集合操作 用单链表模拟有序集合,实现集合的加入一个元素、删除一个元素、集合的交、并、差运算。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集合操作 用单链表模拟有序集合,实现集合的加入一个元素、删除一个元素、集合的交、并、差运算。相关的知识,希望对你有一定的参考价值。
集合操作 用单链表模拟有序集合,实现集合的加入一个元素、删除一个元素、集合的交、并、差运算。(1)用单链表存放集合中的元素,链表中的元素按大小存放;(2)实现集合加入一个元素删除一个元素的元素操作;(3)实现集合的交、并、差集合操作;
#include <iostream>using namespace std;
typedef struct Element
Element* next;
int value;
Element,*Link,*Position;
class SortedUnion
private:
Link sorted_link;
public :
SortedUnion()
//创建单链表的头节点
sorted_link = (Link)malloc(sizeof(Element));
sorted_link->next = NULL;
void addValue(int value)
Position pos = insertPosition(value);
if(pos!=NULL)
Link tmp = (Link)malloc(sizeof(Element));
tmp->value = value;
tmp->next = pos->next;
pos->next = tmp;
void deleteValue(int value)
Position pos,pre=sorted_link;
for(pos=sorted_link->next; pos; pos=pos->next)
if(pos->value == value)
pre->next = pos->next;
free(pos);
break;
pre = pos;
Position insertPosition(int value)
Position pos;
for(pos = sorted_link; pos->next; pos=pos->next)
if(pos->next->value > value)
break;
if(pos->next->value == value)
return NULL;
return pos;
void print()
Link ptr;
for(ptr=sorted_link; ptr->next; ptr=ptr->next)
cout << ptr->next->value << " ";
friend SortedUnion Intersection(SortedUnion A, SortedUnion B)
SortedUnion C;
Position posA = A.sorted_link->next, posB = B.sorted_link->next;
while(posA && posB)
if(posA->value < posB->value)
posA = posA->next;
else if(posB->value < posA->value)
posB = posB->next;
else
C.addValue(posA->value);
posA = posA->next;
posB = posB->next;
return C;
;
int main()
SortedUnion u1,u2,u3;
u1.addValue(2);
u1.addValue(3);
u1.addValue(1);
u1.addValue(4);
u2.addValue(1);
u2.addValue(2);
u3 = Intersection(u1, u2);
u3.print();
