DynamoDB入门知识和一些注意事项
Posted 天书说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DynamoDB入门知识和一些注意事项相关的知识,希望对你有一定的参考价值。
什么是DynamoDB
Amazon DynamoDB分布式NoSQL数据库服务,支持动态扩展,性能可靠
DynamoDB基本概念
DynamoDB的组成
- 表:表示用来存储DynamoDB数据,它类似于关系型数据库的“表”
- 项目:表中可以有0 到 N(N > 0)个项目,它类似于关系型数据库的“行”,在DynamoDB中,项目数量是没有限制的。
- 属性:多个属性组成了一个项目,它类似于关系型数据库中的“字段”。DynamoDB中表除了主键外都是无架构的,因此在项目里可以有不同的属性、大小、数据类型
DynamoDB主键
DynamoDB中使用主键标识唯一的项目,在创建表时必须指定主键。DynamoDB主键支持两种类型
- 单个分区键组成的主键:由一个分区键属性组成,他标识了唯一的项目,同时也觉得项目存储到哪个分区。DynamoDB根据内部散列函数计算分区键的值,其结果用来决定将项目存储到哪个分区。
- 分区键 + 排序键:在单个分区键基础上加上排序键,由这两个属性组成复合主键。同样,分区键决定项目存储到哪个分区,排序键决定在同一个分区内相同分区键的项目的排列顺序。
DynamoDB流
DynamoDB流可以捕获表中的数据修改事件,这些事件以发生的顺序写入到流中。流有生命周期,从计入到结束一共有24小时,到期后将从流中自动删除。
以下几个事件将触发流的产生
- 向表添加新项目时,此时流会捕获整个项目即所有属性
- 更新项目时,此时流将波或项目中已修改的属性
- 删除项目时,流在项目被删除前捕获
DynamoDB二级索引
DynamoDB提供了本地二级索引和全局二级索引,二者有一定的差异。
| 本地二级索引 | 全局二级索引 | |
| 概念 |
本地二级索引的含义是“本地”,意思是说二级索引的索引范围限定为具有相同分区键的表分区。 也就是说该索引只能在同一个分区中索引 |
全局是指对索引执行的查询可以跨基表中所有分区的所有数据 |
| 一致性 | 支持强一致性 | 仅支持最终一致性 |
| 限制 | 一个表中只能创建5个本地二级索引 | 一个表中只能创建5个全局二级索引 |
DynamoDB读写限制
在创建表时需指定表的读取、写入的吞吐量。在生产环境中如果实际吞吐量超过了当前为DynamoDB设置的吞吐量,在经过重试后(如果DynamoDB Client设置了重试机制)最终将会抛出异常。
- 读取吞吐量单位:读取吞吐量取决于项目的大小以及是需要最终一致性还是强一致性
最终一致性的读取容量单位 = 2次4KB项目读 / 秒
强一致性的读取容量单位 = 1次4KB读 / 秒
如果一次读取大于4KB的项目,DynamoDB要消耗额外的读取容量单位。 - 写入吞吐量单位:写入容量单位取决于写入项目的大小。
一个写入容量单位 = 1次最多1KB的项目写入 / 秒
如果需要写入大于1KB的项目,DynamoDB需要消耗额外的写入容量单位。 - 其他限制:DynamoDB规定一个项目大小上限为400KB,如果项目的大小超过了这个限制将会消耗更多的容量单位。
一旦超过DynamoDB的限制,那么请求会被限制,这种错误在程序中是无法自动恢复的,因此需要合理设置吞吐量和一个项目大小。
DynamoDB吞吐量预置值计算
吞吐量在创建表时候可以指定,在运行中的线上业务也可以通过DynamoDB后台可视化界面或提供的API动态调整。API方式相对来说非常灵活。注意:DynamoDB每天每个表仅允许向下调整4次,向上调整无限制。
这个预置值有一套计算方式,如果您的业务读写量可预估那么请参考下面公式
- 强一致性读取容量计算:向上取整(项目大小 / 4KB) * 预计每秒读取个数
比如:强一致性读要求,一个项目大小为3KB,期望每秒读80个项目。
3KB / 4KB = 0.75 ,向上取整后 = 1
1 * 80 = 80个读取容量单位 - 最终一致性读取容量计算:与强一致性读取容量计算方式一样,在最终结果上 * 2
