Hadoop安装和配置
Posted 尘世中一个迷途小书童
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop安装和配置相关的知识,希望对你有一定的参考价值。
环境:Ubuntu16.10、hadoop-2.7.2
一、 在Linux中安装hadoop
1、 将hadoop的开发包上传到Linux中
2、 将hadoop解压缩到“/usr/local”目录下
|
tar xzvf hadoop-2.7.2.tar.gz -C /usr/local |
3、 进行目录名称修改
|
mv hadoop-2.7.2/ hadoop |
4、 进行环境变量配置
使用vim进入“/etc/profile”文件里进行目录的定义
|
export HADOOP_HOME=/usr/local/Hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin: |
5、 让配置立刻生效
|
source /etc/profile |
6、 在hadoop一个资源文件里定义要使用的JDK路径
文件路径:/usr/local/Hadoop/etc/Hadoop/Hadoop-env.sh
|
export JAVA_HOME=/usr/local/jdk |
保存退出
二、设置主机名
1、 为了配置方便,给每一台电脑设置一个主机名称
|
vim /etc/hostname 将里面的localhost修改为“hadoopm” |
2、 修改主机的映射配置, “/etc/hosts”文件,追加IP地址与hadoopm主机名称映射
|
vim /etc/hosts 192.168.15.128 hadoopm |
重新启动使之生效,输入reboot
三、设置ssh免密登录
1、由于电脑上可能已经出现过了SSH相关配置,删除根路径下的“.ssh”文件夹
|
rm -rf ~/.ssh |
2、在hadoopm的主机上生成ssh key
|
ssh-keygen -t rsa 所有出现的确认的配置信息都使用默认的方式进行处理 |
3、将公钥信息保存在授权认证的文件中
|
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys |
4、随后登录
|
ssh root@hadoopm |
如果登录之后变为了远程连接,那么此时可以使用exit退出当前的连接
四、进行hadoop的配置,需要配置如下几个文件(/usr/local/hadoop/etc/hadoop)
1、配置“core-site.xml”
|
vim core-site.xml |
|
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/home/root/hadoop_tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoopm:9000</value> </property> </configuration> |
为了保证运行不出错,可以直接建立一个“/home/root/hadoop_tmp”目录
|
mkdir ~/hadoop_tmp |
2、配置“yarn-site.xml”
|
<configuration> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoopm:8033</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoopm:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoopm:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>hadoopm:8050</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoopm:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address</name> <value>hadoopm:8090</value> </property> </configuration> |
3、配置“hdfs-site.xml”
|
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.namenode.http-address</name> <value>hadoopm:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoopm:50090</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> |
五、设置主节点和从节点并格式化
1、建议在“/usr/local/hadoop/etc/hadoop/”目录中创建一个masters文件,里面写上主机的名称,内容就是hadoopm(之前在hosts文件里定义的主机名称)。
如果是单机,不写也可。
|
vim masters |
|
输入:”hadoopm” |
2、、 修改从节点文件(slaves),增加hadoopm
|
vim slaves |
|
输入:”hadoopm” |
3、 由于此时是将所有的namenode、datanode保存路径设置在hadoop目录中,保险起见,自己创建
|
mkdir dfs dfs/name dfs/data |
如果hadoop出了问题、需要重新配置时,请保证这两个文件夹彻底清除
4、格式化文件系统
|
hdfs namenode -format bin/hadoop namenode -format |
如果此时格式化正常,会出现“INFO util.ExitUtil:Exiting with status 0”
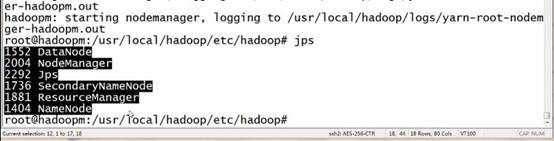
六、启动hadoop
|
start-dfs.sh start-yarn.sh |
|
stop-yarn.sh start-dfs.sh |
以上是关于Hadoop安装和配置的主要内容,如果未能解决你的问题,请参考以下文章