Hadoop分布式环境部署
Posted whcwkw1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop分布式环境部署相关的知识,希望对你有一定的参考价值。
机器选型
实际应用中一般分为2种
第一种:硬件服务器
第二种:云主机
准备工作
在VM ware12环境下搭建三台服务器
配置ip,主机名,本地映射(/etc/hosts)
另外两台由原先克隆而来
克隆机器后,修改mac地址
使用root:
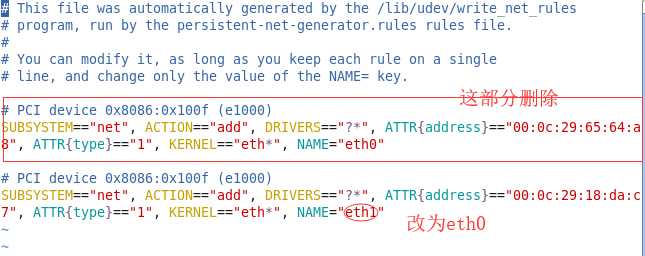
vim /etc/udev/rules.d/70-persistent-net.rules
(1)删除eth0
(2)将eth1修改为eth0
(3)复制mac地址
(4)编辑网卡信息 ,修改ip地址和Mac地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
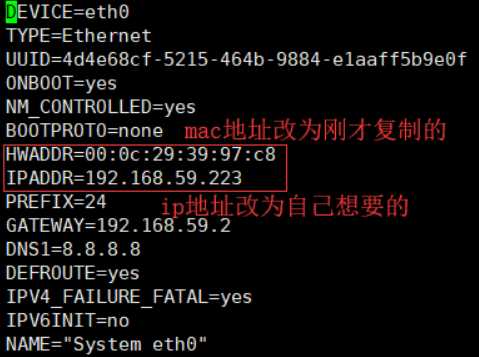
vim /etc/sysconfig/network

(6)修改Hosts文件,配置映射

(7)关闭防火墙
$ sudo chkconfig iptables off
(8)关闭Selinux(安全性太高,解决不必要的麻烦)必须要重启机器才能生效配置
$ sudo vim /etc/sysconfig/selinux 设置值: SELINUX=disabled

(7)重启网络
service network restart
(8)通过ifconfig命令查看是否配置成功
(9)重启虚拟机
注:这里我三台虚拟机ip,主机名依次为
192.168.59.223 bigdata-hpsk02.huadian.com 192.168.59.224 bigdata-hpsk03.huadian.com 192.168.59.225 bigdata-hpsk04.huadian.com
安装方式
1.不使用批量安装工具
手动分发,将配置好的第一台hadoop分发到每台机器。这里我使用分发的方式
2.使用批量工具:大数据集群监控运维管理工具CM
CDH:开源软件基础架构Hadoop的服务。
可以在http://archive.cloudera.com/cdh5/cdh/5/下载稳定的版本
部署
在Linux中创建统一的用户,统一的目录
创建用户
useradd username
给用户添加密码
passwd username
创建目录
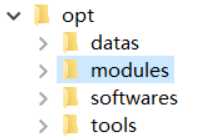
在根目录下创建这四个文件夹,datas放测试数据 softwares放软件安装压缩包 modules软件安装目录 tools开发IDE以及工具 。
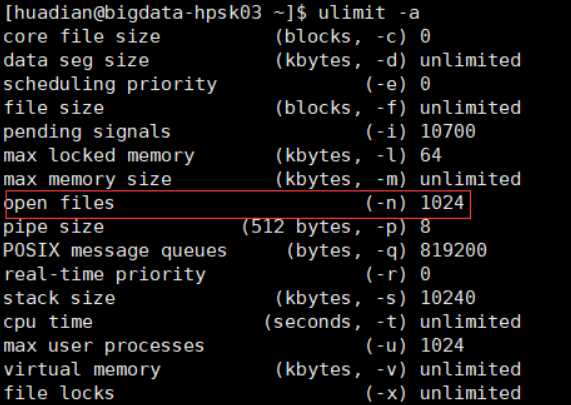
修改句柄数
linux系统都是用文件来表示的,并发调优时修改句柄数时必须的。设置的是当前用户准备要运行的程序的限制。
如果单个进程打开的文件句柄数量超过了系统定义的值因为有时候会遇上Socket/File: Can‘t open so many files的问题
ulimit -a #查看linux相关参数
其中一个方法,是想ulimit修改命令放入/etc/profile里面,但是这个做法并不好
正确的做法,应该是修改/etc/security/limits.conf
sudo vim /etc/security/limits.conf
在文件末尾添加:
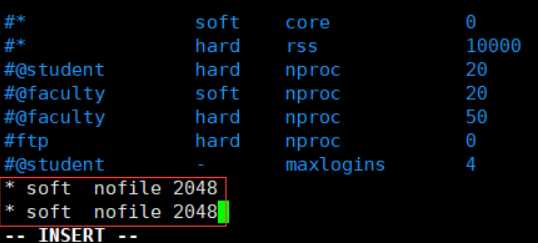
重启机器,查看句柄数
ulimit -n
hadoop启动方式
单个进程启动:用于启动
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
分别启动yarn和hdfs:用于关闭
sbin/start-dfs.sh
-》namenode
-》datanode
-》secondarynamenode
sbin/start-yarn.sh
-》resourcemanager
-》所有的nodemanager
一次性启动所有进程
sbin/start-all.sh
ssh免秘钥登录别的机器启动相应的服务
(1)每台机器为自己创建公私钥
ssh-keygen -t rsa

