正则提取中间的内容?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则提取中间的内容?相关的知识,希望对你有一定的参考价值。
现有一些这样的数据:
Dialogue: 0,0:07:57.64,0:07:59.23,Default9,,0,0,0,,文字1
Dialogue: 0,0:07:59.64,0:08:01.03,Default9,,0,0,0,,文字2
Dialogue: 0,0:08:01.44,0:08:02.13,Default9,,0,0,0,,文字3
Dialogue: 0,0:08:05.34,0:08:06.33,Default9,,0,0,0,,文字4
Dialogue: 0,0:08:06.34,0:08:07.43,Default9,,0,0,0,,文字5
Dialogue: 0,0:08:11.54,0:08:12.23,Default9,,0,0,0,,文字6
Dialogue: 0,0:08:40.06,0:08:41.03,Default9,,0,0,0,,文字7
Dialogue: 0,0:08:47.14,0:08:48.23,Default9,,0,0,0,,文字8
如何使用正则表达式,将其中的【Default9】取出来?【Default9】这个值不固定。
正则表达式是一种文本模式匹配工具,可以用来提取文本中的指定信息。如果你想使用正则表达式来提取上面的文本中的【Default9】,可以使用下面的正则表达式:

这个表达式会匹配文本中以 Dialogue: 开头,后面跟着任意字符,然后以一个逗号结尾的部分。它会提取括号中的内容,即【Default9】。
例如,在使用 Python 的 re 模块时,可以这样使用这个正则表达式:
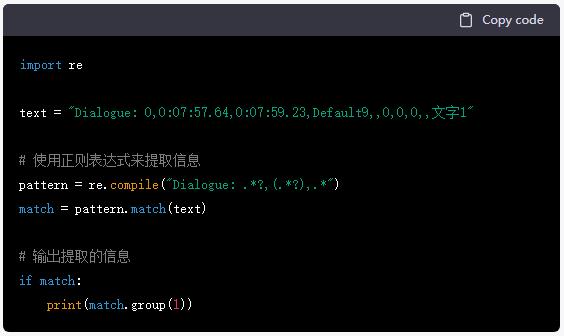
运行上面的代码,会输出:

请注意,这里的正则表达式并不能匹配所有情况,如果你想要更精确地匹配,可能需要修改正则表达式。
参考技术A
正则批量提取内容
参考技术B 可以使用下面的正则表达式来匹配您给定的数据中的【Default9】:\w+正则表达式中的\w是一个字符类,它匹配单词字符,包括字母数字字符和下划线。加号(+)修饰符表示匹配一个或多个单词字符。
因此,上面的正则表达式可以匹配【Default9】这样的一串字符。
下面是一个使用这个正则表达式来提取【Default9】的例子,其中使用了Python语言:import redata = "Dialogue: 0,0:07:57.64,0:07:59.23,Default9,,0,0,0,,文字1"
# 创建正则表达式模式
pattern = r"\w+"
# 使用模式去匹配数据
match = re.search(pattern, data)
# 输出匹配的结果print(match.group())
C# 正则表达式提取指定文本内的内容
直接上代码和如何使用
/// <summary>
/// 截取字符串中开始和结束字符串中间的字符串
/// </summary>
/// <param name="source">源字符串</param>
/// <param name="startStr">开始字符串</param>
/// <param name="endStr">结束字符串</param>
/// <returns>中间字符串</returns>
public string SubstringSingle(string source, string startStr, string endStr)
Regex rg = new Regex("(?<=(" + startStr + "))[.\\\\s\\\\S]*?(?=(" + endStr + "))", RegexOptions.Multiline | RegexOptions.Singleline);
return rg.Match(source).Value;
/// <summary>
/// (批量)截取字符串中开始和结束字符串中间的字符串
/// </summary>
/// <param name="source">源字符串</param>
/// <param name="startStr">开始字符串</param>
/// <param name="endStr">结束字符串</param>
/// <returns>中间字符串</returns>
public List<string> SubstringMultiple(string source, string startStr, string endStr)
Regex rg = new Regex("(?<=(" + startStr + "))[.\\\\s\\\\S]*?(?=(" + endStr + "))", RegexOptions.Multiline | RegexOptions.Singleline);
MatchCollection matches = rg.Matches(source);
List<string> resList=new List<string>();
foreach (Match item in matches)
resList.Add(item.Value);
return resList;
用法如下:
string html="这里 Html 文本内容省略";
var text1 = regex.SubstringSingle(html, "<div id=\\"pagelet_timeline_main_column\\">", "<div id=\\"pagelet_sidebar\\"");
var text2 = regex.SubstringMultiple(html, "<div class=\\"_4-u2 _4-u8\\">", "<div class=\\"_1dnh\\">");
具体去自己体会吧,个人觉得很实用,这里是写成了扩展方法来调用的。
/// <summary>
/// 去除转义字符
/// </summary>
/// <param name="str"></param>
/// <returns></returns>
public static string RemoveEscapeChar(this string str,int re=0)
if (string.IsNullOrWhiteSpace(str))
return "";
if (re == 1) //不替换特殊字符
return str;
if (re == 2) //不移除空格
return str.Replace("\\n", "").Replace("\\t", "").Replace("\\r", "");
return str.Replace("\\n", "").Replace("\\t", "").Replace("\\r", "").Replace(" ", "").Trim();
上面是去除页面中转义字符,换行符的一个扩展方法,去除后再配合正则来进行筛选很实用,我个人主要用在对请求得到的html 指定内容进行提取。
2020年1月15号补充:
在使用的过程中难免会遇到一些正则表达式的特殊符号例如下面这个文本
oL[289]( x[/42.934715] y[/31.199666] z[/-0.929894] u[/-0.20919151978424] v[/-0.04218084669353] w[/0.97696452557019] )
我们要提取出 [ ] 中的内容,那么在写的时候就要加上转义了,如下代码我分别提取文本中的x,y,z,u,v,w中的值 使用 \\\\ 进行特殊符号转义
string temp_x = SubstringSingle(str, "x\\\\[/", "\\\\]");
string temp_y = SubstringSingle(str, "y\\\\[/", "\\\\]");
string temp_z = SubstringSingle(str, "z\\\\[/", "\\\\]");
string temp_u = SubstringSingle(str, "u\\\\[/", "\\\\]");
string temp_v = SubstringSingle(str, "v\\\\[/", "\\\\]");
string temp_w = SubstringSingle(str, "w\\\\[/", "\\\\]");
这些就是需要注意的地方了,所以当你在提取时候如果有正则中特殊字符记得转义哈,不然会匹配不到的哦!
————————————————
版权声明:本文为CSDN博主「Syspan」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40729514/article/details/95986966
以上是关于正则提取中间的内容?的主要内容,如果未能解决你的问题,请参考以下文章