Spark安装:CentOS7 + JDK7 + Hadoop2.6 + Scala2.10.4
Posted Uncle Nucky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark安装:CentOS7 + JDK7 + Hadoop2.6 + Scala2.10.4相关的知识,希望对你有一定的参考价值。
本文搭建环境为:Mac + Parallel Desktop + CentOS7 + JDK7 + Hadoop2.6 + Scala2.10.4 + IDEA14.0.5
——————————————————————————————————————————————————
一、CentOS安装
■ 安装完成后记得保存快照。
■ 环境准备
CentOS7下载:http://mirrors.163.com/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1511.iso。
■ Mac Parallel Desktop安装CentOS 7 - http://www.linuxidc.com/Linux/2016-08/133827.htm
配置网卡(无需)
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
保存后重启网卡
/etc/init.d/network stop
/etc/init.d/network start
安装网络工具包(无需)
yum install net-tools
yum install wget
packagekit问题:yum安装出现“/var/run/yum.pid 已被锁定,强行解除锁
rm -f /var/run/yum.pid
更改源为阿里云
cd /etc/yum.repos.d/
mv CentOS-Base.repo Centos-Base.repo.bak
wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
■ CentOS 7 GNOME 图形界面(无需)
yum groupinstall "X Window System"
yum groupinstall "GNOME Desktop"
startx --> 进入图形界面
runlevel —> 运行级别查看
■ CentOS 7安装后配置
http://www.cnblogs.com/pinnsvin/p/5889857.html
——————————————————————————————————————————————————
二、JDK安装
CentOS卸载openjdk
卸载CentOS7-x64自带的OpenJDK并安装Sun的JDK7 - http://www.cnblogs.com/CuteNet/p/3947193.html
rpm -qa | grep java
以下命令需根据上一指令结果:
rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
rpm -e --nodeps tzdata-java-2015g-1.el7.noarchrpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarchrpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
CentOS安装Oracle JDK1.7
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html,下载jdk-7u79-linux-x64.tar.gz
mkdir /usr/local/java
cp jdk-7u79-linux-x64.tar.gz /usr/local/java
cd /usr/local/java
tar xvf jdk-7u79-linux-x64.tar.gz
rm jdk-7u79-linux-x64.tar.gz
设置jdk环境变量
vim /etc/profile
打开之后在末尾添加
export JAVA_HOME=/usr/local/java/jdk1.7.0_79
export JRE_HOME=/usr/local/java/jdk1.7.0_79/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
执行配置文件,令其立刻生效
source /etc/profile
验证是否安装成功
java -version
——————————————————————————————————————————————————
三、Hadoop安装
http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
su
useradd -m hadoop -s /bin/bash
passwd hadoop(hadoop)
visudo
hadoop ALL=(ALL) ALL
rpm -qa | grep ssh
cd ~/.ssh/
ssh-keygen -t rsa 都按回车
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
下载Hadoop:http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
sudo tar -zxf ~/home/hadoop/桌面/hadoop-2.6.0.tar.gz -C /usr/local
cd /usr/local/
mv ./hadoop-2.6.0/ ./hadoop
sudo chown -R hadoop:hadoop ./hadoop
检查是否可用
cd /usr/local/hadoop
./bin/hadoop version
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
--> Hadoop初步环境搭建完成
Hadoop单机配置(非分布式)
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output \'dfs[a-z.]+\'
cat ./output/* # 查看运行结果
