redis从入门到踩坑
Posted 少年天团
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis从入门到踩坑相关的知识,希望对你有一定的参考价值。
背景
Redis在互联网项目的使用也是非常普遍的,作为最常用的NO-SQL数据库,对Redis的了解已经成为了后端开发的必备技能。小编对Redis的使用时间不长,但是项目中确两次踩中了Redis的坑,今天特意从基础知识层面到实战层面对Redis知识进行梳理,能够达到对Redis的知识体系有更全面和深入的理解。
Redis的特点
优点:
- Key-Value类型的内存数据库,是加强版的Memcached。
- 整个数据库都是在内存中进行操作的,并且定期异步持久化数据到硬盘上进行保存。
- 在内存中进行操作,不存在磁盘IO,性能方面是非常出色的,读取操作处理速度可以超过10万次每秒,是已知性能最快的Key-Value 数据库。
- Redis还提供丰富的数据结构类型。
- Redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
缺点:
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
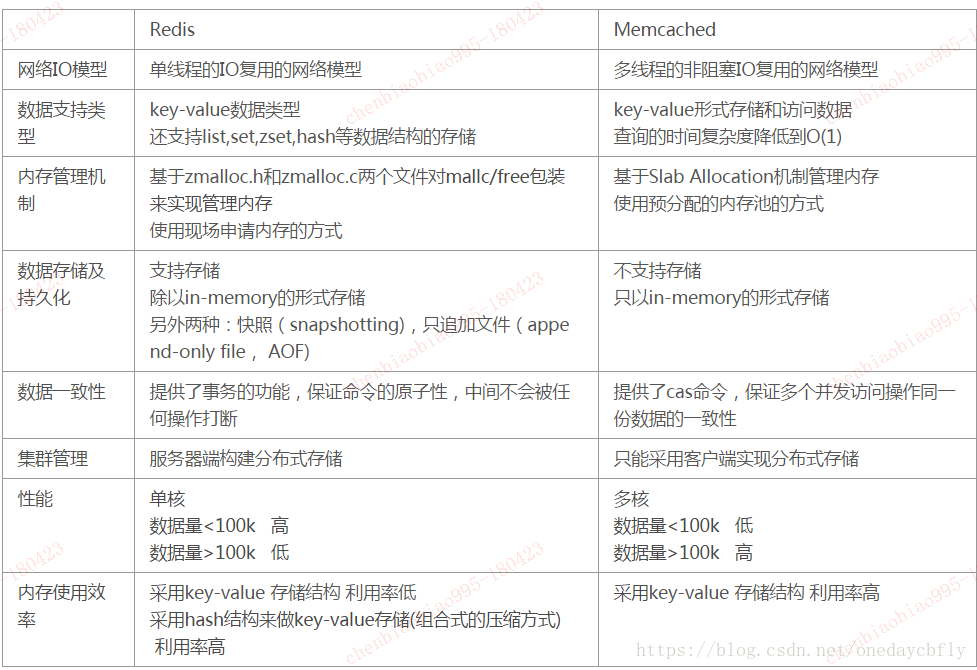
Redis和Memcached的比较
Redis的常用数据结构及使用场景
String
String是Redis最基本的类型,一个key对应一个value,也是最常用的数据结构,在定义每个String的key的时候,记得加上前缀。一个Key最大能存储512MB,一个Value最大能存储1G。
Set
Redis的Set是string类型的无序集合,集合是通过哈希表实现的,所以添加、删除和查找的复杂度都是O(1)。Set集合取交集、差集和并集可以完成两组数据的比较,所以Redis借用Set数据结构常用于两组数据的比较。
ZSet
Redis ZSet和Set一样也是String类型元素的结合,并且不允许重复的成员。不同的是ZSet中每个元素都会关联一个double类型的分数,Redis通过分数(score)为集合中的所有元素进行大小排序。注意ZSet的成员是唯一的,但分数(score)却可以重复。常用语排行榜、分页查询和获取指定范围数据等应用场景。
Hash
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
List
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。常用于构建异步队列。
Redis实现分布式锁
场景:
用户在使用APP的时候,页面非常的卡顿,就会随便狂点,由于接口没有做重复提交,会出现好几个相同的请求,在service层,一个线程没有insert完成,另一个线程一查,空的。于是也插入一条进来。原本每个人一条的,某个业务员出现了三条,导致业务逻辑错误。在业务逻辑中经常会有先查询判空再插入的场景,但是在高并发的时候,很容易出现插入记录重复的情况。
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行互斥控制。但是随着业务发展的需要,原单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁机制常用的有三种方式,redis分布式锁、zookeeper和数据库表。
在这里简单介绍基于redis的分布式锁。
setnx
setnx key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。expire
expire key timeout : 设置key为一个超时时间,单位为second,超过这个时间锁就会自动释放,避免出现由于客户端crash,不释放锁,导致死锁的现象。delete
delete key : 删除key实现思想
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
此处需要补上相关的代码。
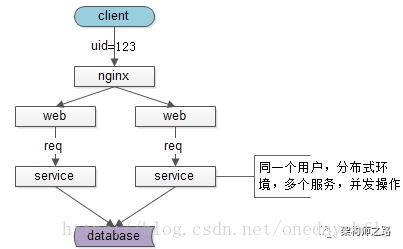
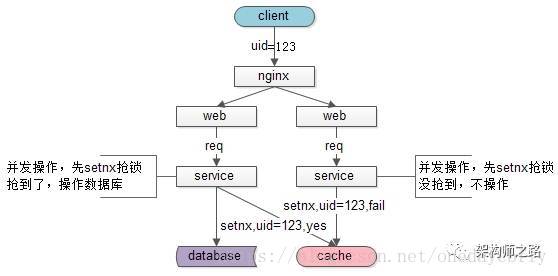
上图所示为采用redis缓存实现分布式系统下,分布式锁的效果图。
序列化和反序列化
实体对象等存入到Redis数据库中,并不是直接存储的,是以byte数组的形式存储的,所以存储到Redis中的时候,需要序列化成byte数据,从Redis读取数据的时候,需要进行反序列化操作。
