利用flask和gevent怎样实现长连接
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用flask和gevent怎样实现长连接相关的知识,希望对你有一定的参考价值。
参考技术A 我的一点理解实现long polling主要有两个方面。第一个是客户端的持续查询请求,另一个是服务器的非阻塞IO处理。客户端向服务器请求数据刷新,在数据就绪之前服务器保持这个连接不断开。数据写入后连接断开,客户端处理数据,然后重新向服务器建立连接请求数据。周而复始。如何通过gevent使用Flask(uWSGI 和Gunicorn 版本)
免责声明: 我写这篇教程是因为gevent在几年前挽救了我们的项目,我仍然在我的博客上看到稳定的gevent相关的搜索流量。因此,gevent帮助我们的方式可能对其他人也有用。因为我还有一些有用的知识,所以我决定把如何设置它记录下来。然而,我不建议你在2020年使用这项技术开始你的新项目。依我之见,它老了,失去了吸引力。
题外话: 请在GitHub上查看代码例子。
Python正在蓬勃发展,而Flask现在是一个非常流行的web框架。可能,相当多的新项目正在从Flask中启动。但是人们应该意识到,它在设计上是同步的,而ASGI还不成熟。因此,如果有一天你意识到你的项目确实需要异步I/O,但是你已经在Flask顶端有了相当多的代码库,那么本教程就是为你准备的。迷人的gevent库将使你能够继续使用Flask,同时开始受益于所有的I/O是异步的。在本教程中我们将看到:
如何对一个Flask应用程序应用猴子补丁,使其变成异步而不改变其代码。
如何使用gevent.pywsgi应用服务器运行打了补丁的应用程序。
如何使用Gunicorn应用服务器运行打了补丁的应用程序。
如何使用uWSGI应用服务器运行打了补丁的应用程序。
如何在应用服务器前端配置Nginx代理。
[福利]如何通过psycogreen使用psycopg2来使PostgreSQL访问成为非阻塞。
我什么时候需要异步 I/O