rm -r ./output
gedit ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/usr/local/java/jdk1.7.0_79
export JRE_HOME=/usr/local/java/jdk1.7.0_79/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bashrc
gedit ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
gedit ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
./bin/hdfs namenode –format
./sbin/start-dfs.sh
显示如下:
[hadoop@localhost hadoop]$ jps
27710 NameNode
28315 SecondaryNameNode
28683 Jps
27973 DataNode
问题
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
tar -x hadoop-native-64-2.6.0.tar -C /usr/local/hadoop/lib/native/
cp /usr/local/hadoop/lib/native/* /usr/local/hadoop/lib/
加入系统变量
export HADOOP_COMMON_LIB_NATIVE_DIR=/home/administrator/work/hadoop-2.6.0/lib/native
export HADOOP_OPTS="-Djava.library.path=/home/administrator/work/hadoop-2.6.0/lib"
export HADOOP_ROOT_LOGGER=DEBUG,console
主要是jre目录下缺少了libhadoop.so和libsnappy.so两个文件。具体是,spark-shell依赖的是scala,scala依赖的是JAVA_HOME下的jdk,libhadoop.so和libsnappy.so两个文件应该放到$JAVA_HOME/jre/lib/amd64下面。
这两个so:libhadoop.so和libsnappy.so。前一个so可以在HADOOP_HOME下找到,如hadoop\\lib\\native。第二个libsnappy.so需要下载一个snappy-1.1.0.tar.gz,然后./configure,make编译出来,编译成功之后在.libs文件夹下。
当这两个文件准备好后再次启动spark shell不会出现这个问题。
链接:https://www.zhihu.com/question/23974067/answer/26267153
问题:由于在root用户下安装Java,而Hadoop用户缺少操作java目录的权限
cd /
sudo chown -R hadoop:hadoop ./usr/local/java
Hadoop开启关闭调试信息
开启:export HADOOP_ROOT_LOGGER=DEBUG,console
关闭:export HADOOP_ROOT_LOGGER=INFO,console
Hadoop伪分布式实例
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
./bin/hdfs dfs -ls input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output \'dfs[a-z.]+\'
./bin/hdfs dfs -cat output/*
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
关闭Hadoop
./sbin/stop-dfs.sh
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行
./sbin/start-dfs.sh 就可以!
启动YARN
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性,YARN 的更多介绍在此不展开,有兴趣的可查阅相关资料。
上述通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
./sbin/start-dfs.sh
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
gedit ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
gedit ./etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
./sbin/start-yarn.sh $ 启动YARN
./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
[hadoop@localhost hadoop]$ jps
11148 JobHistoryServer
9788 NameNode
10059 DataNode
11702 Jps
10428 SecondaryNameNode
10991 NodeManager
10874 ResourceManager
http://localhost:8088/cluster
关闭YARN
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
——————————————————————————————————————————————————
四、Spark安装
《Spark快速入门指南 – Spark安装与基础使用》- http://dblab.xmu.edu.cn/blog/spark-quick-start-guide/
下载
spark-1.6.0-bin-hadoop2.6.tgz
http://d3kbcqa49mib13.cloudfront.net/spark-1.6.0-bin-hadoop2.6.tgz
