二十Hadoop学记笔记————Hive复习与深入
Posted liuxiaopang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二十Hadoop学记笔记————Hive复习与深入相关的知识,希望对你有一定的参考价值。
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序
Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HDFS中。
此元数据与HDFS中的元数据需要区分清楚,HDFS中元数据(文件名,文件长度等)存于Namenode中,数据存于Datanode中。
本次使用的是hive1.2.2版本

下载完毕之后解压:
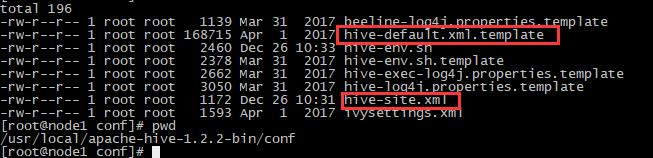
将default文件复制一份成site文件,然后打开site文件,清空其内容,然后配置如下参数:

hive.metastore.local表示元数据存于本地
其中jdbc的hive是mysql中,提供给hive的database的名称,可自行修改,后续是登录的账号和密码,可以使用root,也可以新建一个hive用户,本机采用的是新建一个hive用户。
之后将mysql的jdbc驱动放入hive的lib目录下:

之后安装mysql,并在mysql下create名为hive的数据库,本机使用mysql5.7,数据库安装不做描述:
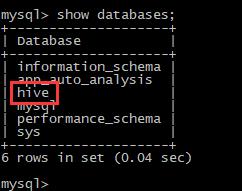
在hive中新建的表的表结构会在mysql中相应的databse内存储:



之后在例举一个复杂点的数据表,主要包含了数组型字段和map型字段,并且附带partition分区,例子来源于hive官网:
CREATE TABLE user_info(
id INT,
name STRING,
hobby ARRAY < STRING >,
goodatlol MAP < STRING, STRING >
)
PARTITIONED BY(dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY \'\\t\'
COLLECTION ITEMS TERMINATED BY \',\'
MAP KEYS TERMINATED BY \':\'
STORED AS TEXTFILE;
先新建一个user_info表:

其中hobby为数组型字段,goodatlol为map型字段。fields的分隔符\'\\t\'表示文件每一行的分隔符,collection的分隔符\',\'表示数组型字段的分隔符,map的分隔符\':\'表示map字段的分隔符。
这时候在hdfs的该路径下回出现一个文件夹user_info:

由此可见,hive中的数据表,表结构的元数据存在所连接的关系型数据库中,而数据信息存于hdfs。
之后录入信息,新建文件,名字不限,内容如下:

load data local inpath \'/home/tyx/temp/userinfo\' into table user_info;

可用查询语句得出ttt同学喜欢上单风男:

之后在hdfs的user_info路径下还会出现分区:

前面讲述的是建表和查询,现在说一个插入比较常用的方法,由于Hive是数据仓库,主要作用是用来存放、查询和统计数据,因此插入一般是直接覆盖,而不会像Mysql那样经常一条一条的插入。在Hive中,Insert into默认是关闭的,需要做一些配置才能开启,感兴趣的朋友可以自行查询,此处只介绍insert overwrite方法,标准语法如下(源自官方文档):
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
意思就是从一个语句中读取所有数据并覆盖原数据。前面也提到Hive一般用来做统计查询,通常情况下统计所需要的字段可能分布在好几张数据表上。就算只存在于一张数据表,那统计所需要的字段也只有2到3个,新建一个表专门用来查询也可以提高查询效率。
新建一个user_test表:
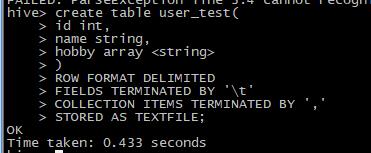
这个表相较于user_info表没有goodatlol字段和partition分区。
然后使用insert overwrite语句,将user_info中的id,name和hobby插入到user_test中来。
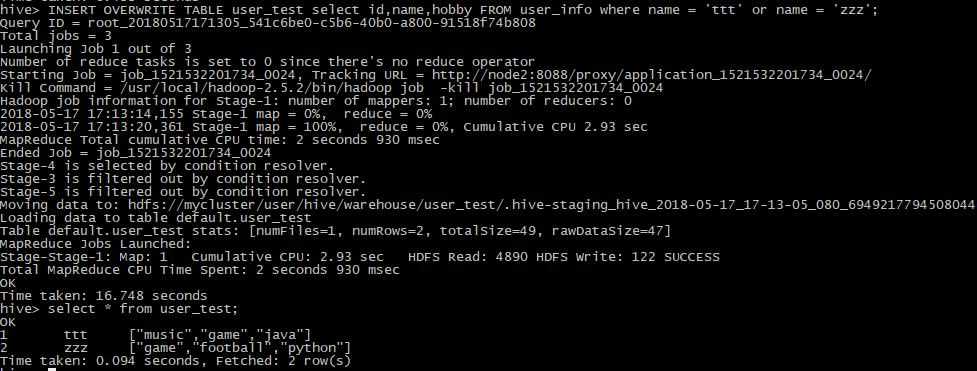
可以看到这时user_info中的name为ttt和zzz的数据都已经插入到了表user_info中,这时在该表中进行统计查询效率会比在user_info中快。
该语句在下面场景会非常实用,比如一个表A很很多字段,其中1号程序员需要用到A中的1、2、3字段做统计分析,程序员2号需要用到A中的3、6、8字段做统计分析,那么1号和2号分别都键自己的统计表会更加有效率
以上是关于二十Hadoop学记笔记————Hive复习与深入的主要内容,如果未能解决你的问题,请参考以下文章