答案可能有些幼稚——当应用程序的工作负载是I/O密集型时你需要它,即由于与外部服务的过度通信,它在延迟SLI上达到最大。由于微服务体系架构和各种第三方API的广泛应用,这种情况在现在非常普遍。如果你的应用程序中的一个普通HTTP处理程序需要创建10多个网络请求来构建一个响应,那么你很可能会从异步I/O中获益。另一方面,如果你的应用程序消耗了100%的CPU或RAM处理请求,那么迁移到异步I/O可能没有帮助。
什么是gevent
来自官方网站的描述:
gevent是一个基于协程的Python网络库,它使用greenlet在libev或libuv事件循环之上提供一个高级的同步API。
对于那些不熟悉上述像greenlet、libev或libuv依赖项的人来说,这个描述是相当模糊的。你可以查看我之前尝试简要解释这个库的本质的文章,其中最重要的是,它允许你对普通的Python代码应用猴子补丁,并使底层的I/O异步发生。该补丁将所谓的协作多任务处理引入到了Python标准库和一些第三方模块中,但更改几乎完全隐藏在应用程序之外,现有的代码仍然保持其同步外观,但同时又获得了异步服务请求的能力。这种方法有一个明显的缺点——打补丁不会改变每个HTTP请求的服务方式,即每个HTTP处理程序中的I/O仍然会顺序发生,即使它变成了异步的。我们可以开始使用类似于asyncio.gather()的东西,并将一些到外部资源的请求并行化,但是这需要对现有的应用程序代码进行修改。但是,现在我们可以轻松地扩展我们应用程序的并发HTTP请求限制。在应用补丁之后,我们不再需要每个请求都有一个专门的线程(或进程)。相反,每个请求处理过程现在都在一个轻量级的绿色线程中发生。因此,该应用程序可以处理数万个并发请求,这可能比以前的限制增加了1-2个数量级。
然而,虽然这个描述听起来非常有前途(至少对我来说),但是这个项目和它周围的生态系统正在逐渐失去吸引力(支持asyncio和aiohttp?)
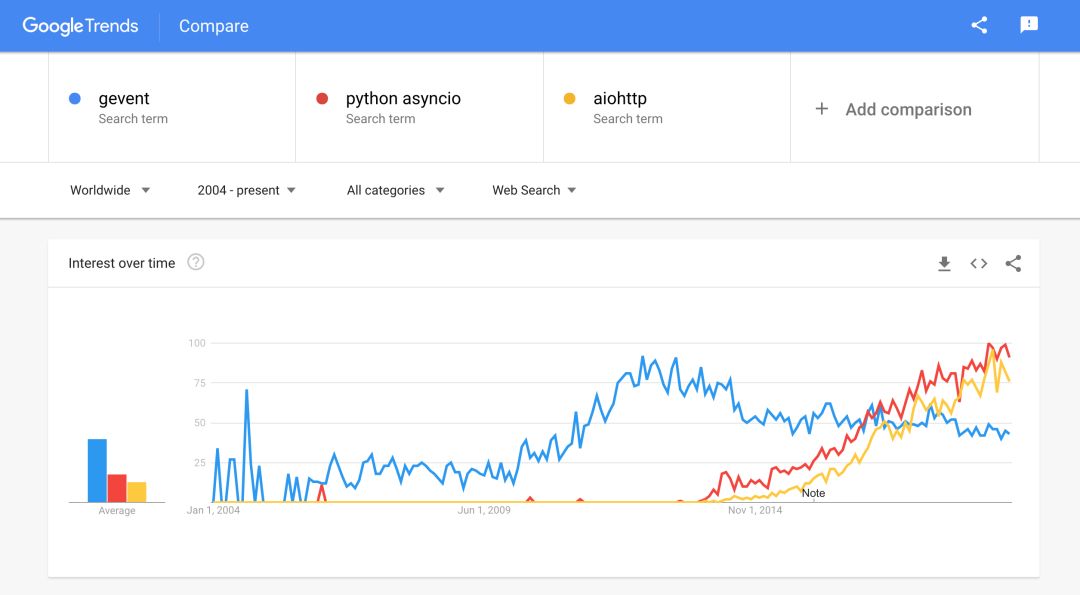
创建简单的Flask应用程序
标准的教程格式对我来说总是很无聊的。相反,我们将尝试在这里创建一个小操场。我们将尝试创建一个简单的依赖于沉睡的第三方API端点的Flask应用程序。我们的应用程序的唯一路径将会使用一些硬编码字符串连接API响应文本进行响应。有了这样的工作负载,我们将使用不同的方法来实现Flask处理HTTP请求的高并发性。