spring-data-redis包中存在
public interface RedisSerializer<T> {
byte[] serialize(T var1) throws SerializationException;
T deserialize(byte[] var1) throws SerializationException;
}实现此接口的类有如下:
GenericToStringSerializer
可以将任何对象泛化为字符串并序列化StringRedisSerializer
简单的字符串序列化- JdkSerializationRedisSerializer
JDK提供的序列化功能,被序列化的对象必须实现Serializable接口。
优点: 优点是反序列化时不需要提供类型信息(class),并且速度最快。
缺点: 序列化后的结果非常庞大,是JSON格式的5倍左右,这样就会消耗redis服务器的大量内存,且通过redis客户端也不容易阅读。 JacksonJsonRedisSerializer、Jackson2JsonRedisSerializer 和GenericJackson2JsonRedisSerializer
使用Jackson库将对象序列化为JSON字符串。
优点: 速度快,序列化后的字符串短小精悍,并且易于阅读。
缺点: 但缺点也非常致命,那就是此类的构造函数中有一个类型参数,必须提供要序列化对象的类型信息(.class对象)。
项目中Redis的踩坑记
下面分享两个项目中使用Redis时候踩到坑。
坑1
【问题背景】
在生产环境的Redis经常会报出RedisConnectionFailureException: java.net.SocketException: Broken pipe
【异常打印】
11:28:29 INFO - get data from redis, key = c15aad89-4a1a-4cb0-82a5-2027b990c1ca
11:28:29 WARN - /market/info/eForum/getIndexList
org.springframework.data.redis.RedisConnectionFailureException: java.net.SocketException: Broken pipe; nested exception is redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketException: Broken pipe
at org.springframework.data.redis.connection.jedis.JedisExceptionConverter.convert(JedisExceptionConverter.java:67) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.connection.jedis.JedisExceptionConverter.convert(JedisExceptionConverter.java:41) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.PassThroughExceptionTranslationStrategy.translate(PassThroughExceptionTranslationStrategy.java:37) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.FallbackExceptionTranslationStrategy.translate(FallbackExceptionTranslationStrategy.java:37) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.connection.jedis.JedisConnection.convertJedisAccessException(JedisConnection.java:212) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.connection.jedis.JedisConnection.get(JedisConnection.java:1117) ~[spring-data-redis-1.7.3.RELEASE.jar:?]
