svm是一种典型的啥模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了svm是一种典型的啥模型相关的知识,希望对你有一定的参考价值。
参考技术Asvm是一种典型的二类分类模型。
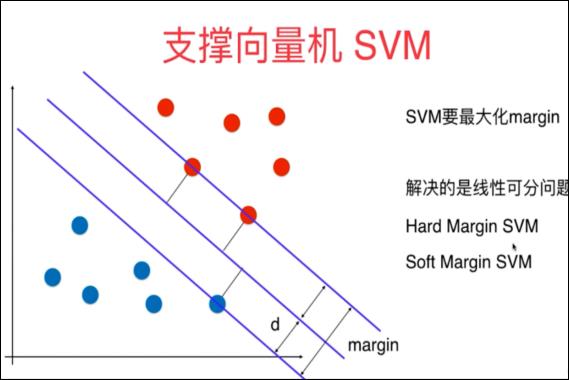
支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。
SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
支持向量机的优点和缺点:
1、由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
2、不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
3、拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
4、理论基础比较完善(例如神经网络就更像一个黑盒子)。
缺点:
1、二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数),因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)
2、只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题)。
机器学习笔记支持向量机(SVM)
(一)定义
支持向量机(Support vector machines ,SVM)顾名思义是支持向量和机,“支持量”是支持或支撑平面上把两类类别划分开来的向量点,“机”是机器学习领域里对一些算法的称呼。
SVM是一种二类分类的模型, 分别有线性分类和非线性分类两类模型。其中线性分类模型类似于感知机,但又有别于感知机,SVM通过支持向量间隔最大化使得其在线性分类场景下分类效果优于感知机,同时还能够支持近似线性分类的场景
注:1.线性可分,是针对训练数据、测试数据等待处理数据是线性可分的,通俗理解,一个平面上至少存在一条直线能够将数据分成两堆。如下图所示:
2.近似线性可分,是指一条直线能把绝大多数数据分成两堆,有少数在对方的那一堆里。如下图所示,在实线两侧有x跑到o里了,也有o跑到x里了。
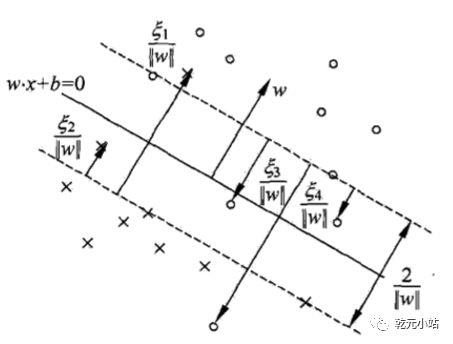
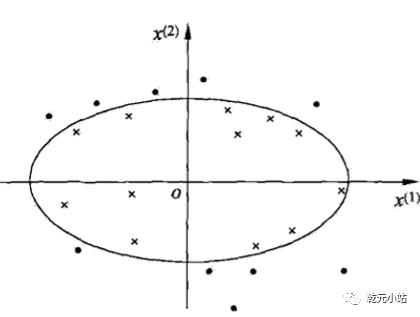
3. 线性不可分,通俗理解是不一个平上数据找不到一条直线将数据分成两堆,但数据又明显是两类。如下图所示:
本文着重讲线性可分情况的,其他 两种情况在后续文章中继续探讨,因此,下面所述“模型”,“策略”,“算法”都针对线性可分支持向量机。
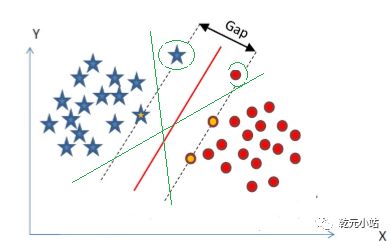
在感知机一文中我们知道,其本质是对线性可分训练数据通过寻找误分类最小的超平而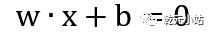 来实现,对数据的分类,实际上在空间这样的平面会有无穷多个,选择不同的w,b初值,不同的学习步长,不同的迭代顺序都会得到不同的w,b最终值,但都能达到将数据分类的目标。其缺点是这个计算得到的分类超平面对新输入数据(不是训练集合里的数据,这里顺首说一下,机器学习一般先拿一组已知数据用于训练得到模型,再用于对新输入的数据 时行运算)的预测能力不一定是最优的。如下 图所示,其中两条绿色的线都可以将已知的训练数据集准确的分开,但对地于由绿色线圈起来的新数据这两条绿线就会分别做出错误的判断。基于上述原因,SVM引入间隔最大化来进一步约束感知机的最终结果(间隔有函数间隔和几何间隔,自行脑补相关知识,笼统直观的可以理解为点到线或面的垂直距离),图中红线所代表的就是通过间隔最大化求得的分类超平而,可见他比绿线所代表的感知机方法所求的得分类超平面更优化。
