mysql+springboot+jpa查询几十万条数据很慢 如何解决?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql+springboot+jpa查询几十万条数据很慢 如何解决?相关的知识,希望对你有一定的参考价值。
数据库索引也加了 还是很慢

将查询语句放到服务器命令行去跑,如果慢,则可以考虑通过添加索引来提高查询速度。
如已有索引或添加索引后查询速度仍未改善,查看语句执行计划中,是全表扫描还是走索引。如果走了索引,那就可能考虑是服务器性能瓶颈或数据库设置问题,涉及的设置项比较多,你没有提供相关信息,无法继续提供优化建议。如果没有走索引,检查语法(查询条件添加函数不走索引)和表属性(关联表字符集不统一不走索引)。
如果服务器本地快,但页面查询慢,那就排除了性能问题,考虑网络问题与页面查询语句调用的驱动模块是否有问题。检测网络连接速度,如慢尝试更换网线。网络连接速度正常,则尝试更换调用的驱动包,重新下一个或换一个版本。
mysql支持几十万的数据,响应速度应该是毫秒级的。
看了下你的语句,不要用IN了,改INNER JOIN吧,套那么多层IN,肯定没效率。
追问内连接 左连接 右连接 都用了 都很慢 38w数据 都是在3-6s 的样子返回
追答你还是优先看一下执行计划有没有走索引,然后发一下你内连接的语句,我看下语法是否合适。
追问

语法没有问题,执行计划可以贴一下吗?主要是检查索引,每张表都建了索引吗?执行的时候,有没有走索引?你可以检查一下参与关联的4张表是否采用了同一字符集(同为latin或uft8)
如果字符集、索引确实都正确了,把order by子句去掉,不排序,看一下响应时间是多少。
回到你最初的问题:如果你加了索引之后和加索引之前完全没有体会到变化的话,那执行计划多半就没有走索引,索引的添加方式或者字符集有问题。
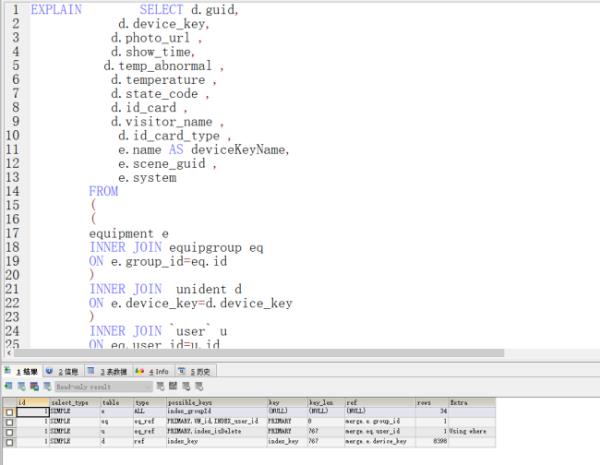
看私信
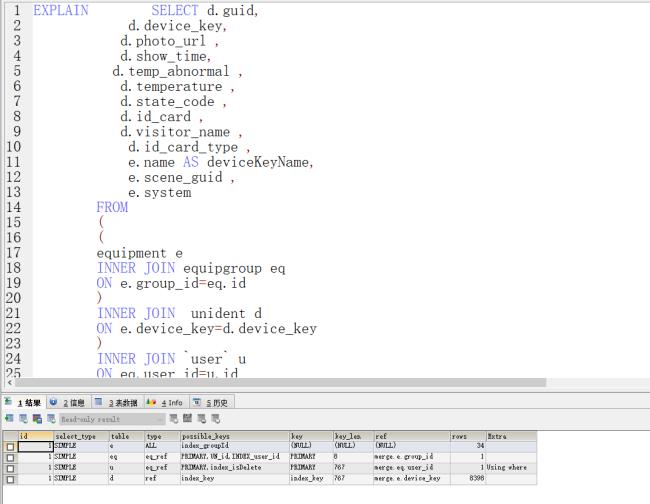
执行计划也没有问题。
执行计划中,eq、d、u三表都走了eq_ref或ref方式,但是主表e表却是走的ALL方式,全表扫描,说明没有走索引,这可能是因为你在执行语句的时候where子句,所以没走索引,这也是正常的。
字符集确认过了吗?如果这些都没问题,以我的水平也帮不上更多了,再找别人问问吧。抱歉没有帮到你。