首先,我们需要模拟一个缓慢的第三方API。我们将使用aiohttp来实现它,因为它基于asyncio库,并为I/O密集型HTTP请求处理提供了开箱即用的高并发性:
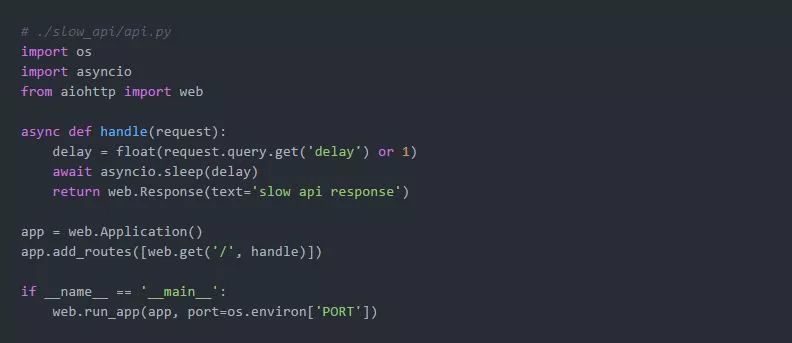
我们可以在以下Docker容器中运行它:

现在,是时候创建目标Flask应用程序了:
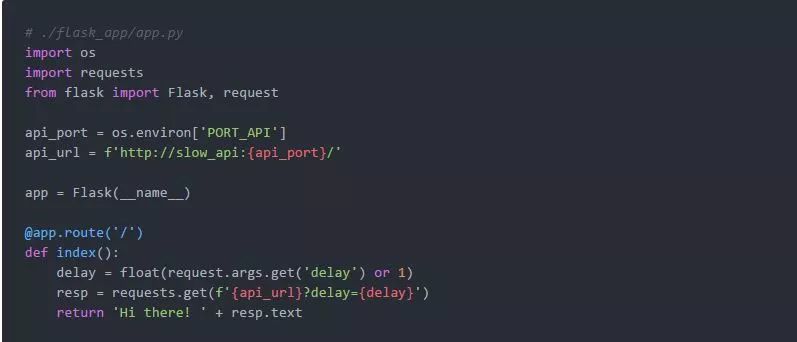
正如我们承诺的那样,它相当简单。
使用Flask开发服务器部署Flask应用程序
运行Flask应用程序的最简单方法是使用内置的开发服务器。但即使是这个庞然大物也支持两种请求处理模式。
在单线程模式下,Flask应用程序一次只能处理一个HTTP请求。也就是说,请求处理变成了顺序的。
>>经验
在多线程模式下,Flask为每个传入的HTTP请求生成一个线程。不过,最大并发性(即同时运行的线程的最大可能数量)似乎是不可配置的。
我们将使用以下Dockerfile来运行Flask开发服务器:
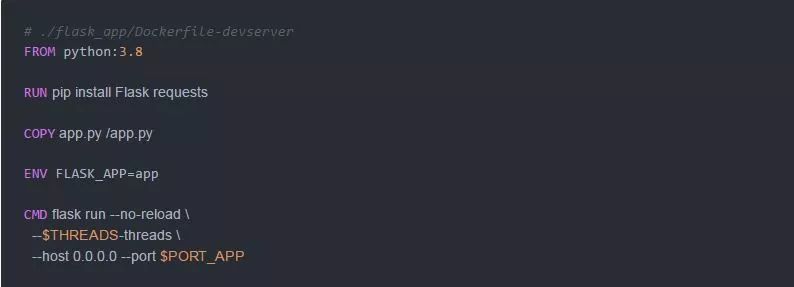
让我们使用方便的Docker Compose来创建第一个运行环境吧:
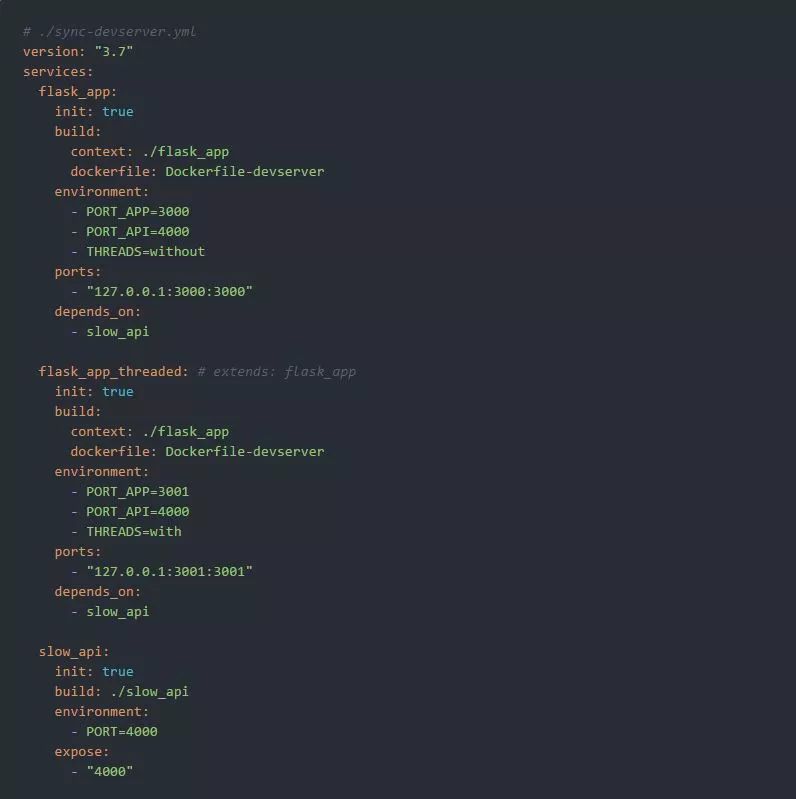
在运行了docker-compose build和docker-compose up之后,我们的应用程序的两个实例就开始运行了。单线程版本被绑定到主机的127.0.0.1:3000,而多线程版本被绑定到127.0.0.1:3001。

现在该为HTTP请求的第一部分提供服务了(使用可爱的ApacheBench)。我们将从单线程版本开始,只处理10个请求:
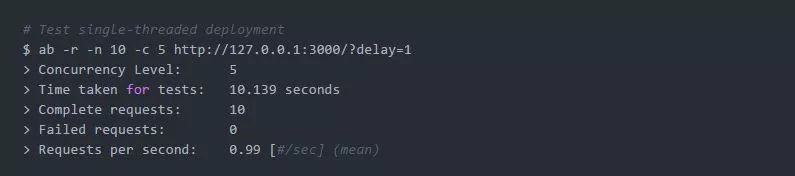
正如预期的那样,我们发现没有并发。尽管我们要求ab使用- c 5来模拟5个并发的客户机,但是它花费了大约10秒来完成这个场景,有效请求率接近每秒1次。