解压
sudo tar -zxf ~/下载/spark-1.6.0-bin-hadoop2.6.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-1.6.0-bin-hadoop2.6/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
安装后,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,执行如下命令拷贝一个配置文件:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
gedit ./conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
全局环境变量:
sudo gedit /etc/profile
source /etc/profile
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/usr/hadoop
export SCALA_HOME=/usr/lib/scala-2.10.4
export SPARK_HOME=/usr/local/spark
配置Spark环境变量
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
gedit spark-env.sh
spark-env.sh配置
export SCALA_HOME=/usr/lib/scala-2.10.4
export HADOOP_HOME=/usr/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_PID_DIR=$SPARK_HOME/tmp
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=1 //每个Worker使用的CPU核数
export SPARK_WORKER_INSTANCES=1 //每个Slave中启动几个Worker实例
export SPARK_WORKER_MEMORY=512m //每个Worker使用多大的内存
export SPARK_WORKER_WEBUI_PORT=8081 //Worker的WebUI端口号
export SPARK_EXECUTOR_CORES=1 //每个Executor使用使用的核数
export SPARK_EXECUTOR_MEMORY=128m //每个Executor使用的内存
export SPARK_CLASSPATH=$SPARK_HOME/conf/:$SPARK_HOME/lib/*:/usr/local/hadoop/lib/native:$SPARK_CLASSPATH
运行Spark示例
Spark 的安装目录(/usr/local/spark)为当前路径
cd /usr/local/spark
./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
Python 版本的 SparkPi 则需要通过 spark-submit 运行:
./bin/spark-submit examples/src/main/python/pi.py 2>&1 | grep "Pi is roughly"
Hadoop和YARN上运行示例
cd /etc/local/hadoop
./sbin/start-dfs.sh
./sbin/start-yarn.sh
运行示例
cd /usr/local/spark
bin/spark-submit --master yarn ./examples/src/main/python/wordcount.py file:///usr/local/spark/LICENSE
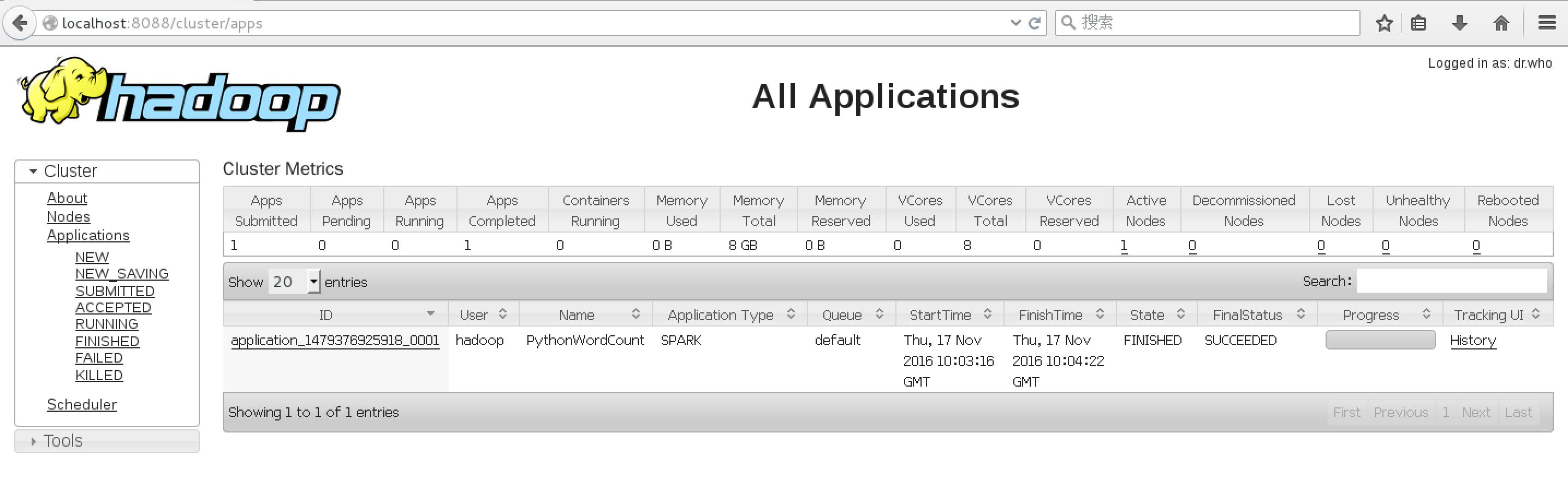
(快照:运行成功Spark示例)
通过 Spark Shell 进行交互分析
./bin/spark-shell
val textFile = sc.textFile("file:///usr/local/spark/README.md")
// textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:27
textFile.count() // RDD 中的 item 数量,对于文本文件,就是总行数
// res0: Long = 95
textFile.first() // RDD 中的第一个 item,对于文本文件,就是第一行内容
// res1: String = # Apache Spark
val linesWithSpark = textFile.filter(line => line.contains("Spark")) // 筛选出包含 Spark 的行
linesWithSpark.count() // 统计行数
// res4: Long = 17
textFile.filter(line => line.contains("Spark")).count() // 统计包含 Spark 的行数
// res4: Long = 17
RDD的更多操作
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
// res5: Int = 14
import java.lang.Math
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
// res6: Int = 14
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) // 实现单词统计
// wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29
wordCounts.collect() // 输出单词统计结果
// res7: Array[(String, Int)] = Array((package,1), (For,2), (Programs,1), (processing.,1), (Because,1), (The,1)...)