- 写入容量计算:向上取整(项目大小 / 1KB) * 预计每秒写入个数
比如:项目大小为512字节,期望打到每秒写入100个项目。
512字节 / 1KB = 0.5 向上取整 = 1
1 * 100 = 100个写入容量单位
DynamoDB分区
初始分区数计算
在数据存储时,DynamoDB会将表的项目划分至多个分区,并由SSD支撑。数据的分布主要是根据分区值决定。
DynamoDB服务全权负责分区的管理,包括起始表分区个数、分区拆分。
首先我们需要知道,在DynamoDB中一个分区大约可保存10GB的数据,最多支持每秒3000个读请求和每秒1000个写请求。
在创建一个表时,会根据预置的读写吞吐量初始化表分区个数,计算公式如下:
初始化分区个数 = 向上取整( (读取预设吞吐量 / 3000) + (写入预设吞吐量 / 1000) )
比如:读取预设5000,写入预设2000,那么套用公式(5000 / 3000) + (2000 / 1000) = 3.6667 向上取整后 = 4个分区数
那么每个分区的可以支持5000 / 4 = 1250个读和(2000 / 4) = 500个写
分区拆分
DynamoDB是可以动态扩容的,吞吐量也可以保证。但这些都是基于它的分区设计。
分区拆分方式
既然是DynamoDB全权负责分区管理,那么分区拆分的时机和方式由DynamoDB决定。当必要的时候DynadmoDB会自动拆分现有的分区,以提供更多的分区以支持吞吐量。我们首先了解拆分的方式

- 图中第1步,DynamoDB会分配两个新分区
- 图中第2步,DynamoDB将原分区数据均匀分配到新分区
- 图中第3步,DynamoDB不再给原分区分配数据
分区拆分触发条件
上面提到,“在DynamoDB中一个分区大约可保存10GB的数据,最多支持每秒3000个读请求和每秒1000个写请求”
那么分区触发条件也是围绕着分区实际存储量和读写来触发的。
- 预置吞吐量增加:如果当前分区表不能满足新的预置吞吐量时,DynamoDB会将当前的分区数量扩充一倍
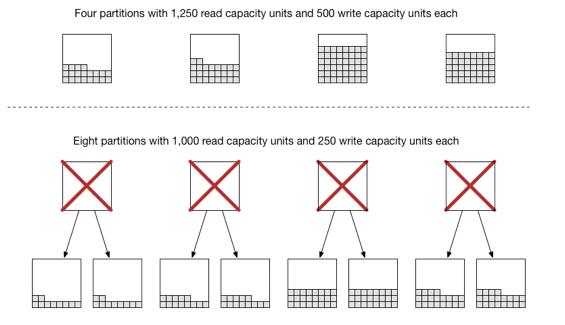
图中表示的是,起初表分配了4个分区(读取预设5000,写入预设2000,那么套用公式(5000 / 3000) + (2000 / 1000) = 3.6667 向上取整后 = 4个分区数)
每个分区有1250个读取单元和500个写入单元,此时将读容量从5000调整到8000时,此时4个分区不能满足了,DynamoDB将分区数翻倍 4 * 2 = 8个分区,因此每个分区酱油1000个读取单元和250个写入单元 - 存储要求增加:如果某个分区数据超过了限制的10G,DynamoDB将把这个分区拆成两个,并且数据平均分配到新的两个分区中。造成某个分区超过限制10G的原因有很多,其中比较常见的就是分区键散列度不够,导致数据偏移到某一个分区。
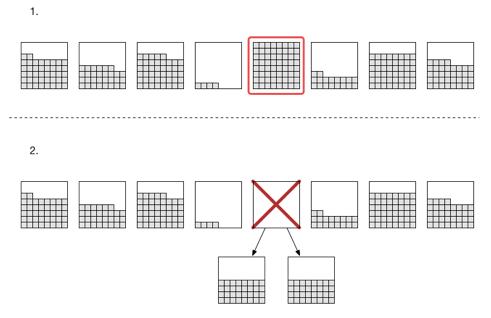
如图,红框分区填满数据后,DynamoDB将把这个分区拆出两个新分区,在拆之前,总容量上限为8个分区 * 10GB容量 = 80GB,拆后总容量上限为9个分区 * 10GB容量 = 90GB
注意:这种从分区拆出的两个分区只会共享原分区的读写吞吐量。举个例子:
5000读和2000写,DynamoDB此时创建4个分区,每个分区读写容量为
5000 / 4 = 1250读取容量
2000 / 4 = 500 写入容量
假设其中一个分区即将满10G,DynamoDB会将这个分区拆出两个分区,此时这个表共有5个分区,他们的写入容量分别为
其中3个分区读写容量依然是1250读取容量和500写入容量,被拆出的两个分区读写为1250 / 2 = 625读取和500 / 2 = 250写入
参考:https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/Introduction.html

以上是关于DynamoDB入门知识和一些注意事项的主要内容,如果未能解决你的问题,请参考以下文章