GBDT算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GBDT算法相关的知识,希望对你有一定的参考价值。
参考技术A对于AdaBoost,可以将其视为一个将多个弱分类器线性组合后对数据进行预测的算法,该模型可以表示为:
为基函数(即单个弱分类器), 为基函数的参数(即弱分类器中特征的权重向量), 为基函数的系数(即弱分类器在线性组合时的权重), 就是基函数的线性组合。
给定训练数据和损失函数 的条件下,构建最优加法模型 的问题等价于损失函数最小化:
这个公式展现了AdaBoost算法的核心过程。
我们可以利用前向分布算法来求解上一个式子的最优参数。前向分布算法的核心是 从前向后,每一步计算一个基函数及其系数,逐步逼近优化目标函数式 ,就可以简化优化的复杂度。
M-1个基函数的加法模型为:
M个基函数的加法模型:
由上面两式得:
由这个公式和公式(2)得极小化损失函数:
算法思路如下:
1. 初始化
2. 对m=1,2,...,M:
a. 极小化损失函数: 得到参数
b. 更新:
3. 得到加法模型:
这样,前向分布算法将同时求解从m=1到M所有参数 的优化问题化简为逐次求解各个 的优化问题。
Freidman提出了梯度提升算法,算法的核心是利用损失函数的负梯度将当前模型的值作为回归问题提升树算法中的残差的近似值,去拟合一个回归树。
GBDT的思想就是不断去拟合残差,使残差不断减少。用一个通俗的例子来讲假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。(参考 集成学习之Boosting-gbdt )GBDT中每次迭代构造的Cart树都是用前一轮的残差拟合的。
第t轮第i个样本的损失函数的负梯度表示为:
利用 我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域 其中J为叶子节点个数。
针对每一个叶子节点里的样本,我们求出使损失函数最小的 输出值 :
这样我们就得到了本轮的决策树拟合函数:
从而本轮最终得到的强学习器的表达式如下:
通过损失函数的负梯度来拟合,是一种通用的拟合损失误差的办法。无论是分类问题还是回归问题,我们都可以通过其损失函数的负梯度的拟合,从而用GBDT来解决我们的分类和回归问题。区别仅仅在于损失函数不同导致的负梯度不同而已。
d. 分位数损失:它对应的是分位数回归的损失函数。
输入: 训练样本
迭代次数(基学习器数量): T
损失函数: L
输出: 强学习器H(x)
算法流程
对于二元GBDT,其对数损失函数在之前已经给出:
其中 此时的负梯度误差为:
对于生成的决策树,各个叶子节点的最佳负梯度拟合值为:
由于这个式子不易优化,一般使用近似值代替:
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,二分类GBDT与GBDT回归算法过程相同。
多分类GBDT的损失函数在之前也已经给出过:
样本属于第k类的概率 的表达式为:
结合上面两个式子可以求出第t轮第i个样本对应类别 l 的负梯度误差为:
可以看出,其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。
对于生成的决策树,各个叶子节点的最佳负梯度拟合值为:
由于上式比较难优化,一般用近似值代替:
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,多分类GBDT与二分类GBDT以及GBDT回归算法过程相同。
为了防止GBDT过拟合,需要对其进行正则化。主要有三种方式:
1. 给每棵树的输出结果乘上一个步长(学习率) a 。之前的弱学习器的迭代式改为:
2. 通过子采样比例进行正则化。GBDT每一轮建树时样本从原始训练集中采用无放回随机抽样的方式产生。若采样比例取1,则采用全部样本进行训练。为了防止过拟合,同时又要防止样本拟合偏差较大(欠拟合),要合理取值,常用 [0.5, 0.8]
3. 对弱学习器(CART)进行正则化剪枝:控制树的最大深度、节点最少样本数、最大叶子节点数、节点分支的最小样本数等。
优点 :
缺点 :
由于弱学习器之间存在依赖关系,难以并行训练数据
boosting框架相关参数 :
弱学习器参数 :
GBDT的适用面非常广,几乎可以用于所有回归问题(线性/非线性),也可以用于分类问题。
MLlib--GBDT算法
转载请标明出处http://www.cnblogs.com/haozhengfei/p/8b9cb1875288d9f6cfc2f5a9b2f10eac.html
GBDT算法