参考技术A ,,, 参考技术B 数据结构与C语言综合训练实习 1 序号 项目名称 任务描述 指导教师 1 英文文本压缩 问题描述利用哈夫曼编码实现英文文本的压缩和解压缩。基本要求对于给定的英文文本可以根据其频度进行哈夫曼编码并能输出对应的哈夫曼树和哈夫曼编码实现哈夫曼解码。提高要求1能够分析文件统计文件中出现的字符统计字符出现的概率再对文件进行编码实现文件的压缩和解压缩。2能够对于文件的压缩比例进行统计。 2 文本编辑系统 1分别统计出其中英文字母数和空格数及整篇文章总字数2统计某一字符串在文章中出现的次数并输出该次数3删除某一子串并将后面的字符前移。 3 简单算术表达式运算 给定简单的算术表达式包括加减乘除括号这几种运算操作符请计算表达式的值。1能够正确处理加减乘除这四种运算2能够正确处理括号运算。 4 小学生测验系统 面向小学12年级学生随机选择两个整数和加减法形成算式要求学生解答。功能要求1电脑随机出10道题每题10分程序结束时显示学生得分2确保算式没有超出12年级的水平只允许进行50以内的加减法不允许两数之和或之差超出050的范围负数更是不允许的3每道题学生有三次机会输入答案当学生输入错误答案时提醒学生重新输入如果三次机会结束则输出正确答案4对于每道题学生第一次输入正确答案得10分第二次输入正确答案得7分第三次输入正确答案得5分否则不得分5总成绩90以上显示“SMART”80-90显示“GOOD”70-80显示“OK”60-70显示“PASS”60以下“TRY AGAIN”。 5 数字游戏的设计 实现一个简单的猜数字游戏1一个四位数各位上的数字不重复从1到9。2按以下提示猜出这个四位数。 3每次猜测输入的数据给出类似的提示AB。4其中A前的代表你本次猜对了多少个数字。 5其中B前的代表你本次猜对的数字并且位置正确的个数。6给定猜测次数如果超过次数未猜中游戏失败。 6 学生成绩管理程序 设计一个简单的学生成绩管理程序要求根据菜单处理相应功能。1管理功能包括列表、求平均成绩、查找最高分等。2可按指定的性别或高于指定的个人平均分来筛选列表3可按平均成绩排序4平均成绩可按个人或科目进行5查找可按最高个人平均分进行或按指定科目的最高分进行6每个学生的信息包括序号、学号、性别、成绩1、成绩2、 数据结构与C语言综合训练实习 2 成绩3、成绩47基本功能为建立文件、增加学生记录、新建学生信息文件、删除/修改学生记录。 7 图书登记管理程序 该程序应该具有下列功能1 通过键盘输入某本图书的信息2 给定图书编号显示该本图书的信息3 给定作者姓名显示所有该作者编写的图书信息4 给定出版社显示该出版社的所有图书信息5 给定图书编号删除该本图书的信息6 提供一些统计各类信息的功能。 8 集合操作 用单链表模拟有序集合实现集合的加入一个元素、删除一个元素、集合的交、并、差运算。1用单链表存放集合中的元素链表中的元素按大小存放2实现集合加入一个元素删除一个元素的元素操作3实现集合的交、并、差集合操作 9 树的重构和遍历系统 系统菜单信息输入、输出遍历。 10 个人关系网的设计与实现系统 系统菜单信息输入、输出建图、查询。 11 简单栈和队列演示系统的设计与实现 系统菜单信息输入、输出。 12 按每个数的各位值进行排序的系统 系统菜单信息输入、输出排序。 13 学生基本信息管理系统 系统菜单信息输入、输出查询。 14 身份证管理程序 该程序应该具有下列功能1 通过键盘可以输入身份证信息大量信息可存放在文件中。身份证包含的信息请参看自己的身份证2 给定身份证号码显示其身份证信息3 给定省份的编号显示该省的人数4 给定某区的编号显示该区的人数5 给定身份证号码可以修改该身份证信息6 给定身份证号码可以删除该身份证信息。 15 学生宿舍管理查询软件 设计一个简单的学生宿舍管理查询程序要求根据菜单处理相应功能。1建立数据文件 数据文件按关键字姓名、学号、房号进行排序 2查询菜单: 可以用二分查找实现以下操作A. 按姓名查询 B. 按学号查询 C. 按房号查询等3可以打印任一查询结果4每个学生的信息包括序号、学号、性别、房号、楼号等。 数据结构与C语言综合训练实习 3 16 万年历查询程序 实现万年历程序功能要求1提供菜单方式选择假定输入的年份在1940-2040年之间。2输入一个年份输出是在屏幕上显示该年的日历。3输入年月输出该月的日历。如4输入年份、月份、日期计算得到的是这一天据今天有多少天星期几5输入公历的年月日输出农历年月日。6输入农历节气输出当年农历的年月日及公历年月日。可以假定只涉及年份是1940年到2040年。 17 二叉树遍历算法的实现 四种算法都是前序、中序、后序三种算法要求递归和非递归实现层遍历用非递归实现。 18 二叉排序树的实现 要求分别以顺序表和二叉链表作为储结构实现二叉排序树。基本操作有插入、删除。 19 管道铺设施工的最佳方案选择 功能设计一个最佳方案使得这N个居民区之间铺设煤气管道所需代价最少。 20 数组编码和解码问题的求解设计与实现 设有一个数组A: array0..N-1存放的元素为0-N-11ltNlt10之间的整数且不存在重复数据。例如当N6时有A430512。