可以在用户目录下的.ssh文件夹中看到生成的id_rsa id_rsa.pub
(2)每台机器将自己的公钥发给每台机器包括自己
ssh-copy-id 自己的主机名 ssh-copy-id 另外第一台主机名 ssh-copy-id 另外第二台主机名
验证是否3台机器能互相登录成功(为了省事就贴一张图了):

NTP时间同步:通过ntp服务实现每台机器的 时间一致
直接使用ntp服务同步外网时间服务器 -》选择一台机器作为中间同步服务A,A与外网进行同步,B,C同步A -》配置A sudo vim /etc/ntp.conf 删除默认配置: restrict default kod nomodify notrap nopeer noquery restrict -6 default kod nomodify notrap nopeer noquery restrict 127.0.0.1 restrict -6 ::1 server 0.centos.pool.ntp.org server 1.centos.pool.ntp.org server 2.centos.pool.ntp.org -》添加 配置A允许哪些机器与我同步 restrict 192.168.59.0 mask 255.255.255.0 nomodify notrap 配置A跟谁同步 server 202.112.10.36 配置本地同步 server 127.127.1.0 # local clock 注:127.127.1.0 ntp时间服务器的保留ip地址,作用是使用本机作为客户端的时间服务器 fudge 127.127.1.0 stratum 10 -》启动ntp服务 sudo service ntpd start -》配置B,C同步A sudo vim /etc/ntp.conf server 192.168.59.223 -》手动同步 sudo ntpdate 192.168.59.223 -》开启ntp服务 sudo service ntpd start
偷懒做法:
三台机器同时设置时间
sudo date -s "2018-04-27 15:56:00"
安装JDK
(1)上传压缩包到softwares目录下
(2)解压到指定目录
tar -zxvf /opt/softwares/jdk-8u91-linux-x64.tar.gz -C /opt/modules/
(3)分发到第二台,第三台机器
scp -r jdk1.8.0_91 [email protected]:/opt/modules/ scp -r jdk1.8.0_91 [email protected]:/opt/modules/
(4)配置环境变量(每台机器)
vi /etc/profile
进入后在尾部添加
##JAVA_HOME export JAVA_HOME=/opt/modules/jdk1.8.0_91 export PATH=$PATH:$JAVA_HOME/bin
安装hadoop
(1)上传压缩包到softwares目录下

