在zepplin 使用spark sql 查询mongodb的数据
Posted 述而不做
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在zepplin 使用spark sql 查询mongodb的数据相关的知识,希望对你有一定的参考价值。
1.下载zepplin
进入官网下载地址 ,下载完整tar包.
2.解压
tar zxvf zeppelin-0.7.3.tgz
3.修改配置
新建配置文件
cp zeppelin-env.sh.template zeppelin-env.sh
修改配置文件
vi zeppelin-env.sh
# 设置java home 路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.141-1.b16.el7_3.x86_64/jre
# 设置spark master 地址
export MASTER=spark://10.100.12.16:7077
# 设置spark home 路径
export SPARK_HOME=/opt/spark/
# 设置spark mongodb connector, 注意:这里用的是2.2.2版本
export SPARK_SUBMIT_OPTIONS="--packages org.mongodb.spark:mongo-spark-connector_2.11:2.2.2"
4.启动zepplin
bin/zeppelin-daemon.sh start
5.用浏览器进入zepplin后台:http://localhost:8080
6.点击notebook,新建查询.

7.写scala 查询代码
import com.mongodb.spark.config.ReadConfig import com.mongodb.spark.sql._ val config = sqlContext.sparkContext.getConf .set("spark.mongodb.keep_alive_ms", "15000") .set("spark.mongodb.input.uri", "mongodb://10.100.12.14:27017") .set("spark.mongodb.input.database", "bi") .set("spark.mongodb.input.collection", "userGroupMapping") val readConfig = ReadConfig(config) val objUserGroupMapping = sqlContext.read .format("com.mongodb.spark.sql") .mongo(readConfig) objUserGroupMapping.printSchema() val tbUserGroupMapping=objUserGroupMapping.toDF() tbUserGroupMapping.registerTempTable("userGroupMapping")
8.返回查询结果
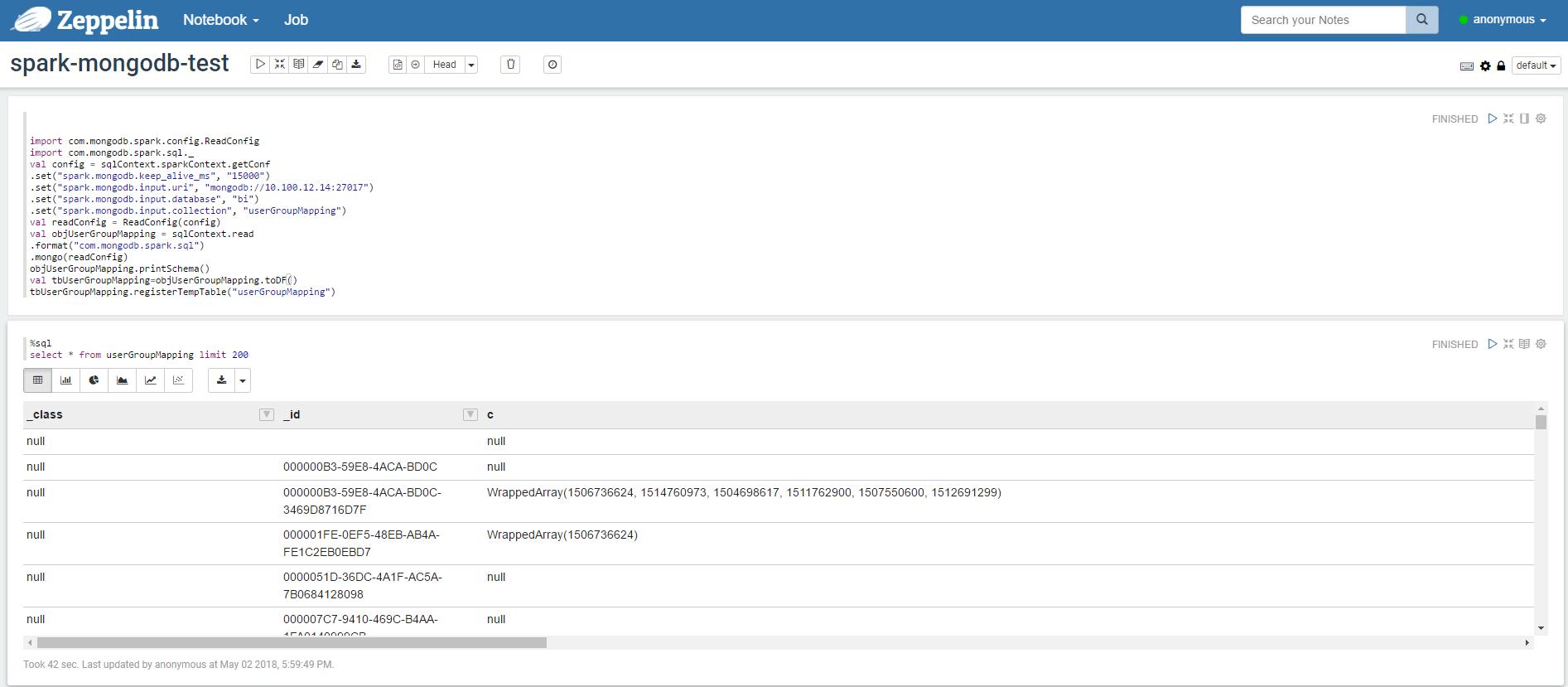
以上是关于在zepplin 使用spark sql 查询mongodb的数据的主要内容,如果未能解决你的问题,请参考以下文章