Spark SQL 和 DataFrames
Spark Streaming
方式一:
wget http://downloads.sourceforge.net/project/netcat/netcat/0.6.1/netcat-0.6.1-1.i386.rpm -O ~/netcat-0.6.1-1.i386.rpm # 下载
sudo rpm -iUv ~/netcat-0.6.1-1.i386.rpm # 安装
方式二:
wget http://sourceforge.NET/projects/netcat/files/netcat/0.7.1/netcat-0.7.1-1.i386.rpm
rpm -ihv netcat-0.7.1-1.i386.rpm
yum list glibc*
rpm -ihv netcat-0.7.1-1.i386.rpm
# 记为终端 1
nc -l -p 9999
# 需要另外开启一个终端,记为终端 2,然后运行如下命令
/usr/local/spark/bin/run-example streaming.NetworkWordCount localhost 9999 2>/dev/null
(快照:完成Spark Streaming实例)
关闭 Spark 调试信息
把spark/conf/log4j.properties下的
log4j.rootCategory=【Warn】=> 【ERROR】
log4j.logger.org.spark-project.jetty=【Warn】=> 【ERROR】
——————————————————————————————————————————————————
五、Scala安装
安装scala 2.10.4:下载scala,http://www.scala-lang.org/,下载scala-2.10.4.tgz,并复制到/usr/lib
sudo tar -zxf scala-2.10.4.tgz -C /usr/lib
采用全局设置方法,修改etc/profile,是所有用户的共用的环境变量
sudo gedit /etc/profile
export SCALA_HOME=/usr/lib/scala-2.10.4
export PATH=$SCALA_HOME/bin:$PATH
source /etc/profile
scala -version
[hadoop@localhost 下载]$ scala -version
Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
——————————————————————————————————————————————————
六、CentOS中安装IntelliJ IDEA
参考:http://dongxicheng.org/framework-on-yarn/apache-spark-intellij-idea/
Spark集成开发环境搭建
● 《linux系统下IntelliJ IDEA的安装及使用》 - http://www.linuxdiyf.com/linux/19143.html
不建议大家使用eclipse开发spark程序和阅读源代码,推荐使用Intellij IDEA
● 下载IDEA14.0.5:
http://confluence.jetbrains.com/display/IntelliJIDEA/Previous+IntelliJ+IDEA+Releases
http://download.jetbrains.8686c.com/idea/ideaIU-14.0.5.tar.gz
https://download.jetbrains.8686c.com/idea/ideaIU-2016.2.5-no-jdk.tar.gz(只支持JDK1.8以上)
Unsupported Java Version: Cannot start under Java 1.7.0_79-b15: Java 1.8 or later is required.