(2)解压到指定目录
tar -zxvf /opt/softwares/hadoop-2.7.3.tar.gz -C /opt/modules/ z:表示gz压缩 x:表示解包 v:表示压缩过程 -C指定解压地址
(3)节点分布
机器1 datanode nodemanager namenode(工作)
机器2 datanode nodemanager nn rm(备份)
机器3 datanode nodemanager resourcemanager(工作)
datanode 存储数据 nodemanager处理数据
本地的Nodemanager优先处理本地的datanode避免了跨网络传输。(Hadoop自己的优化)
namenode resourcenode都是主节点,都需要接收用户的请求,如果都放在机器1上负载比较高,故将他们分布到不同的机器。
(4)修改配置文件
env.sh:配置环境变量
默认会先去全局变量/etc/profile中找JAVA_HOME 但是为了不出现问题在下面三个文件中配置JAVA_HOME环境变量。配置文件在/hadoop2.7.3/etc/hadoop/下hadoop-env mapred-env yarn-env
site-xml:配置用户自定义需求
core-site.xml:配hadoop全局的一些属性
先在hadoop目录下创建临时存储目录,存储元数据

<configuration>
//fs.defaultFS:hdfs的入口 配置第一台机器的入口
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-hpsk02.huadian.com:8020</value>
</property>
//hadoop.tmp.dir hadoop临时存储目录
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.3/tmpData</value>
</property>
</configuration>
hdfs-site.xml:配置hdfs的属性
<configuration>
//dfs.replication:文件副本数
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
//访问权限,不是hdfs同属用户没有权限访问。关闭,让所有人访问hdfs。工作中不能这么配
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml :配置MapReduce
//让MapReduce运行在Yarn上
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
//jobhistory
</configuration>
yarn-site.xml
<configuration>
//指定resourcemanager在哪台机器上运行
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-training03.hpsk.com</value>
</property>
//指定yarn上运行的程序是什么类型
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves:配置所有从节点的地址 (一行一个)
bigdata-hpsk02.huadian.com bigdata-hpsk03.huadian.com bigdata-hpsk04.huadian.com
分发
从第一台机器将hadoop-2.7.3目录分发给另外一台机器
scp -r hadoop-2.7.3 [email protected]:/opt/modules/
或者另一台机器从第一台上下载
scp -r [email protected]:/opt/modules/hadoop-2.7.3 /opt/modules/
注意要改变/opt/modules目录用户权限
启动测试
格式化文件系统,格式化的时候会产生新的元数据,在哪里启动namenode就在哪台机器上进行格式化
bin/hdfs namenode -format
启动对应进程,用单个进程命令
在第一台机器上启动namenode
sbin/hadoop-daemon.sh start namenode
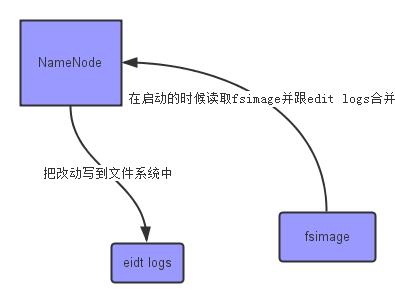
namenode将元数据保存在我们之前在core-site.xml中配置的临时存储目录。里面包含fsimage:文件系统快照 edit logs:对文件系统的改动序列。