总觉得索引有问题 d 加个条件 变成了 ALL

查看d表的表设置字符集,及该字段设置的字符集
如果建了索引,但是加条件不走字符集而走全表扫描,第一件事检查字符集
还有,d表的where条件不要写在最后,而是写在on条件内,可以减少JOIN数据集的量,从而从根本上减少I/O的量
join d
on e.col_a=d.col_a and d.col_b='xxx'
说明:e表10万,d表10万,e join d on e.col_a=d.col_a where d.col_b='xxx',就是10万对10万关联后取满足col_b条件的数据量
e join d on e.col_a=d.col_a and d.col_b='xxx',就是10万对满足col_b条件的数据量的关联
两者I/O的差别,明白的吧?
spring boot 应用程序:jpa 查询返回旧数据
【中文标题】spring boot 应用程序:jpa 查询返回旧数据【英文标题】:spring boot application: jpa query returning old data 【发布时间】:2016-12-19 18:44:14 【问题描述】:我们创建了一个使用 1.3.5 版本的 spring boot 项目。我们的应用程序与 Mysql 数据库交互。 我们创建了一组 jpa 存储库,我们在其中使用 findAll、findOne 和其他自定义查询方法。
我们正面临一个随机发生的问题。以下是重现它的步骤:
使用 spring-boot 应用程序在 db 上触发读取查询。
现在使用上面读取查询返回的记录的mysql-console手动更改Mysql中的数据。
再次使用应用程序触发相同的读取查询。
在第3步之后,我们应该已经收到了第2步的修改结果,但我们得到的是修改前的数据。
现在,如果我们再次使用应用程序触发读取查询,它会为我们提供正确的值。
此问题随机发生。我们没有在我们的应用程序中使用任何类型的缓存。
调试的时候发现jpa-repository代码实际上是在调用mysql,它也获取了最新的结果,但是当这个调用返回到我们的应用服务时,奇怪的是返回值有旧数据。
请帮助我们找出可能的原因。
JPA/数据源配置:
spring.datasource.driverClassName=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/dbname?autoReconnect=true spring.datasource.username=root spring.datasource.password=xxx spring.jpa.database-platform=org.hibernate.dialect.MySQL5Dialect spring.datasource.max-wait=15000 spring.datasource.max-active=100 spring.datasource.max-idle=20 spring.datasource.test-on-borrow=true spring.datasource.remove-abandoned=true spring.datasource.remove-abandoned-timeout=300 spring.datasource.default-auto-commit=false spring.datasource.validation-query=SELECT 1 spring.datasource.validation-interval=30000 hibernate.dialect=org.hibernate.dialect.MySQL5Dialect hibernate.show_sql=false hibernate.hbm2ddl.auto=update服务方式:
@Override
@Transactional
public List<Event> getAllEvent()
return eventRepository.findAll();
JPARepository:
public interface EventRepository extends JpaRepository<Event, Long>
List<Event> findAll();
【问题讨论】:
你在打电话给 COMMIT; 吗?向我们展示您的更新查询和数据源以及 JPA 配置 Hitham,我已经更新了相关的详细信息。更新查询只是改变一个 varchar 属性列的值。 鉴于您正在更改 Hibernate 背后的值,陈旧的值是否来自其一级缓存? @Andy,但是这两个事务是完全独立的,对应两个不同的线程。 您是如何验证的? minimal, complete, verifiable example 会让人们更容易看到正在发生的事情。 【参考方案1】:你可以使用:
@Autowired
private EntityManager entityManager;
然后在再次查询同一个实体之前:
entityManager.clear();
然后调用查询
【讨论】:
【参考方案2】:这可能是因为一些“脏读”。遇到类似的问题,尝试使用事务锁,尤其是“可重复读取”,这可能会避免这个问题。如果我错了,请纠正我。
【讨论】:
【参考方案3】:@Cacheable(false)
示例:
@Entity
@Table(name="table_name")
@Cacheable(false)
public class EntityName
// ...
【讨论】:
在我的情况下,我在控制器@Cacheable(cacheNames = AppCacheManager.DEFAULT_CACHE) 上有注释需要找到缓存的替代方案以上是关于mysql+springboot+jpa查询几十万条数据很慢 如何解决?的主要内容,如果未能解决你的问题,请参考以下文章