python读入一个txt并将其中的数据按行依次保存成若干个txt文本并以每一行的前4个字符作为新txt的文件名。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python读入一个txt并将其中的数据按行依次保存成若干个txt文本并以每一行的前4个字符作为新txt的文件名。相关的知识,希望对你有一定的参考价值。
刚开始学,碰上问题了,求解惑。
readline读取行,切片[:4]读取命名,读文件用w模式新建 参考技术A >>> f=open('E:\\123.txt','r')>>> f1=f.readlines()
>>> for i in f1:
p='E:\\%s.txt'%(i[0:4])
with open(p,'w')as a:
a.write(i)
11
12
13
14
8
>>>
python读入txt数据,并转成矩阵
比如有一个txt文件,里面的内容长这样:
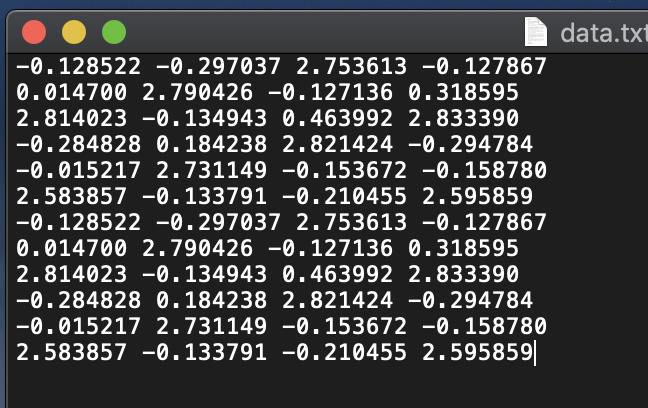
如何用Python读取这些数据?
方法一:用np.loadtxt函数

程序:
data = np.loadtxt(\'data.txt\', dtype=np.float32, delimiter=\' \')
方法二:自定义数据读取函数
程序:
import numpy as np
def file2array(path, delimiter=\' \'): # delimiter是数据分隔符
fp = open(path, \'r\', encoding=\'utf-8\')
string = fp.read() # string是一行字符串,该字符串包含文件所有内容
fp.close()
row_list = string.splitlines() # splitlines默认参数是‘\\n’
data_list = [[float(i) for i in row.strip().split(delimiter)] for row in row_list]
return np.array(data_list)
data = file2array(\'./data.txt\')
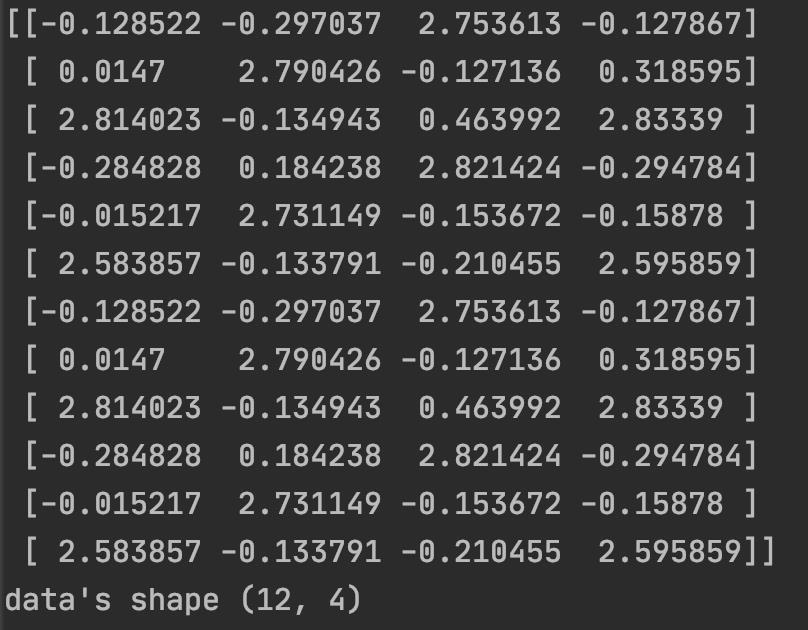
print(data)
print("data\'s shape", data.shape)
运行结果:
以上是关于python读入一个txt并将其中的数据按行依次保存成若干个txt文本并以每一行的前4个字符作为新txt的文件名。的主要内容,如果未能解决你的问题,请参考以下文章