此时数组A的编码定义如下:A0编码为0Ai编码为在A0A1�6�7Ai-1中比Ai的值小的个数i12�6�7N-1上面数组A的编码为B000312要求如下给出数组A 利用C 求解A的编码.给出数组A的编码后求出A中原数据。 21 简易文本编辑器的设计与实现 功能具有图形菜单界面查找、替换、块移动行块列块移动、删除具有基本功能。 22 利用哈希表实现电话号码查找系统 功能建立哈希表。选择不同的哈希函数选择不同的解决冲突的办法。 23 迷宫问题求解 要求对任意设定的迷宫求出一条从入口到出口的通路或得出没有通路的结论。 24 排序算法综合 功能数据随机生成五种常用排序算法实现从时间上分析效率并比较。 25 简易通讯录的制作 功能输入信息 显示信息 查找以姓名作为关键字 删除信息 存盘 装入。 数据结构与C语言综合训练实习 4 26 图的遍历的实现 功能实现图的深度优先 广度优先遍历算法并输出原图结构及遍历结果。 27 稀疏矩阵运算器的设计与实现 功能压缩存储矩阵的基本运算加、乘、求逆常规矩阵方式输出。 28 小学生作业题练习系统利用堆栈实现 功能建立试题库文件随机产生n个题目 题目涉及加减乘除带括弧的混合运算给出分数判定 随时可以退出 保留历史分数能回顾历史根据历史分数给出评价。 29 一元多项式的加法、减法、乘法的实现 要求判定是否稀疏分别采用顺序和链式存储结构实现结果Mx中无重复阶项和无零系数项要求输出结果的升幂和降幂两种排列情况 30 邻接表克鲁斯卡尔算法的实现 要求根据需要建立图的邻接表存储结构构造最小生成树模拟演示生成过程。 31 期刊论文管理程序 该程序应该具有下列功能1 通过键盘输入某期刊论文的信息也可以把大量期刊论文信息放在文件中2 给定期刊论文的论文名称显示该论文的作者信息作者单位发表期刊的名称3 给定作者姓名显示所有该作者发表的期刊论文情况4 给定期刊名称显示该期刊的所有论文信息 32 字符串操作 编写程序不使用标准库函数实现字符串的拷贝、拼接、字串查找、长度计算等函数。1在不使用相关的标准库函数的情况下完成本任务2实现两个字符串拼接的函数strcatstr1 str23实现字符串拷贝的函数strcpystr1str24实现字符串查找的函数strcstrstr1str25实现字符串长度计算的函数strlenstr16实现字符串查找字符的函数strccharstr1c7实现字符串替换的函数strcreplacestrstr1str2str38实现字符串替换字符的函数strcreplacecharstr1str2c 33 单源最短路径求解 给定一个带权有向图GVE其中每条边的权是一个非负实数。另外还给定V中的一个顶点成为源。现在计算从源到其他各顶点的最短路径。路径的长度是指路上各边权值之和。 34 歌手比赛系统 设计一个简单的歌手比赛绩管理程序对一次歌手比赛的成绩进行管理功能要求1.输入每个选手的数据包括编号、姓名、十个评委的成绩根据输入计算出总成绩和平均成绩去掉最高分去掉最低分。2.显示主菜单如下1输入选手数据 2评委打分 3成绩排序按 数据结构与C语言综合训练实习 5 平均分4数据查询 5追加学生数据 6写入数据文件7退出系统 35 找数字对 输入N2ltNlt100个数字在0与9之间然后统计出这组数种相邻两数字组成的链环数字对出现的次数。例如 输入N20 表示要输入数的数目 0 1 5 9 8 7 2 2 2 3 2 7 8 7 8 7 9 6 5 9 输出782 873指78、87数字对出现次数分别为2次、3次 36 二叉树遍历算法的实现 四种算法都是前序、中序、后序三种算法要求递归和非递归实现层遍历用非递归实现。 37 中文文本压缩 问题描述利用哈夫曼编码实现中文文本的压缩和解压缩。基本要求对于给定的中文文本可以根据其频度进行哈夫曼编码并能输出对应的哈夫曼树和哈夫曼编码实现哈夫曼解码。提高要求1能够分析文件统计文件中出现的字符统计字符出现的概率再对文件进行编码实现文件的压缩和解压缩。2能够对于文件的压缩比例进行统计。 38 邻接矩阵普利姆算法的实现 要求根据需要建立图的邻接矩阵存储结构构造最小生成树模拟演示生成过程。 39 邻接矩阵克鲁斯卡尔算法的实现 要求根据需要建立图的邻接矩阵存储结构构造最小生成树模拟演示生成过程。 40 n元多项式乘法 1 界面友好函数功能要划分好 2 总体设计应画一流程图 3 程序要加必要的注释 4 要提供程序测试方案 5 程序一定要经得起测试宁可功能少一些也要能运行起来不能运行的程序是没有价值的。 41 学生成绩管理程序 设计一个简单的学生成绩管理程序要求根据菜单处理相应功能。 1管理功能包括列表、求平均成绩、查找最高分等。 