来实现,对数据的分类,实际上在空间这样的平面会有无穷多个,选择不同的w,b初值,不同的学习步长,不同的迭代顺序都会得到不同的w,b最终值,但都能达到将数据分类的目标。其缺点是这个计算得到的分类超平面对新输入数据(不是训练集合里的数据,这里顺首说一下,机器学习一般先拿一组已知数据用于训练得到模型,再用于对新输入的数据 时行运算)的预测能力不一定是最优的。如下 图所示,其中两条绿色的线都可以将已知的训练数据集准确的分开,但对地于由绿色线圈起来的新数据这两条绿线就会分别做出错误的判断。基于上述原因,SVM引入间隔最大化来进一步约束感知机的最终结果(间隔有函数间隔和几何间隔,自行脑补相关知识,笼统直观的可以理解为点到线或面的垂直距离),图中红线所代表的就是通过间隔最大化求得的分类超平而,可见他比绿线所代表的感知机方法所求的得分类超平面更优化。
(二)模型
与感知机模型相同,
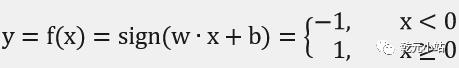
w叫作权值,b叫作偏置,表示w和x的内积,sign是符号函数
w,b取不同值形成不同的x到y的映射空间(函数的集合)
(三)策略
a.目标:确定经验损失函数并将损失函数最小化。
b. 经验损失函数可选择:
函数间隔:训练数据任意一点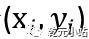 到所标识的超平面的函数间隔为
到所标识的超平面的函数间隔为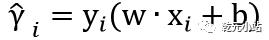 ,所有点到超平面函数间隔最小为
,所有点到超平面函数间隔最小为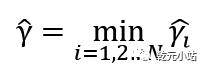
。
几何间隔:训练数据任意一点到所标识的超平面的几何 间隔为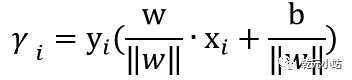 ,其中,||w||为w的L2范数,所有点到超平台几休间隔最小值为
,其中,||w||为w的L2范数,所有点到超平台几休间隔最小值为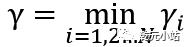 。
。
由此,策略:对已知训练数据集所有点求得几何间隔最大的超平而即为最优化分类,即满足上述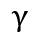 最大超平面。这块有点绕大家好好理解一下,通俗讲,对已知训练数据集有无穷多个w,b决定的超平面,对于每个超平面所有点到他的几何间隔都有个最小值,这些最小值中最大的那个超平面就是我们要的解。数学表示为:
最大超平面。这块有点绕大家好好理解一下,通俗讲,对已知训练数据集有无穷多个w,b决定的超平面,对于每个超平面所有点到他的几何间隔都有个最小值,这些最小值中最大的那个超平面就是我们要的解。数学表示为: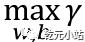 ,满足条件
,满足条件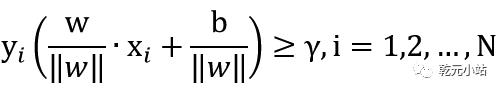 。
。
进一步推导:
根上述两个间隔的定义可见函数间隔和几何间隔之间是||w||倍数关系,代入可得
。
进一步等价推导:
考虑到函数间隔对上面的不等式成立条件不会有影响(把w,b成经例放大时,不会引起最小间隔数据点的变化)。所以函数间隔可直接取单位数值1
求最大等价求于最小(为了数据求解方便)
将上述两项等价替换得最终数学表达式为(即,SVM线性可策略):
(四)算法
至此,对于SVM的策略求解转化为纯数学问题求解,至于数学解的存在性不在计述范围呢。该数据问题为一个典型的凸二次规划问题,即约束最优化问题。其求解方法有原始和对偶两种算法,将在下一章中与实例一起介绍
以上是关于svm是一种典型的啥模型的主要内容,如果未能解决你的问题,请参考以下文章