如果你在服务器容器中执行top -H来检查正在运行的线程的数量,情况将类似如下:
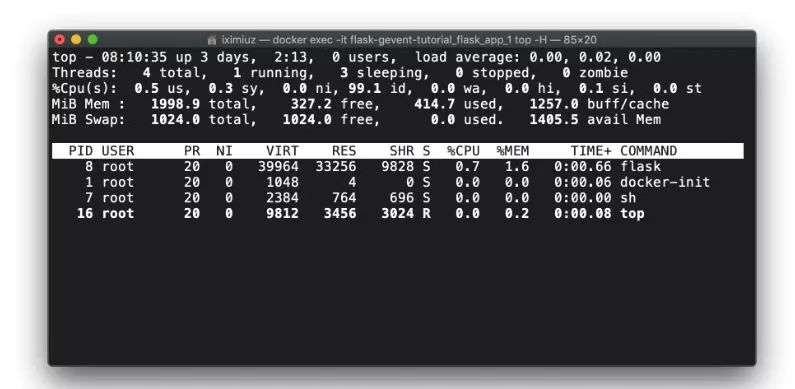
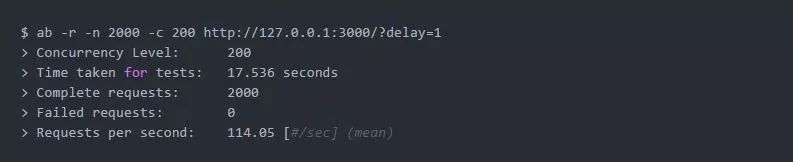
docker exec -it flask-gevent-tutorial_flask_app_1 top -H让我们进入多线程版本,同时将负载增加到由200个并发客户端产生的2000个请求:
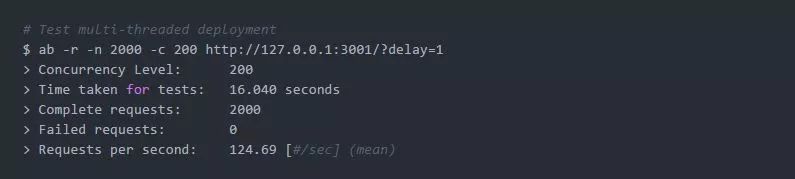
有效并发性增长到平均每秒124个请求,但是来自top - H的一个示例显示,在某个时间点,我们有192个线程,其中190个处于休眠状态:
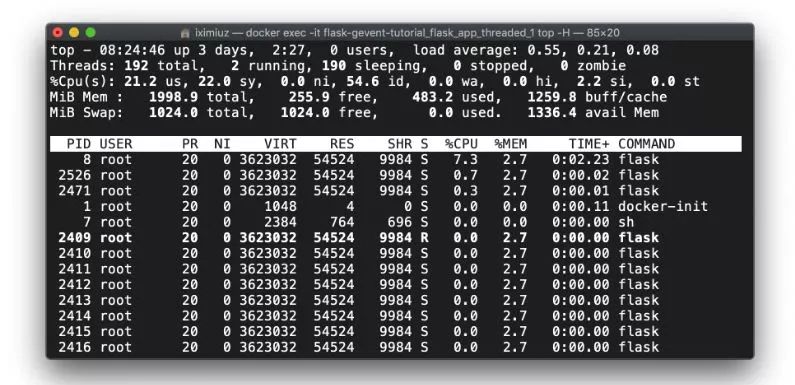
docker exec - flask-gevent-tutorial_flask_app_threaded_1 top -H使用gevent.pywsgi部署Flask应用程序
释放gevent威力的最快方法是使用它内置的称为gevent.pywsgi的WSGI服务器。
我们需要创建一个入口点:
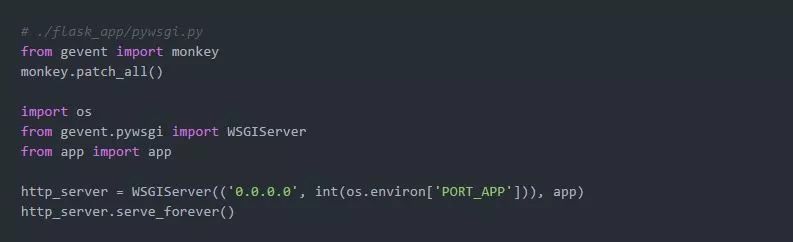
注意,它是如何修补我们的Flask应用程序的。如果没有monkey.patch_all(),在这里使用gevent就没有任何好处,因为应用程序中的所有I/O都是保持同步的。
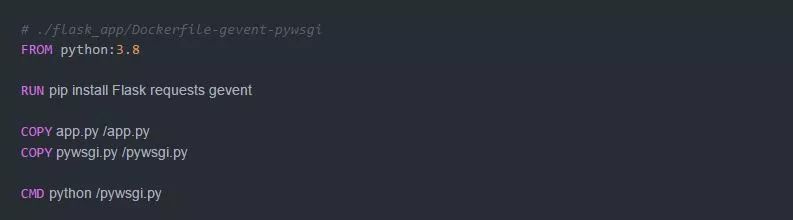
下面的Dockerfile可以用来运行pywsgi服务器:
最后,让我们准备下面的运行环境:
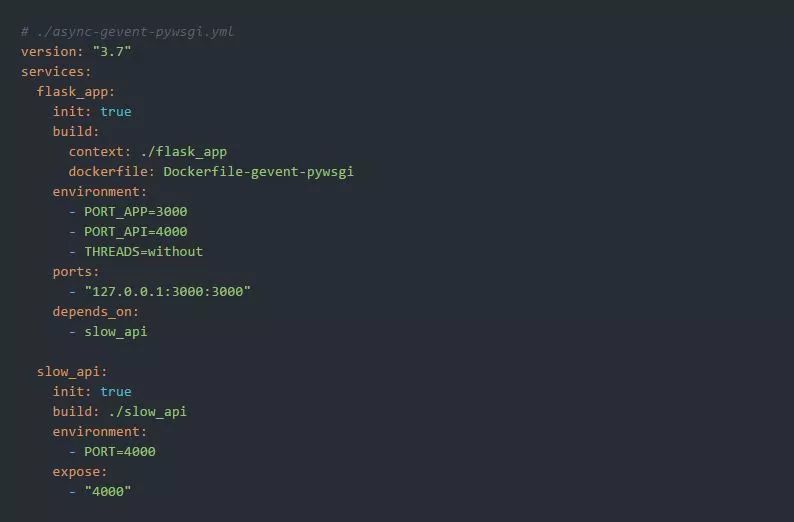
并使用以下命令来启动它:

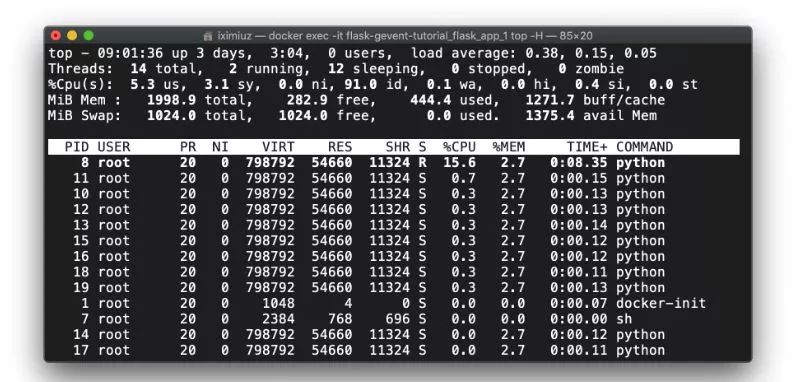
我们希望达到一个像样的并发水平,此时的服务器容器中只有很少的线程(如果有的话):
执行top -H表明我们确实有一些python线程(大约10个)。似乎gevent使用了一个线程池来实现异步I/O:
docker exec - flask-gevent-tutorial_flask_app_1 top -H使用Gunicorn部署Flask应用程序
Gunicorn是运行Flask应用程序的推荐方法之一。我们将从Gunicorn开始,因为它在运行之前需要配置的参数比uWSGI略少。
Gunicorn使用工人进程模型来服务HTTP请求。但是有多种类型的工人进程:同步的、异步的、tornado工人进程和asyncio工人进程。
在本教程中,我们将只讨论前两种类型——同步的和基于gevent的异步工人进程。让我们从同步模型开始:
请注意,我们在没有进行任何更改的情况下重用了原始的app.py入口点。同步的Gunicorn 运行环境如下图所示:
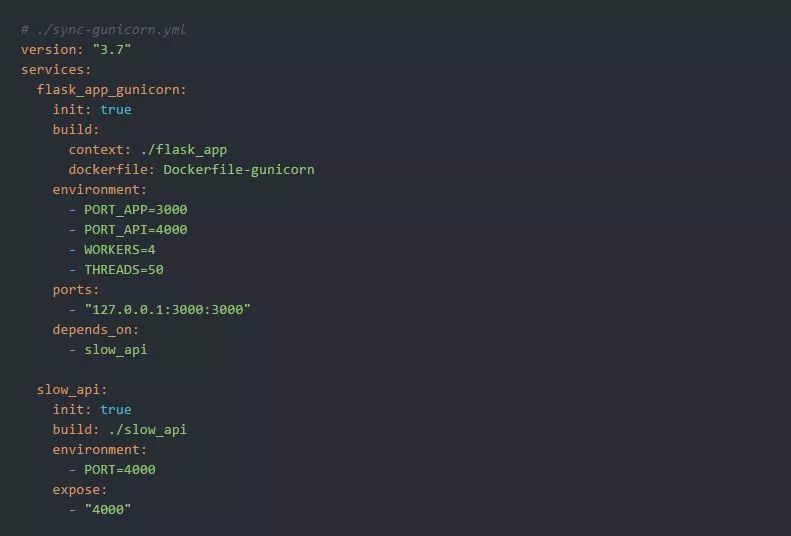
让我们用4个工人进程x 50个线程(即总共200个线程)来构建和启动每一个服务器:

显然,我们期望并发地处理大量的请求:
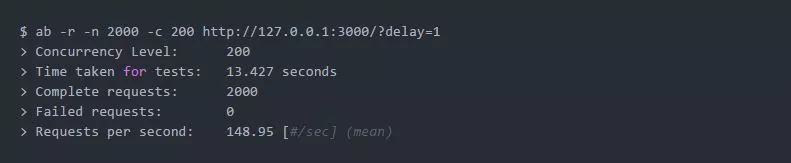
但是如果我们比较top -H测试前后的示例,我们会发现一个有趣的细节:
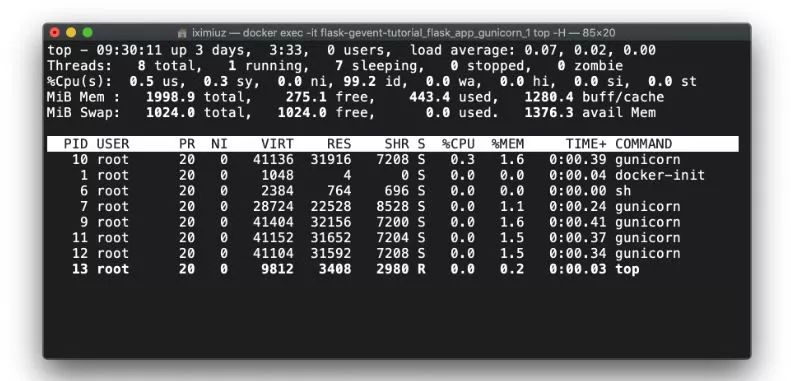
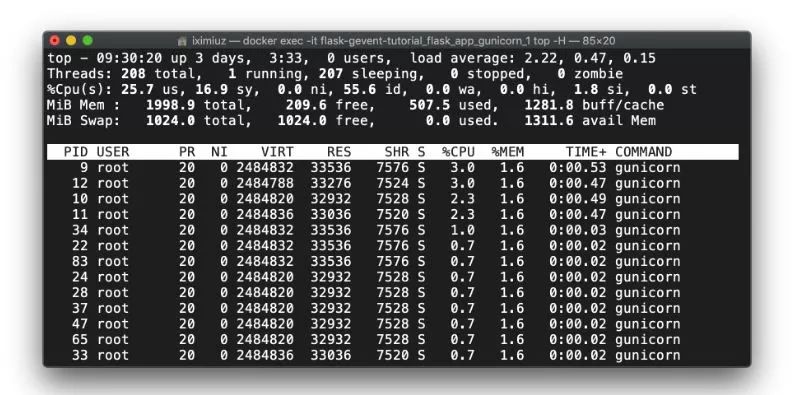
docker exec - flask-gevent-tutorial_flask_app_gunicorn_1 top -H(测试前)Gunicorn在启动时就启动了工人进程,但工人进程则按需生成线程:
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (测试中)现在,让我们切换到gevent工人进程 。对于这个设置,我们需要创建一个新的入口点来应用monkey补丁:

运行Gunicorn + gevent的Dockerfile:
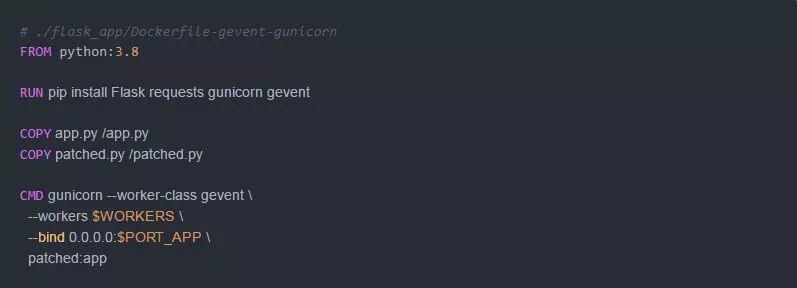
运行环境:
让我们启动它:

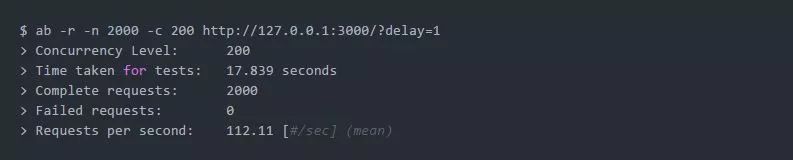
