OSS重磅推出OSS Select——使用SQL选取文件的内容免费公测中
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OSS重磅推出OSS Select——使用SQL选取文件的内容免费公测中相关的知识,希望对你有一定的参考价值。
摘要: OSS重磅推出OSS Select功能,可以直接使用简单的SQL语句,从OSS的文件中选取所需要的内容
对象存储OSS(Object Storage Service)具有海量、可靠、安全、高性能、低成本的特点。OSS提供标准、低频、归档类型,覆盖多种数据从热到冷的存储需求,单个文件的大小从1字节到48.8TB,可以存储的文件个数无限制。OSS已成为互联网、企业级数据应用的基础设施。
通常,获取对象存储数据的通方式为:获取整个对象,或按指定的字节范围来获取数据。今天,我们重磅推出OSS Select,直接使用简单的SQL语句,从OSS的文件中选取所需要的内容。
OSS Select介绍
使用SQL选取OSS文件中的内容
OSS Select(公测中)让开发者可以直接使用SQL语句,从OSS文件中选取需要的内容。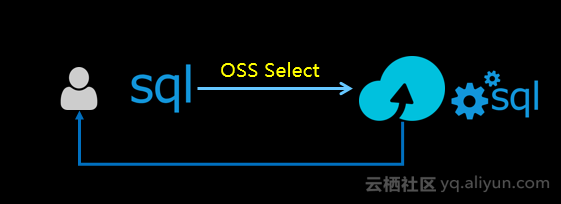
使用OSS Select,只获取应用程序所需的查询结果,并支持并发地分片查询,会大幅提升程序的性能,通常情况下能有400%的提升。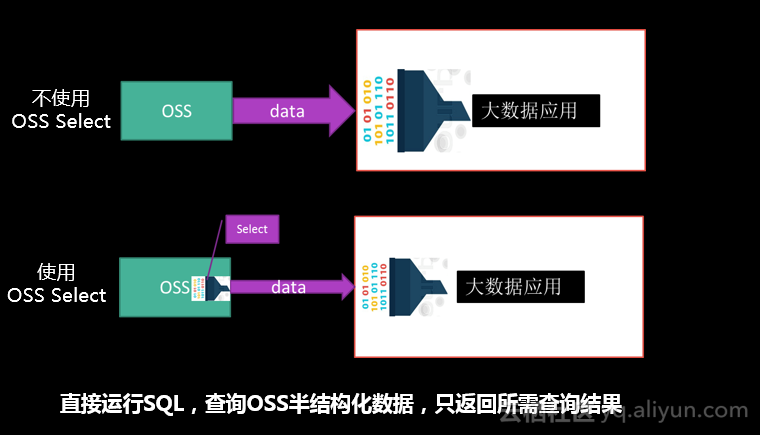
公测说明:
文件格式:公测期间支持未加密的CSV格式或者有分隔符的UTF8文本文件,参考RFC4180,
公测期间支持标准、低频类型的Object
支持RangeQuery(公测期间,RangeQuery模式下不支持Use Header Name)
OSS Select公测期间免费
后续阿里云EMR、DataLakeAnalytics、MaxCompute、HybridDB等都会陆续支持OSS Select
使用示例(python)
# -*- coding: utf-8 -*-import osimport oss2def select_call_back(consumed_bytes, total_bytes = None):
print('Consumed Bytes:' + str(consumed_bytes) + '\n')# 首先初始化AccessKeyId、AccessKeySecret、Endpoint等信息。# 通过环境变量获取,或者把诸如“<你的AccessKeyId>”替换成真实的AccessKeyId等。## 以杭州区域为例,Endpoint可以是:# http://oss-cn-hangzhou.aliyuncs.com# https://oss-cn-hangzhou.aliyuncs.com# 分别以HTTP、HTTPS协议访问。access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', '<你的AccessKeyId>')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', '<你的AccessKeySecret>')
bucket_name = os.getenv('OSS_TEST_BUCKET', '<你的Bucket>')
