自信导致过拟合的原因。提出一种机制鼓励模型减少这种自信。
对于标签为y的样本,将标签分布 替换为
在实验中,使用均匀分布 ,这样式子变为
称这种对真实标签分布的改变为标签平滑正则(label-smoothing regularization LSR)
另一种对LSR的解释是从交叉熵的角度出发
第二项损失惩罚了预测的标签分布p与先验u的偏差。这种偏差也可以通过KL散度等效地捕获,因为 ,而 是固定的。
在ILSVRC2012中,设置 , , 。带来了0.2%的提升。
用tensorflow训练了50个模型(这是Inception系列论文中第一次用tf),batch_size=32,epochs=100。起初的实验用带动量的SGD,decay=0.9。但是最佳的模型是RMSProp,decay=0.9, 。学习率用0.045,每2个epoch衰减(指数衰减率为0.94)。
另外,发现用RNN中的梯度裁剪(设置阈值为2.0)可以使训练稳定。
常识 是,采用更高分辨率感受野的模型往往会显著提高识别性能。如果我们只是改变输入的分辨率而不进一步调整模型,那么最后就是使用低计算量的模型来解决更困难的任务。
问题转化为:如果计算量是恒定的,更高的分辨率能有多少帮助?
尽管低分辨率的网络需要训练更久,但是最终的效果差不太多。然而,只是根据输入分辨率简单的减小网络的尺寸结果往往会很糟糕。
(这部分的结论是更高分辨率的输入用更复杂的模型?)
本文将使用了所有提升的Inception-v2综合体称为Inception-v3。
我屮,表4有bug,Top-5和Top-1的标题反了
提供了几条设计准则,基于此来扩大卷积网络。
感觉Inception结构太复杂了,充满了魔数,看起来没有ResNet那种统一的简洁美。另外,感觉这篇讲的有点散,有种拼凑感。。要不是Label smoothing提升的不是特别多,应该都能专门拿出来写一篇。最受用的是几点设计准则,应该会有助于理解后来出现的网络的设计理念。
栈爆上一个用pandas实现label smoothing的示例
pytorch的官方实现只有v3,没有其他的
花书的7.5.1节(向输出目标注入噪声)解释了label smoothing背后的原理。
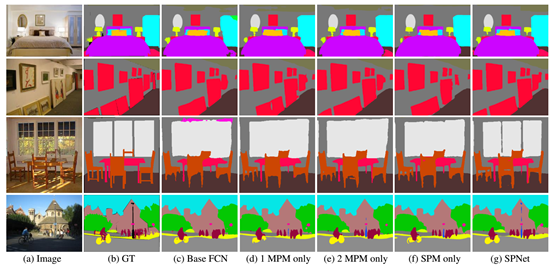
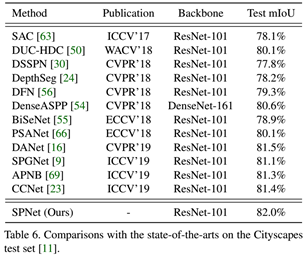
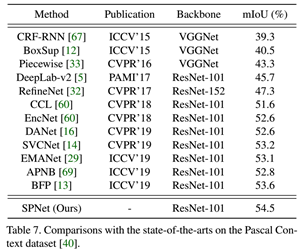
Rethinking场景分析中的空间池化 | Strip Pooling(CVPR2020,何恺明)
作者:Tom HardyDate:2020-04-04

以上是关于『Rethinking the Inception Architecture for Computer Vision』论文笔记的主要内容,如果未能解决你的问题,请参考以下文章