并进行测试:
我们观察到了类似的行为——只有工人进程在测试前是活动的:
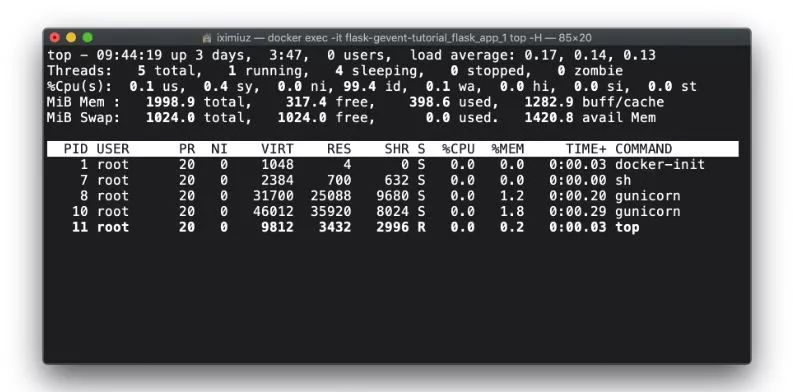
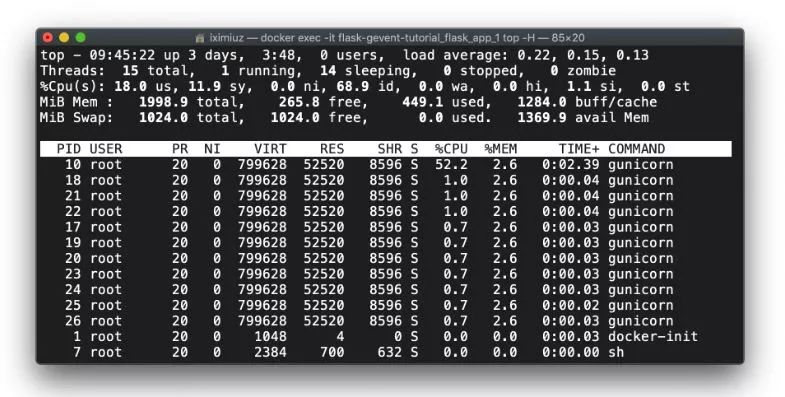
docker exec -it flask-gevent-tutorial_flask_app_gunicorn_1 top -H (测试前)但是在测试期间,我们看到有10个新线程产生了。请注意,它与pywsgi使用的线程数有多么相似:
docker exec - flask-gevent-tutorial_flask_app_gunicorn_1 top -H(测试期间)使用uWSGI部署Flask应用程序
uWSGI是一个用C编写的生产级应用服务器,它非常快,并支持不同的执行模式。这里我们将再次只比较两种模式:同步的(N个工人进程x K个线程/每个工人进程)和基于gevent的 (N个工人进程x M个异步核心/每个工人进程)。
首先,进行同步模式设置:
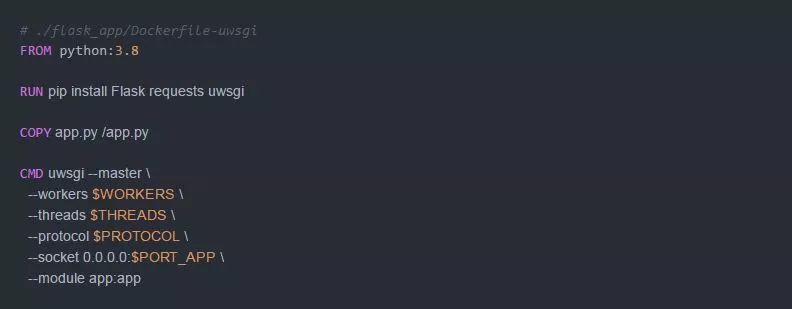
我们使用一个额外的参数--protocol 和运行环境将它设置为http:
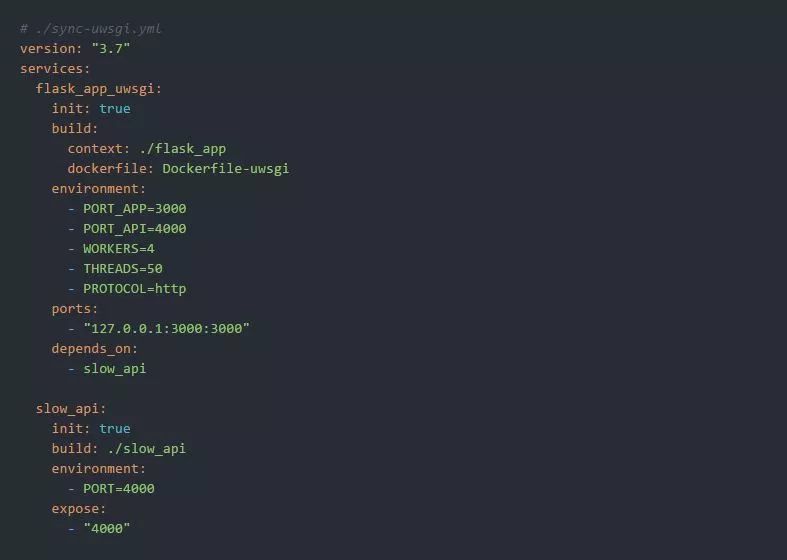
我们再次将并发性限制为200个并发的HTTP请求(4个工人进程x 50个线程/每个工人进程):

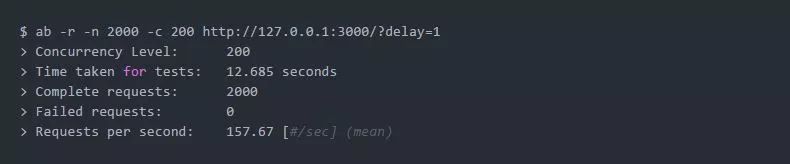
我们来发送一堆HTTP请求:
uWSGI会事先生产工人进程和线程:
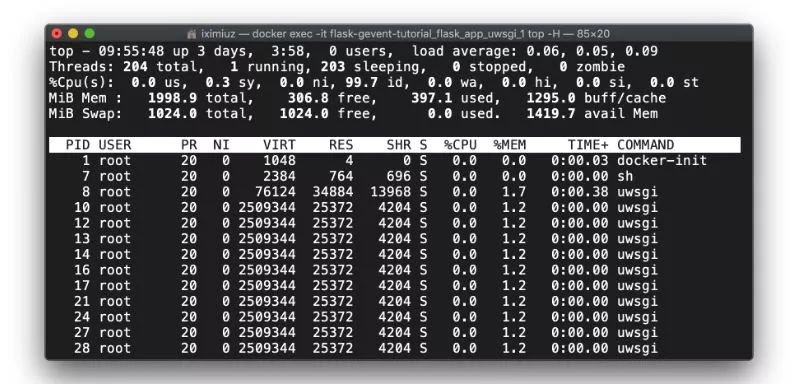
docker exec -it flask-gevent-tutorial_flask_app_uwsgi_1 top -H (测试前)因此,只有负载在测试期间会发生变化:
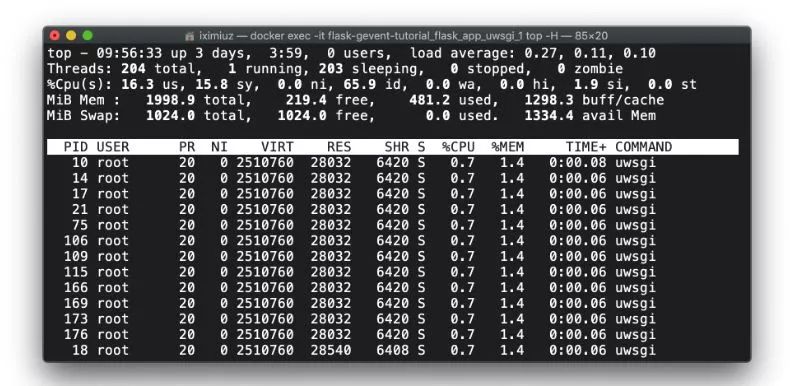
