mysql 索引
Posted SSSupreme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 索引相关的知识,希望对你有一定的参考价值。
索引是一种数据结构.
主要功能:
-加速查找
-约束
为什么索引快?
因为特殊的数据结构够,为某个字段创建索引后,会创建一个特殊的数据结构表,mysql里面支持B-tree 索引,感兴趣的可以去看一下,关于数据结构就不多介绍,知道的就是如果有1000个数据,顺序查找,最快1次,最多1000次,用B-tree索引的话最多次数可能就只有10次.极大的加快了查找速度.
索引的种类
普通索引---唯一功能:加速查找
唯一索引--加速查找,约束列不能重复.可以为null
主键索引--加速查找,约束列不能重复,不能为null
组合索引--加速查找,多列可以创建一个索引文件.
创建普通索引:
--在创建表的时候直接创建 CREATE table t1( nid int auto_increment primary key, name varchar(16), age int, index ix_name(name)-- 通过 index 规定name 为普通索引 )engine=innodb default charset=utf8; -- 后添加 CREATE index ix_name on t1(name); -- 代价,索引会单独创建一个数据结构表,当我们创建表的时候,表为空,我们进行增删改的时候,都需要对2个表进行操作,导致速度下降. -- 所以综上所述,如果表需要的数据量大,而且增删相对不那么频繁,可以加入索引,如果数据量少,增删频繁,不适合创建索引. -- 查看索引 show index from 表;
唯一索引:
将index 改成unique
--在创建表的时候直接创建 CREATE table t1( nid int auto_increment primary key, name varchar(16), age int, unique ix_name(name)-- 通过 index 规定name 为普通索引 )engine=innodb default charset=utf8; -- 后添加 CREATE unique ix_name on t1(name);
主键索引
不能重复,不能为空.
一般情况下,默认创建表的时候,就让主键为一个索引.
所以创建表的时候,只要是主键,就已经有了主键索引
create table profile( nid int auto_increment primary key,--这里就是一个主键索引了 name varchar(16), gender varchar(2), ) 或者 create table profile( nid int auto_increment , name varchar(16), gender varchar(2), primary key(nid) ) 或者后天添加: alter table 表 add primary key(列名字);
组合索引
----普通组合索引 create index on 表(列,列);
----联合唯一索引 create unique on 表(列,列);
查找的时候遵循,最左匹配
比如让name 字段和age字段组合索引,--create index on t(name,age);
select * from t where name=\'xxx\'------走索引
select * from t where name=\'xxx\' and age=1------走索引
select * from t where age=1------不走索引
实际中的索引:
-覆盖索引
仅仅是个名词,代表的是直接从索引表里面就能获取数据的查找模式.
上面我们说了在创建索引的时候会单独创建一个特殊数据结构的索引表,如果我们把nid创建了索引,查找语句是
select * from t where nid=1; 这个查找就是需要去索引表里面找到nid=1,再去真实的数据库中取出该列;
如果是
select nid from t where nid <10; 这个查找我们只需要nid 的值,所以不用第二次的去数据库表中获取,这种就叫覆盖索引;
-合并索引:
我们有字段 name(index) age(index)都设置了索引.
如果查询语句是
select * from t where name=\'xxx\' age=1;
这种需要2个索引表的就叫合并索引.
好处是解决了联合索引的最左匹配.短板就是增加了一个表占用硬盘空间],增删改的时候加大了消耗.
执行计划--相对准确的表达出当前sql的运行状况
查看是否走了索引:
explain 关键字;
加入到查找的sql 前面
explain select * from t where nid<10;
结果:

查看下执行情况,这个执行情况也不一定准确,主要看type 和要执行的行数 rows;
type
all 代表全表扫描,有优化的余地
index 全索引表扫描,有优化的余地
range 就是范围扫描,走索引,注意:当范围索引查找的时候是> 或者!= 可能不会走索引的.
index_merge 合并索引,走索引.
ref 根据索引查找一个或多个值
eq_ref 连接时使用primary key 或 unique类型
const 表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。
system 表仅有一行(=系统表)。这是const联接类型的一个特例。
上面的执行速度从低到高.