2可按指定的性别或高于指定的个人平均分来筛选列表 3可按平均成绩排序 数据结构与C语言综合训练实习 6 4平均成绩可按个人或科目进行 5查找可按最高个人平均分进行或按指定科目的最高分进行 6每个学生的信息包括序号、学号、性别、成绩1、成绩2、成绩3、成绩4 7基本功能为建立文件、增加学生记录、新建学生信息文件、删除/修改学生记录。 42 数组操作 设计菜单处理程序对一维数组进行不同的操作。 1操作项目包括求数组最大值、最小值、求和、求平均值、排序、 二分查找、有序插入 2设计并利用字符菜单进行操作项目的选择程序一次运行可根据选择完成一项或多项操作通过菜单“退出”来结束程序的运行 3数组的输入、输出可支持命令行输入文件名、界面输入文件名从数据文件中输入和输出也支持界面录入。 43 打印日历表 打印指定年份的公历表和农历表。 1输入年份为19902050内任一年 2可以选择输出公历表或农历表 3农历表包括二十四节气。 44 学生证管理程序 该程序应该具有下列功能 1 通过键盘输入某位学生的学生证信息。学生证包含的信息请参看自己的学生证 2 给定学号显示某位学生的学生证信息 3 给定某个班级的班号显示该班所有学生的学生证信息 4 给定某位学生的学号修改该学生的学生证信息 5 给定某位学生的学号删除该学生的学生证信息 6 提供一些统计各类信息的功能。 45 图书登记管理程序 该程序应该具有下列功能 1 通过键盘输入某本图书的信息 2 给定图书编号显示该本图书的信息 3 给定作者姓名显示所有该作者编写的图书信息 4 给定出版社显示该出版社的所有图书信息 数据结构与C语言综合训练实习 7 5 给定图书编号删除该本图书的信息 6 提供一些统计各类信息的功能。 46 学生学分管理程序 假设每位学生必须完成基础课50学分、专业课50学分、选修课24学分、人文类课程8学分、实验性课程20学分才能够毕业。因此在管理学分时要考虑每个学分所属于的课程类别。 该程序应该具有下列功能 1 通过键盘输入某位学生的学分 2 给定学号显示某位学生的学分完成情况 3 给定某个班级的班号显示该班所有学生学分完成情况 4 给定某位学生的学号修改该学生的学分信息 5 按照某类课程的学分高低进行排序 6 提供一些统计各类信息的功能。 47 作业完成情况管理程序 假设某门课程一学期要留10次作业每次老师要进行批改给出分数后还要进行登记。学期期末要根据每次作业的成绩计算出最终的平时成绩满分100。 该程序应该具有下列功能 1 通过键盘输入某位学生某次作业的分数 2 给定学号显示某位学生作业完成情况 3 给定某个班级的班号显示该班所有学生的作业完成情况 4 给定某位学生的学号修改该学生的作业完成信息 5 给定某位学生的学号删除该学生的信息 6 提供一些统计各类信息的功能。 48 旅店POS机管理系统 旅店收款POS机管理系统的简单实现。 1前台管理包括空房分等级显示、入住登记、退房结算、洗衣房管理、娱乐项目管理 2后台管理包括客房预定分析、营业额统计、日报表、月报表、年报表 3设计数据结构文件来实现数据库管理包括数据录入、查询、删除、修改、更新。 49 学生通讯录管理系统 用链表方式来实现学生通讯录管理系统。 1通过定义一个包含学生通讯录主要包括学号、姓名、系别、专业、籍贯、家庭住址、 数据结构与C语言综合训练实习 8 联系电话等的结构体类型实现增加学生通讯录的内容、删除某个学生通讯录、输出全部学生通讯录内容、根据用户需求查找某个或某些学生的通讯录内容如按系别、专业、学号、姓名等内容进行查找。 2能够实现以上给定的各项功能具有方便简洁的操作界面具有一定的容错性。 50 超长正整数的乘法 设计一个算法来完成两个超长正整数的乘法。 算法提示 首先要设计一种数据结构来表示一个超长的正整数然后才能够设计算法。 51 个人电话号码查询系统 问题描述实现简单的个人电话号码查询系统根据用户输入的信息如姓名身份证号电话号码、邮件地址等进行快速查询。 基本要求 1 插入实现将用户的信息插入到系统中2 删除删除某个用户的信息3 修改修改某个用户的信息4 查询根据姓名、身份证号等查询用户信息包括简单条件查询组合条件查询、模糊查询等5 排序对于用户信息进行排序提高查询速度6 输出输出用户信息。 提示 1 在内存中设计数据结构存储电话号码的信息在外存中利用文件的形式来保存电话号码信息系统运行时将电话号码信息从文件调入内存来进行插入、查找等操作。 2 如果数据的插入删除频繁可以考虑采取二叉排序树组织电话号码信息也可采用较复杂的平衡二叉树可以提高查找和维护的时间性能。 