endpoint = os.getenv('OSS_TEST_ENDPOINT', '<你的访问域名>')# 确认上面的参数都填写正确了for param in (access_key_id, access_key_secret, bucket_name, endpoint): assert '<' not in param, '请设置参数:' + param# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)# csvfile = 'sample.csv'resultfilename = 'python_select.csv'csv_meta_params = {'FileHeaderInfo': 'None', 'RecordDelimiter': '\r\n'}# LineRange(可选参数):表示指定查询行的范围select_csv_params = {'FileHeaderInfo': 'None', 'LineRange':(100,1000)}
csv_header = bucket.get_csv_object_meta(key, csv_meta_params)# 将查询结果输出到文件result = bucket.select_csv_object_to_file(csvfile, resultfile,
"select _1, _3, _4 from ossobject where _4 > 40 and _1 like '%Tom%' ",
select_call_back, input_format)以上是一个简单的python示例,使用SQL查询OSS的对象,并将结果输出到文件汇总。
除了将查询结果输出到文件,还可以将查询结果直接返回
result = bucket.select_csv_object(csvfile, "select * from ossobject where _4 > 40 and _1 like '%Tom%' ", select_call_back, select_csv_params) content_got = b'' for chunk in result: content_got += chunk print(content_got)
查询结果:
测试示例
您可以使用OSS Select来加速您的各类应用。OSS Select团队,创建了一个Spark的示例,基于OSS Select,实现 Spark Data Source API。假设,您需要从大量的人员名单中,查询符合条件的人员信息。比如查询50岁以上,姓名中包含Tom的目标人员。
使用OSS Select提升应用程序性能
启用OSS Select,Spark借助OSS Select仅获取文件中所需要的数据;而禁用OSS Select,Spark获取整个文件
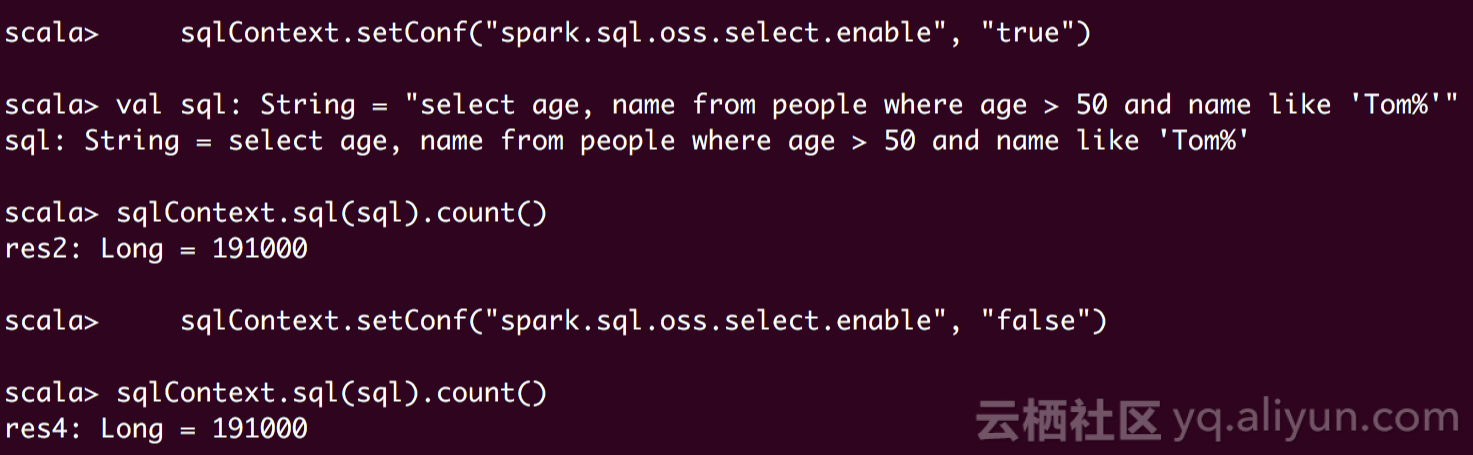
不使用OSS Select,查询需要78秒(1.3分钟)。而使用OSS Select,只需要11秒,程序性能提升6倍!

测试配置说明:
Spark测试集群配置:
| 数量 | 配置 | |
|---|---|---|
| master | 1 | 4core 8GB |
| workers | 2 | 4core 8GB |
Spark配置:
export SPARK_MASTER_IP=masterexport SPARK_WORKER_MEMORY=6gexport SPARK_WORKER_CORES=3export SPARK_WORKER_INSTANCES=1export SPARK_EXECUTOR_CORES=1export SPARK_EXECUTOR_MEMORY=2g
数据量:
CSV数据量为7GB。
以上是关于OSS重磅推出OSS Select——使用SQL选取文件的内容免费公测中的主要内容,如果未能解决你的问题,请参考以下文章