1.决策树
1.1决策树的分类
| 决策树 | 分类决策树 | 用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。 |
| 回归决策树 | 预测实数值,如明天的温度、用户的年龄、网页的相关程度 |
| 强调:回归决策树的结果(数值)加减是有意义的,但是分类决策树是没有意义的,因为它是类别 |
1.2什么是回归决策树?
1.3回归决策树划分的原则_CART算法
2.GBDT算法_Boosting迭代
2.2图解Boosting迭代
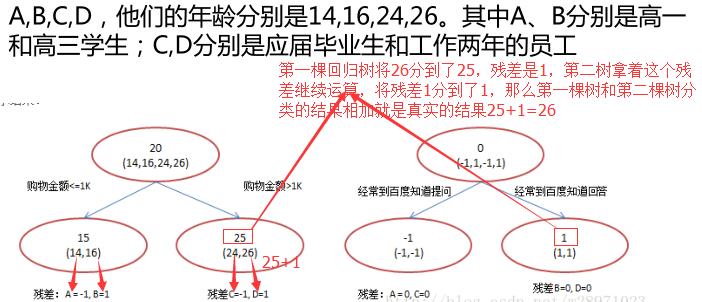
2.3GBDT算法_构建决策树的步骤
2.4GBDT和其他的比较
2.4.1GBDT和随机森林的比较
2.4.2GBDT和SVM
2.4.3如何用回归决策树来进行分类?
2.4.4数据处理--归一化
2.5回归决策树code


1 import org.apache.log4j.{Level, Logger} 2 import org.apache.spark.mllib.feature.{StandardScaler, StandardScalerModel} 3 import org.apache.spark.mllib.regression.LabeledPoint 4 import org.apache.spark.mllib.tree.{GradientBoostedTrees, DecisionTree} 5 import org.apache.spark.mllib.tree.configuration.{BoostingStrategy, Algo} 6 import org.apache.spark.mllib.tree.impurity.Entropy 7 import org.apache.spark.mllib.util.MLUtils 8 import org.apache.spark.rdd.RDD 9 import org.apache.spark.{SparkConf, SparkContext} 10 11 /** 12 * Created by hzf 13 */ 14 object GBDT_new { 15 // E:\\IDEA_Projects\\mlib\\data\\GBDT\\train E:\\IDEA_Projects\\mlib\\data\\GBDT\\train\\model 10 local 16 def main(args: Array[String]) { 17 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) 18 if (args.length < 4) { 19 System.err.println("Usage: DecisionTrees <inputPath> <modelPath> <maxDepth> <master> [<AppName>]") 20 System.err.println("eg: hdfs://192.168.57.104:8020/user/000000_0 10 0.1 spark://192.168.57.104:7077 DecisionTrees") 21 System.exit(1) 22 } 23 val appName = if (args.length > 4) args(4) else "DecisionTrees" 24 val conf = new SparkConf().setAppName(appName).setMaster(args(3)) 25 val sc = new SparkContext(conf) 26 27 val traindata: RDD[LabeledPoint] = MLUtils.loadLabeledPoints(sc, args(0)) 28 val features = traindata.map(_.features) 29 val scaler: StandardScalerModel = new StandardScaler(withMean = true, withStd = true).fit(features) 30 val train: RDD[LabeledPoint] = traindata.map(sample => { 31 val label = sample.label 32 val feature = scaler.transform(sample.features) 33 new LabeledPoint(label, feature) 34 }) 35 val splitRdd: Array[RDD[LabeledPoint]] = traindata.randomSplit(Array(1.0, 9.0)) 36 val testData: RDD[LabeledPoint] = splitRdd(0) 37 val realTrainData: RDD[LabeledPoint] = splitRdd(1) 38 39 val boostingStrategy: BoostingStrategy = BoostingStrategy.defaultParams("Classification") 40 boostingStrategy.setNumIterations(3) 41 boostingStrategy.treeStrategy.setNumClasses(2) 42 boostingStrategy.treeStrategy.setMaxDepth(args(2).toInt) 43 boostingStrategy.setLearningRate(0.8) 44 // boostingStrategy.treeStrategy.setCategoricalFeaturesInfo(Map[Int, Int]()) 45 val model = GradientBoostedTrees.train(realTrainData, boostingStrategy) 46 47 val labelAndPreds = testData.map(point => { 48 val prediction = model.predict(point.features) 49 (point.label, prediction) 50 }) 51 val acc = labelAndPreds.filter(r => r._1 == r._2).count.toDouble / testData.count() 52 53 println("Test Error = " + acc) 54 55 model.save(sc, args(1)) 56 } 57 }
E:\\IDEA_Projects\\mlib\\data\\GBDT\\train E:\\IDEA_Projects\\mlib\\data\\GBDT\\train\\model 10 local

以上是关于GBDT算法的主要内容,如果未能解决你的问题,请参考以下文章