docker exec -it flask-gevent-tutorial_flask_app_uwsgi_1 top -H (测试中)让我们进入gevent模式。我们可以重用来自Gunicorn+gevent场景的patched.py 入口点:
这里运行环境设置的一个额外参数是gevent使用的异步核心的数量:
让我们启动uWSGI+gevent服务器:

并进行测试:

但是,如果我们在测试前和测试中检查工人进程的数量,我们会发现与之前的方法不一致的地方:
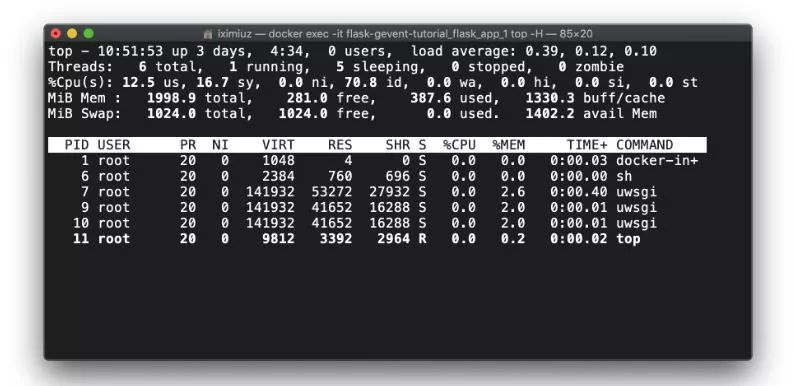
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (测试前)在测试之前,uWSGI只有主进程和工人进程,但是在测试期间,它启动了线程,每个工人进程大约有10个线程。这个数字类似于来自gevent.pywsgi和Gunicorn+gevent案例的数字:
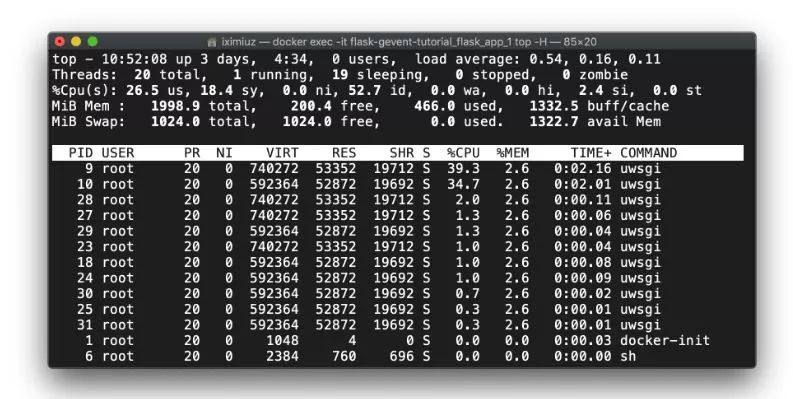
docker exec -it flask-gevent-tutorial_flask_app_1 top -H (测试中)在应用服务器前使用Nginx反向代理
通常,uWSGI和Gunicorn服务器位于负载均衡器之后,最流行的选择之一是Nginx。
Nginx + Gunicorn + gevent
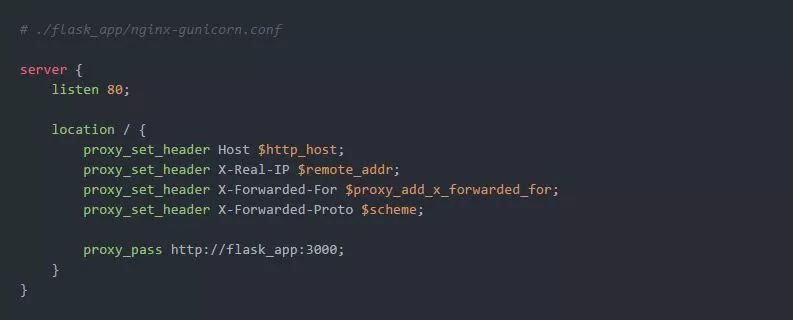
Gunicorn上游的Nginx配置只是一个标准的代理设置:
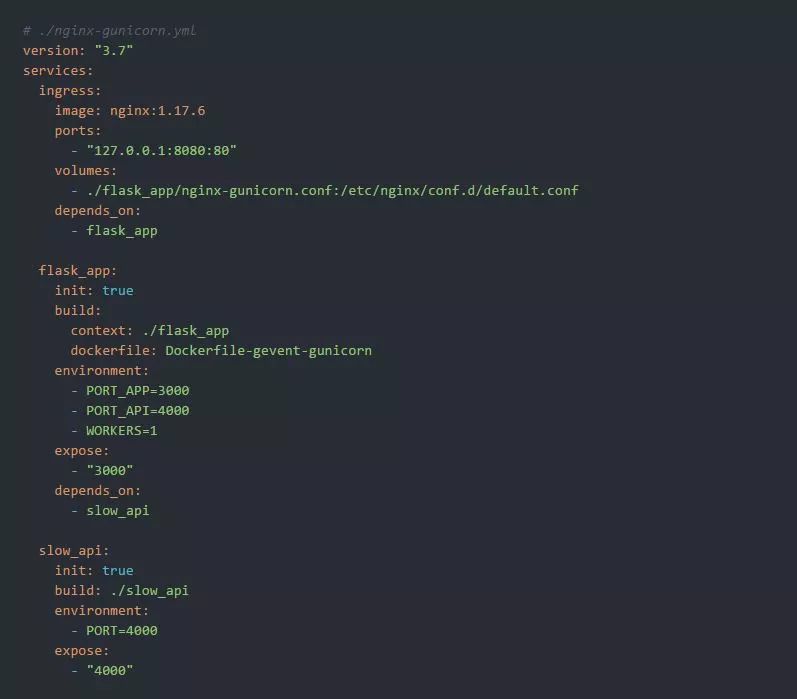
我们可以使用以下运行环境来尝试一下:
然后:

Nginx + uWSGI + gevent
uWSGI的设置非常类似,但是有一个细微的改进。uWSGI提供了一种特殊的二进制协议(称为uWSGI)来与它前面的反向代理进行通信。这使得此组合稍微更有效率。并且Nginx非常支持它:
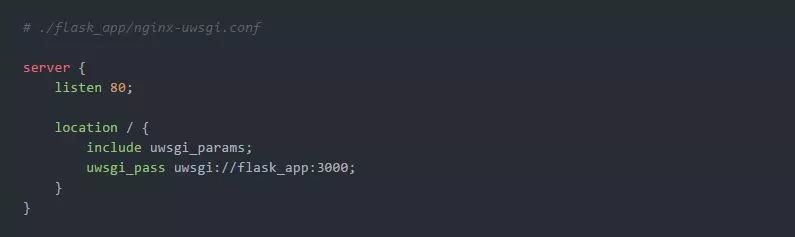
注意,以下运行环境中的环境变量PROTOCOL=uwsgi:
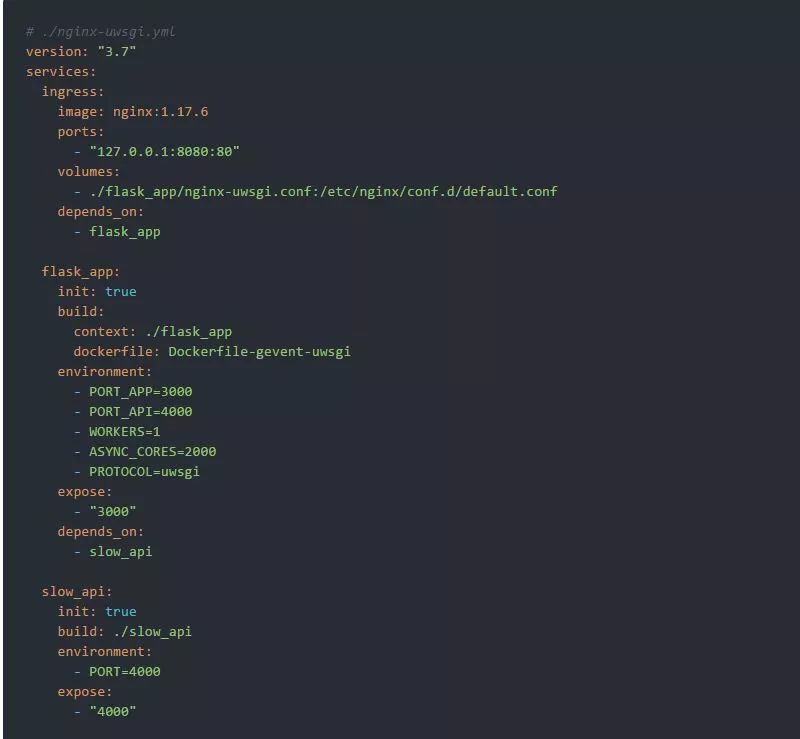