注意:不能再第一台机器上执行start-yarn.sh 会默认启动resourcemanager主节点。我们要将resourcemanager在第三台机器上启动。
启动三台机器的datanode
sbin/hadoop-daemon.sh start datanode
在第三台上机器上启动yarn
sbin/start-yarn.sh
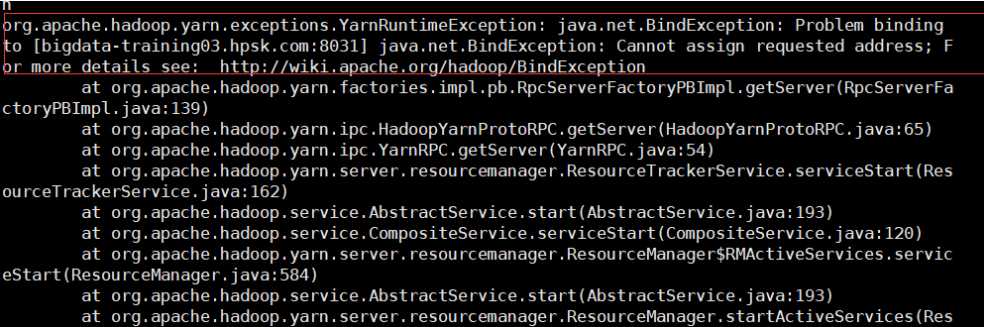
报错了..原因:找不到resourcemanager的主机名。主机名不对。。
yarn-site.xml文件中
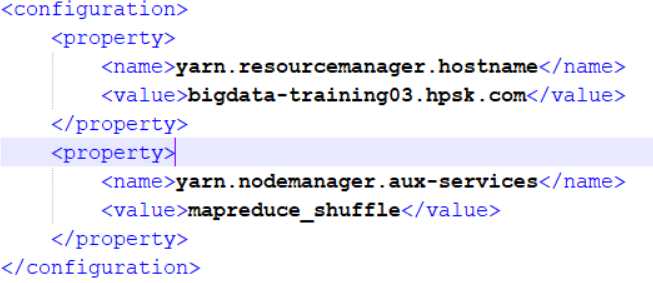
改成第三台的主机名:
bigdata-hpsk04.huadian.com
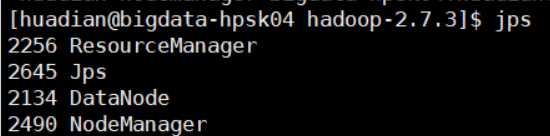
最后查看进程:
第一台机器:
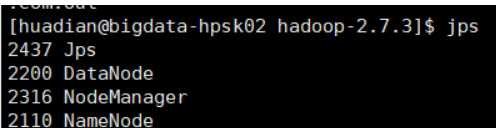
第二台:
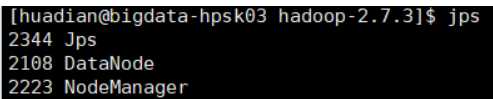
第三台:
? 
到此分布式环境搭建完毕~
在HDFS上创建一个Input目录

新建一个测试文件
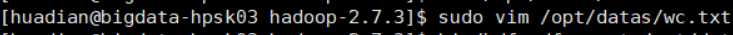
内容:
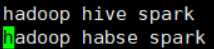
上传到input目录下
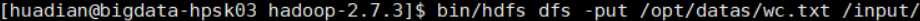
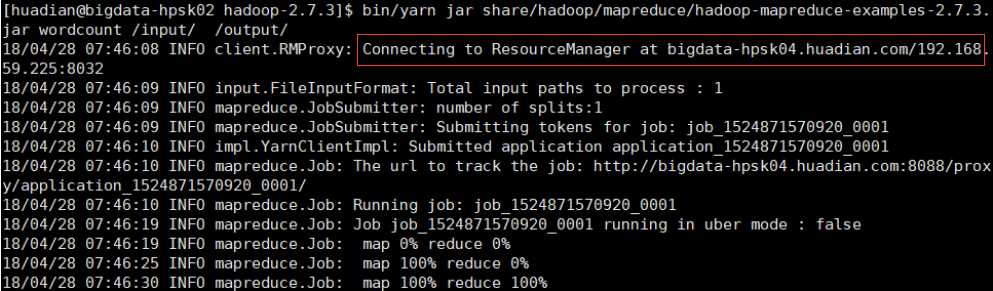
测试wordcount程序,可以看到连接的是第三台,第三台才有resourcemanager
查看结果

停掉所有进程可以用统一的执行命令
第一台机器上执行:
sbin/stop-dfs.sh
关闭所有namenode datanode
第三台机器上执行:
sbin/stop-yarn.sh
关闭所有resourcemanager nodemanager
补充:可以在空闲的机器上启动secondary namenode
以上是关于Hadoop分布式环境部署的主要内容,如果未能解决你的问题,请参考以下文章