解压,进入到解压后文件夹的bin目录下执行
tar -zxvf ideaIU-14.tar.gz -C /usr/intellijIDEA
export IDEA_JDK=/usr/local/java/jdk1.7.0_79
./idea.sh
key:IDEA
value:61156-YRN2M-5MNCN-NZ8D2-7B4EW-U12L4
安装Scala插件
http://www.linuxdiyf.com/linux/19143.html
下载地址:http://plugins.jetbrains.com/files/1347/19005/scala-intellij-bin-1.4.zip
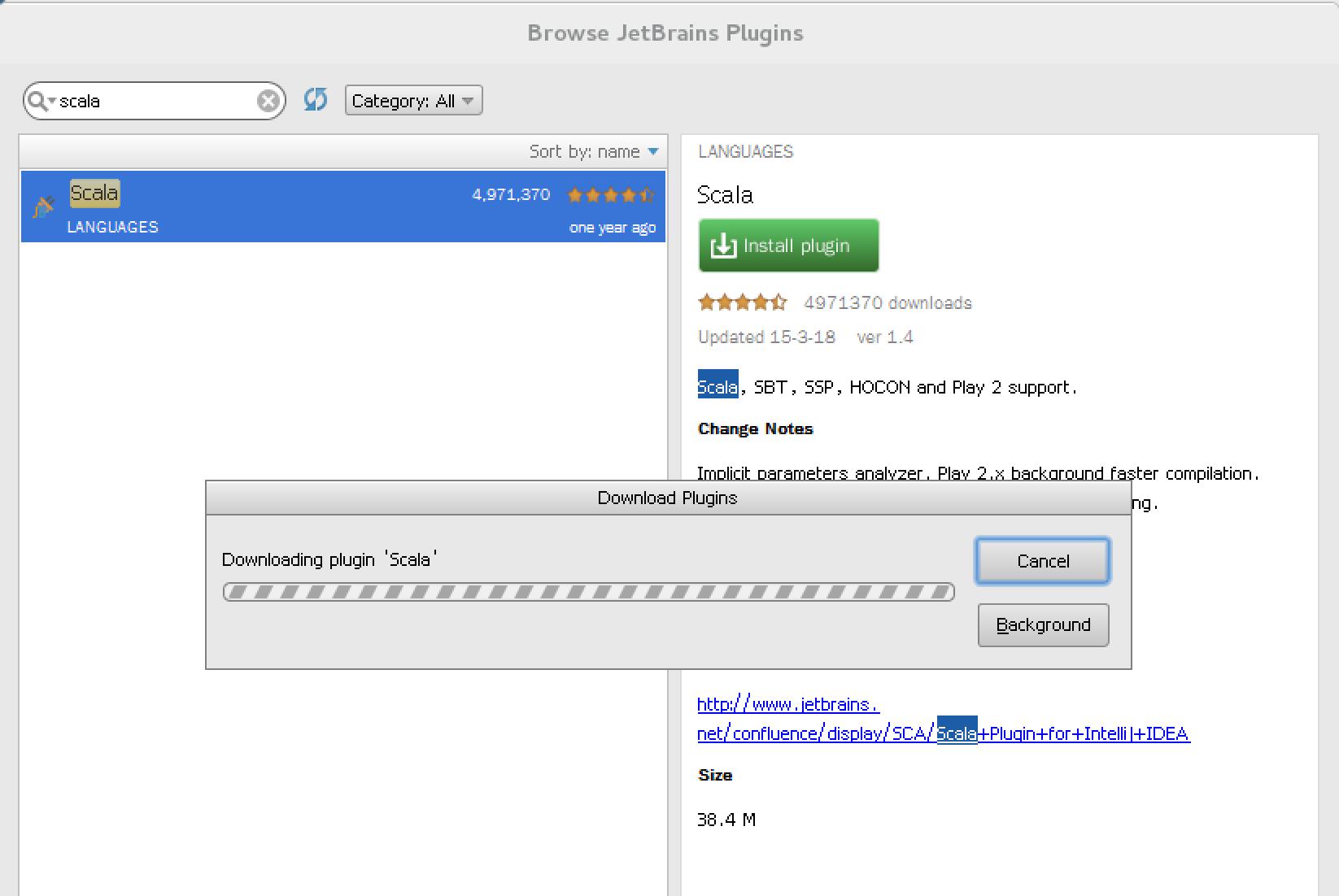
安装插件后,在启动界面中选择创建新项目,弹出的界面中将会出现"Scala"类型项目,如下图,选择scala-》scala
点击next,就如以下界面,project name自己随便起的名字,把自己安装的scala和jdk选中,注意,在选择scala版本是一定不要选择2.11.X版本,那样后续会出大错!完成后,点击Finish
然后再File下选择project Structure,然后进入如下界面,进入后点击Libraries,在右边框后没任何信息,然后点击“+”号,进入你安装spark时候解压的spark-XXX-bin-hadoopXX下,在lib目录下,选择spark-assembly-XXX-hadoopXX.jar,结果如下图所示,然后点击Apply,最后点击ok
Spark开发环境配置及流程(Intellij IDEA)
《Intellij安装scala插件详解》
http://blog.csdn.net/a2011480169/article/details/52712421
从上面显示的信息是: Updatated: 2016/7/13
于是我们到下面的网站去找匹配的插件: http://plugins.jetbrains.com/plugin/?idea&id=1347
当我们下载完插件之后: 把下载的.zip格式的scala插件放到Intellij的安装的plugins目录下;
再安装刚刚放到Intellij的plugins目录下的scala插件(注:直接安装zip文件)即可。
搭建Spark开发环境
在intellij IDEA中创建scala project,并依次选择“File”–> “project structure” –> “Libraries”,选择“+”,将spark-hadoop 对应的包导入
《Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实》
http://www.cnblogs.com/shishanyuan/p/4721120.html
scala示例代码
package class3 import org.apache.spark.SparkConf import org.apache.spark.SparkContext object WordConut { def main(args: Array[String]) { val conf = new SparkConf().setAppName("TrySparkStreaming").setMaster("local[2]") val sc = new SparkContext(conf) val txtFile = "/root/test" val txtData = sc.textFile(txtFile) txtData.cache() txtData.count() val wcData = txtData.flatMap { line => line.split(",") }.map { word => (word, 1) }.reduceByKey(_ + _) wcData.collect().foreach(println) sc.stop } }
——————————————————————————————————————————————————
Spark使用HDFS数据处理
[hadoop@localhost spark]$ hdfs dfs -put LICENSE /zhaohang
hdfs dfs -ls
hdfs dfs -cat /zhaohang | wc -l
cd /usr/local/spark/bin
./pyspark --master yarn
lines=sc.textFile("hdfs://localhost:9000/zhaohang",1)
16/11/17 19:36:34 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 228.8 KB, free 228.8 KB)
16/11/17 19:36:34 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 19.5 KB, free 248.3 KB)
16/11/17 19:36:34 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.211.55.8:60185 (size: 19.5 KB, free: 511.5 MB)
16/11/17 19:36:34 INFO spark.SparkContext: Created broadcast 0 from textFile at NativeMethodAccessorImpl.java:-2
temp1 = lines.flatMap(lambda x:x.split(\' \'))
temp1.collect()
map = temp1.map(lambda x: (x,1))
map.collect()
rdd = sc.parallelize([1,2,3,4],2)
def f(iterator): yield sum(iterator)
rdd.mapPartitions(f).collect() //[3,7]
rdd = sc.parallelize(["a","b","c"])
test = rdd.flatMap(lambda x:(x,1))
test.count()
sorted(test.collect()) //[1, 1, 1, \'a\', \'b\', \'c\']
Spark界面:http://localhost:8088/proxy/application_1479381551764_0002/jobs/
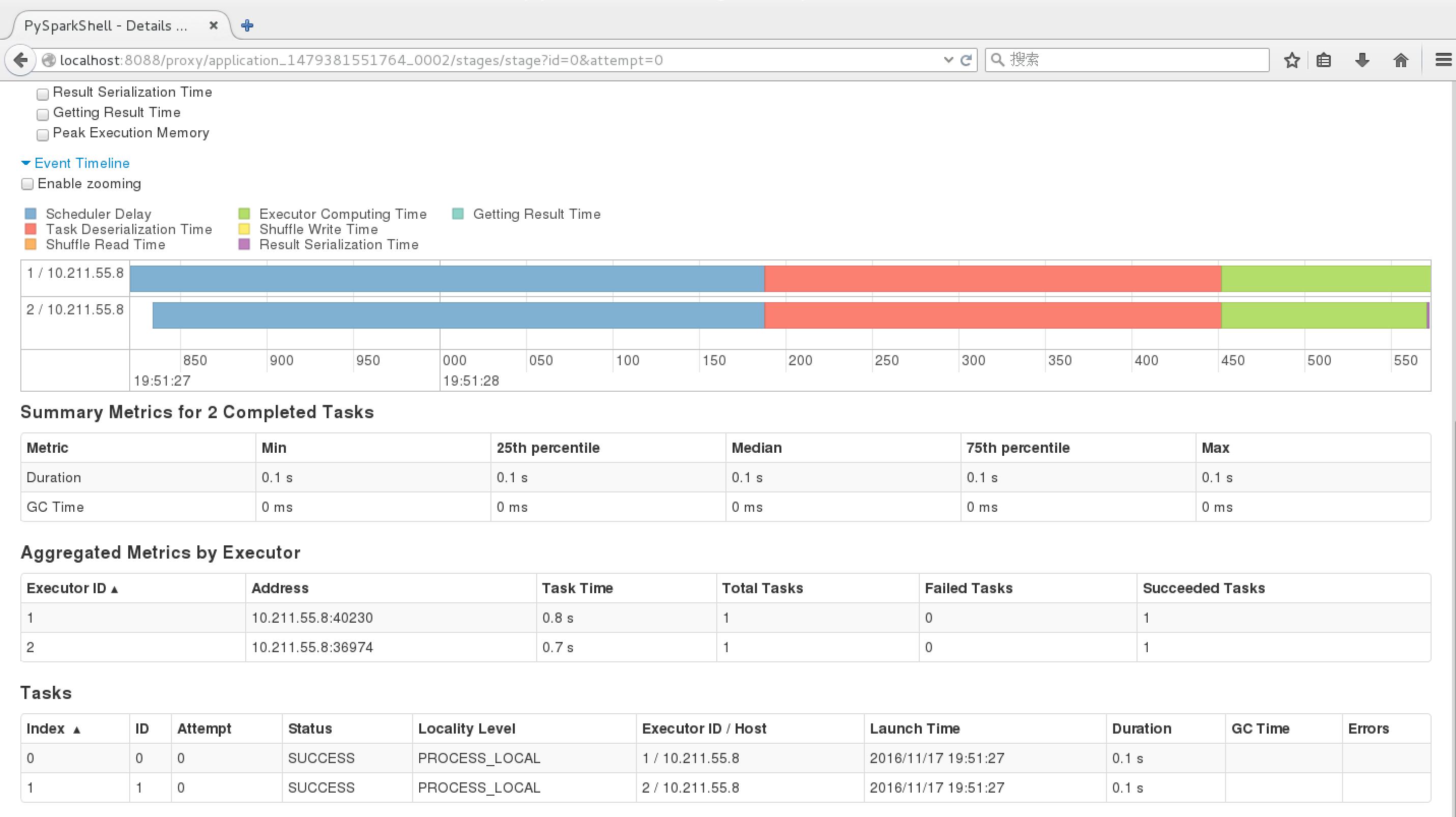
关闭YARN及HDFS
cd /usr/local/hadoop
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh
——————————————————————————————————————————————————
Spark SQL示例
——————————————————————————————————————————————————
以上是关于Spark安装:CentOS7 + JDK7 + Hadoop2.6 + Scala2.10.4的主要内容,如果未能解决你的问题,请参考以下文章
卸载CentOS7-x64自带的OpenJDK并安装Sun的JDK7的方法
卸载CentOS7-x64自带的OpenJDK并安装Sun的JDK7的方法
卸载CentOS7-x64自带的OpenJDK并安装Sun的JDK7的方法