我们可以使用以下命令来测试该运行环境:

福利:使用psycogreen使psycopg2变得gevent友好
当需要时,gevent只修补来自Python标准库中的模块。如果我们使用了第三方模块,比如psycopg2,相关的IO将保持阻塞。让我们考虑一下以下的应用程序:
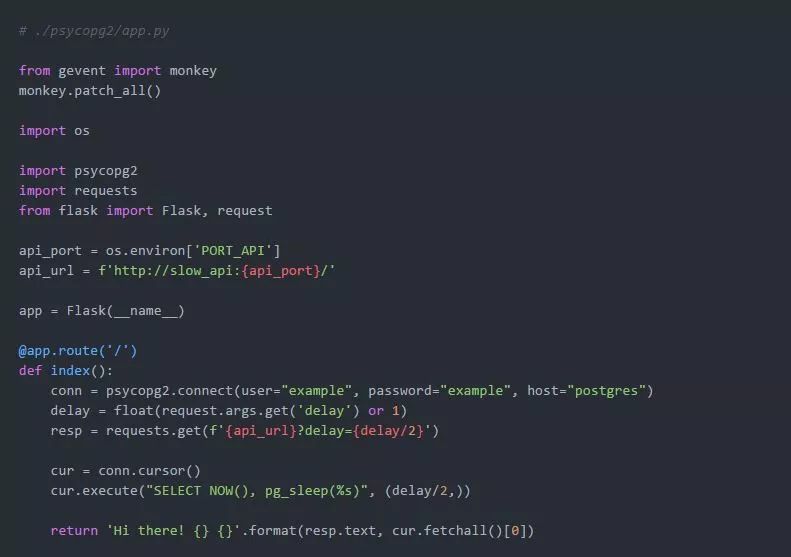
我们通过故意增加缓慢的数据库访问来扩展工作负载。我们来准备Dockerfile:
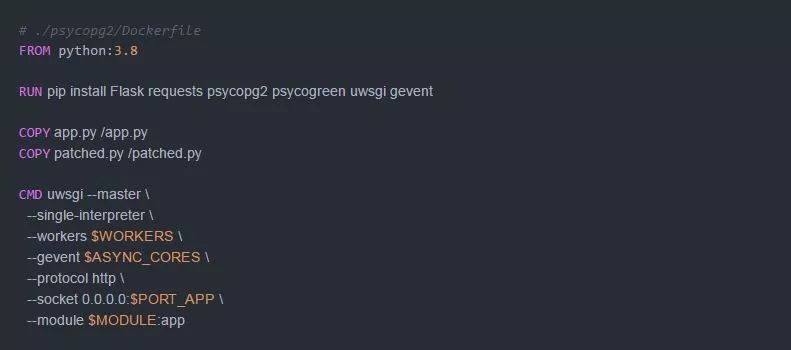
以及运行环境:
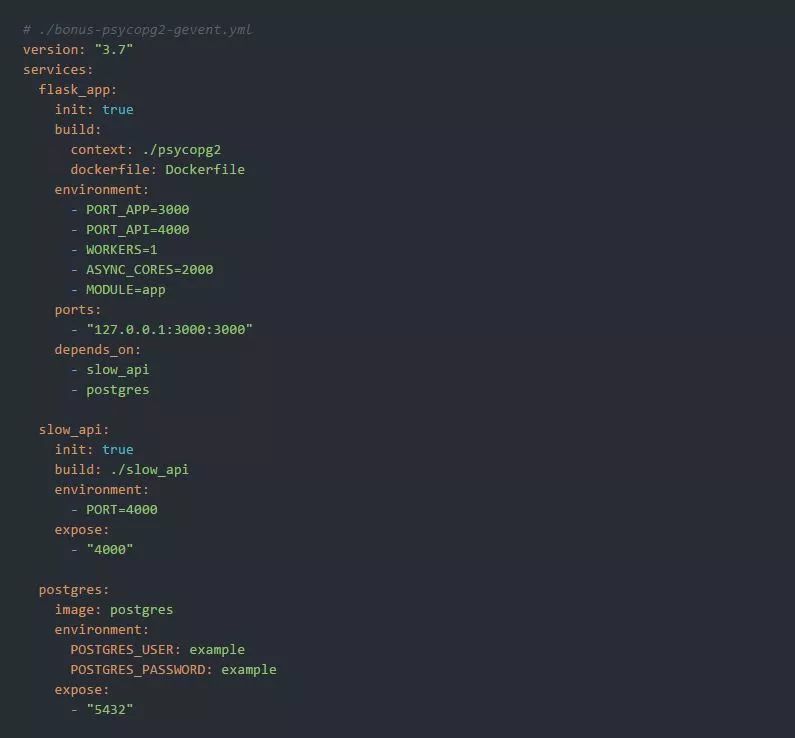
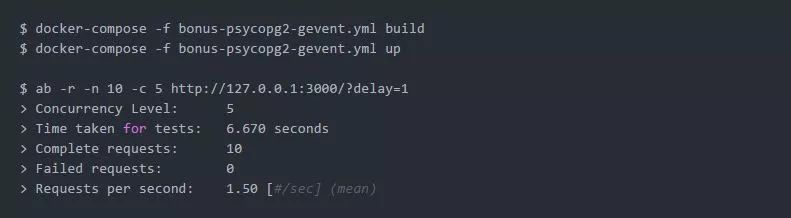
理想情况下,我们期望使用并发性为5在约2秒内去执行10个一秒长的HTTP请求。但是,由于psycopg2调用的阻塞行为,测试显示结果超过了6秒:
为了绕过这个限制,我们需要使用psycogreen模块来修补psycopg2:
psycogreen包使psycopg2能够使用协同库,在内部使用异步调用,但同时提供一个阻塞接口,这样常规的代码就可以不加修改地运行。Psycopg从2.2版开始就提供协同程序支持。因为其主模块是一个C扩展,所以不能通过应用猴子补丁使其变得协同程序友好。相反,它暴露了一个钩子,协同库可以使用它来安装与它们的事件调度器集成的函数。Psycopg将在执行可能阻塞的libpq调用时调用该函数。psycogreen是一组“等待回调”的集合,对于将Psycopg与不同的协同程序库集成在一起非常有用。
让我们创建一个入口点:

并扩展运行环境:
如果我们用ab -n 10 -c 5测试应用程序的新实例,观察到的性能将非常接近理论性能:
作者:Ivan Velichko,在twitter @iximiuz上关注我吧!
英文原文:https://iximiuz.com/en/posts/flask-gevent-tutorial/
译者:天天向上
以上是关于利用flask和gevent怎样实现长连接的主要内容,如果未能解决你的问题,请参考以下文章