at org.springframework.data.redis.core.DefaultValueOperations$1.inRedis(DefaultValueOperation【问题原因】
Redis底层也创建了连接池,获取到了失效的连接,并且Redis客户端尝试通过此连接池跟服务端进行通信, 导致抛出上面的异常。
【解决办法】
Redis配置的连接池使用jar包commons-pool-2.4.2.jar方式,其中BaseObjectPoolConfig类为基础配置类。
private boolean testOnCreate = false;
private boolean testOnBorrow = false;
private boolean testOnReturn = false;
private boolean testWhileIdle = false;如上述四个属性参数默认都是false,可以通过修改 testOnBorrow = true 和 testWhileIdle = true 来解决获取无效链接的问题。其中 testOnBorrow = true 是获取链接的时候对链接的有效性进行检查,会影响效率,在高并发的前提下。所以一般只是配置 testWhileIdle = true , 这个是在闲暇的时候进行检查,去除无效的链接。
坑2
【问题背景】
版本日那天提交了代码闲来无事,看到用户信息类UserInfoExt,存储在common的util目录下,有强迫症的我,硬是把它移到了entity包下。以为完美的重构了,没想到挖出了一个巨大的坑。打预发版的包到测试环境,立马所有的已登录用户,都不能进行其他操作。只要切换页面就会抛出“网络服务异常情况”,整个预发版的测试环境被我搞瘫痪了,大家都没法测试。 预发版测试不完成,就没法正常发版,说实话那时候压力还挺大的,全项目的人都盯着你。以后要重构代码,千万别发版前重构,最好是版本迭代开始的前几天就重构好,这样即使重构带来的bug,也有足够的时候去发现和解决。
【异常打印】
19:32:47 INFO - Started Application in 10.932 seconds (JVM running for 12.296)
19:32:50 INFO - get data from redis, key = 10d044f9-0e94-420b-9631-b83f5ca2ed30
19:32:50 WARN - /market/renewal/homePage/index
org.springframework.data.redis.serializer.SerializationException: Could not read JSON: Could not resolve type id ‘com.pa.market.common.util.UserInfoExt‘ into a subtype of [simple type, class java.lang.Object]: no such class found
at [Source: [[email protected]; line: 1, column: 11]; nested exception is com.fasterxml.jackson.databind.exc.InvalidTypeIdException: Could not resolve type id ‘com.pa.market.common.util.UserInfoExt‘ into a subtype of [simple type, class java.lang.Object]: no such class found at [Source: [[email protected]; line: 1, column: 11]
【问题原因】
项目中使用了拦截器,对每个http请求进行拦截。通过前端传递过来的token,去redis缓存中获取用户信息UserInfoExt,用户信息是在用户登录的时候存入到redis缓存中的。根据获取到的用户信息来判断是否存是登录状态。
所以除白名单外的url,其他请求都需要进行这个操作。通过日志打印,很明显出现在UserInfoExt对象存储到redis中序列化和反序列化的操作步骤。
【解决办法】
@Bean
public RedisTemplate<K, V> redisTemplate() {
RedisTemplate<K, V> redisTemplate = new RedisTemplate<K, V>();
redisTemplate.setConnectionFactory(jedisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}查看Redis的Bean定义发现,对key的序列化使用的是StringRedisSerializer系列化,value值的序列化是GenericJackson2JsonRedisSerializer的序列化方法。
其中GenericJackson2JsonRedisSerializer序列化方法会在redis中记录类的class信息,如下所示:
{
"@class": "com.pa.market.common.util.UserInfoExt",
"url": "www.baidu.com",
"name": "baidu"
}"@class": "com.pa.market.common.util.UserInfoExt",每个对象都会有这个id存在(可以通过源码看出为嘛有这个@class),如果用户一直处在登录状态,是以com.pa.market.common.util.UserInfoExt这个路径进行的序列化操作。但是移动了UserInfoExt的类路径后,包全名变了。所以会抛出no such class found的异常。这样在判断用户是否存在的地方就抛出了异常,故而所有的请求都失败了,已经登录的用户没法进行任何操作。
【总结】
对于上面的序列化的坑,貌似没有很好的解决方案。从比较常用的序列化和反序列化类,可以发现每个都有各自的优点和缺点。如果在redis层面把对象转成json,那么每条记录中都会有@class这个标记,如果以后代码重构,移动类路径,肯定是不行的,是个巨坑。如果在入redis之前,就把对象直接转成json,然后用StringRedisSerializer的方式对value进行序列化和反序列化,这样可读性好,也不会跟对象的类路径有强关联。但是需要中间做一道处理,写的时候需要对象转json,读的时候又需要json转对象,会降低效率。
Redis的高级特性
1、集群
2、发布订购
3、持久化
4、Redis服务器如何容灾,如何预防单点故障等
5、读写分离操作
6、异步队列
7、Redis的雪崩和穿透
以上特性有待后续的解锁,敬请期待!
以上是关于redis从入门到踩坑的主要内容,如果未能解决你的问题,请参考以下文章