正确使用索引
我们创建了索引,但是某些操作会让查询走不了索引
1.like "%xx" --通配符在前面,不走索引 like \'xx%\'走索引. 2.使用函数对查询的列进行转换后,是不会走索引的; select * from t where f(xx)=\'xxx\'; 3.or 条件中有不是索引的列,不走索引 nid 是索引,name 不是 select * from t where nid=1 or name=\'xxx\' 4.查询类型不一致的时候不走索引 select * from t where name=111; 5.!= 对于普通索引不走索引,但是主键索引会走索引. 6.> 对于普通索引不走索引,主键走索引,但是如果类型是int,走索引. 7.组合索引,最左匹配.
其他的:
少使用*, select * 或者 count(*),尽量避免 能用定长char 就不用变长varchar. 能用组合索引就别用单个索引. 用短索引 :CREATE index xx on t (name(3));制定name字段的前3个长度制定索引.
分页:
如果当数据特别多的时候
nid建立了主键索引
我们用select * from t limit 10000,10;
这条语句的执行就是扫描前面10000个数据,吧9990-10000的数据拿出来,前面的9990条就白扫描了.所以效率低,建立了索引也没啥用.
解决办法:
1.使用覆盖索引. ---扫描索引表,效率高一些.
select nid from t limit 10000,10; 先拿到nid 然后select * from t where nid in (select nid from t limit 10000,10);
2.限制用户查询,跳转.
如果我们知道是要查9990到10000,可以 select * from t where nid>9990 limit 10000,10;这样就会跳过前面9990 行,然后开始查找.
问题是这种方式只使用与nid 有序增加的.如果nid 是1,2,12,122,1222这种序列.就不使用了.
3.思考其他解决方式:可以在具体实际使用中加入记录上一页的末尾的值.
比如第一次分页的时候是20-30, 下一次分页的时候,我们先获取到30这个值,加入到where条件中,这样每次就能只扫描想要的个数了.
这个方式在具体的网页分页中,可以设置一个全局变量 current_last_index=0,
每次分页的时候,获取到最后一次的nid =current_last_index.
下一页查询的时候就用select * from t where nid>current_last_index limit current_last_index,10;
上一页操作的时候,用nid<current_last_index,然后将它倒叙desc,,然后再用limit取值.,或者再加入一个变量current_first_index,来记录上一次分页的最开始的nid值.
这种方式只使用与只有上一页,下一页button 的情况,如果是1,2,3...末页 这种级需要考虑在每个页面上加上变量去记录nid的范围,第一次加载的时候就赋值好,并存入缓存.第一次加载时间开销会大,后面每次点击的时候就快了.
具体的设计就看具体情况了,思路是这样,
慢日志的配置:
实际运用中,我们可以记录查询比较慢的语句并记录,方便后面修改:
slow_query_log = OFF 是否开启慢日志记录 long_query_time = 1 时间限制,超过此时间,则记录 slow_query_log_file = /usr/slow.log 日志文件 log_queries_not_using_indexes = OFF 没有命中索引的语句是否记录
查看mysql配置文件:
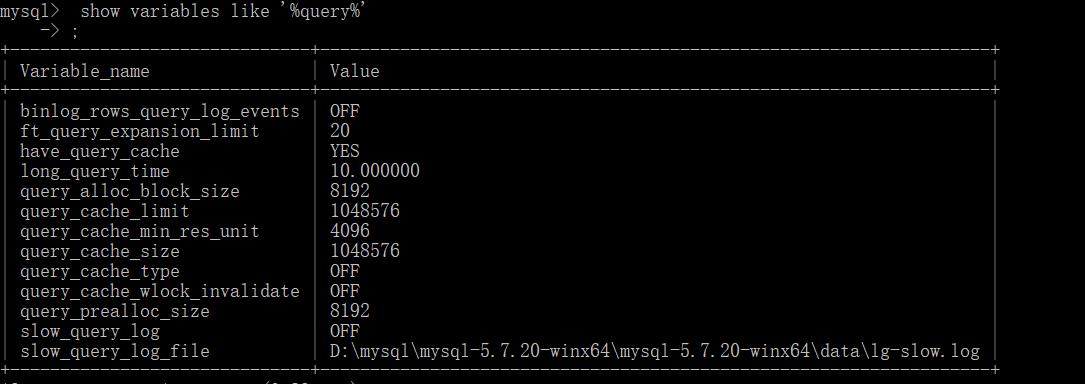
修改值配置文件值: set global 变量名 = 值
文章索引内容查看自http://www.cnblogs.com/wupeiqi/articles/5716963.html,感谢大神提供.
以上是关于mysql 索引的主要内容,如果未能解决你的问题,请参考以下文章