3 选择不同的排序和查找算法尽可能提高查找和维护性能。 52 数字文本压缩 问题描述利用哈夫曼编码实现数字文本的压缩和解压缩。基本要求对于给定的数字文本可以根据其频度进行哈夫曼编码并能输出对应的哈夫曼树和哈夫曼编码实现哈夫曼解码。提高要求1能够分析文件统计文件中出现的字符统计字符出现的概率再对文件进行编码实现文件的压缩和解压缩。2能够对于文件的压缩比例进行统计。 53 订票系统 基本要求 1录入可以录入航班情况数据可以存储在一个数据文件中数据结构、具体数据自定 2查询可以查询某个航线的情况如输入航班号查询起降时间起飞抵达城市航班 数据结构与C语言综合训练实习 9 票价票价折扣确定航班是否满仓 3可以输入起飞抵达城市查询飞机航班情况 4订票订票情况可以存在一个数据文件中结构自己设定可以订票如果该航班已经无票可以提供相关可选择航班退票 可退票退票后修改相关数据文件客户资料有姓名证件号订票数量及航班情况订单要有编号 5修改航班信息当航班信息改变可以修改航班数据文件。 54 学籍管理系统 问题描述建立学籍管理系统实现对于学生信息的添加和维护管理。 基本要求完成学籍登记表中的下面功能登记表中包括学号、姓名、性别、出生日期、政治面貌、联系方式、家庭住址等信息。 ⑴ 插入将某学生的基本信息插入到登记表中 ⑵ 删除将满足条件的基本信息删除 ⑶ 修改对基本信息的数据项进行修改 ⑷ 查询查找满足条件的学生 ⑸ 输出将登记表中的全部或满足条件基本信息输出。 提高要求 ⑴ 可以添加课程信息如开课学期、上课时间、上课地点等信息学生选课信息实现学生的选课功能 ⑵ 增加学生成绩信息可以对学生的成绩进行插入、删除、修改等操作 ⑶ 实现查找某学生的选课记录课程成绩等 ⑷ 利用二叉排序树、平衡树、排序算法等数据结构知识提高排序和查找速度。 提示 ⑴ 学生登记表一般建立后比较少更改因此可以采用顺序表方式建立 ⑵ 学生选课、成绩等信息一般更改比较频繁则可以采取链表建立 ⑶ 可以将学生的信息存储到文件中系统运行时将信息从文件调入到内存中运行。 55 数字游戏的设计 1一个四位数各位上的数字不重复从1到9。 2按以下提示猜出这个四位数。 数据结构与C语言综合训练实习 10 3每次猜测输入的数据给出类似的提示AB。 4其中A前的代表你本次猜对了多少个数字。 5其中B前的代表你本次猜对的数字并且位置正确的个数。 56 稀疏矩阵的压缩与还原 一个矩阵含有非零元素比较少而零元素相对较多这样的矩阵称为稀疏矩阵对稀疏矩阵的存储我们不用完全用二维数组来存储可以用一个三元组即任意一个稀疏矩阵可以用一个只有三列的二维数组来存放 要求把给定的稀疏矩阵用为三元组表示同时把三元组转换为稀疏矩阵形式。 57 文章编辑 输入一页文字程序可以统计出文字、数字、空格的个数。静态存储一页文章每行最多不超过80个字符。 要求 1分别统计出其中英文字母数和空格数及整篇文章总字数 2统计某一字符串在文章中出现的次数并输出该次数 3删除某一子串并将后面的字符前移。 存储结构使用线性表分别用几个子函数实现相应的功能 输入数据的形式和范围可以输入大写、小写的英文字母、任何数字及标点符号。 输出形式 1 分行输出用户输入的各行字符 2 分4行输出quot全部字母数quot、quot数字个数quot、quot空格个数quot、quot文章总字数quot 3 输出删除某一字符串后的文章 58 拓扑排序 建立有向无环图并输出拓扑的序列。 59 随机探测再散列哈希表 实现随机探测再散列哈希表的创建与查找 60 公园的导游图 给出一张某公园的导游图游客通过终端询问可知 从某一景点到另一景点的最短路径。游客从公园大门进入选一条最佳路线使游客可以不重复地游览各景点最后回到出口出口就在入口旁边。 分步实施 数据结构与C语言综合训练实习 11 1 初步完成总体设计建好框架确定人机对话的界面确定函数个数 2 完成最低要求建立一个文件包括5个景点情况能完成遍历功能 3 进一步要求进一步扩充景点数目画出景点图有兴趣的同学可以自己扩充系统功能。 61 商店存货管理系统 建立一商店存货管理系统要求每次出货时取进货时间最早且最接近保质期中止时间的货物。 分步实施 1初步完成总体设计建好框架确定人机对话的界面确定函数个数 2完成最低要求建立一个文件包括5个种类的货物情况能对商品信息进行扩充追加修改和删除以及简单的排序 3进一步要求扩充商品数量以及完成系统查询功能。有兴趣的同学可以自己扩充系统功能。 62 运动会分数统计 输入统计排序查询信息存储。 63 二叉树遍历算法的实现 四种算法都是.追问
haha
集合-ConcurrentSkipListMap 源码解析
简介
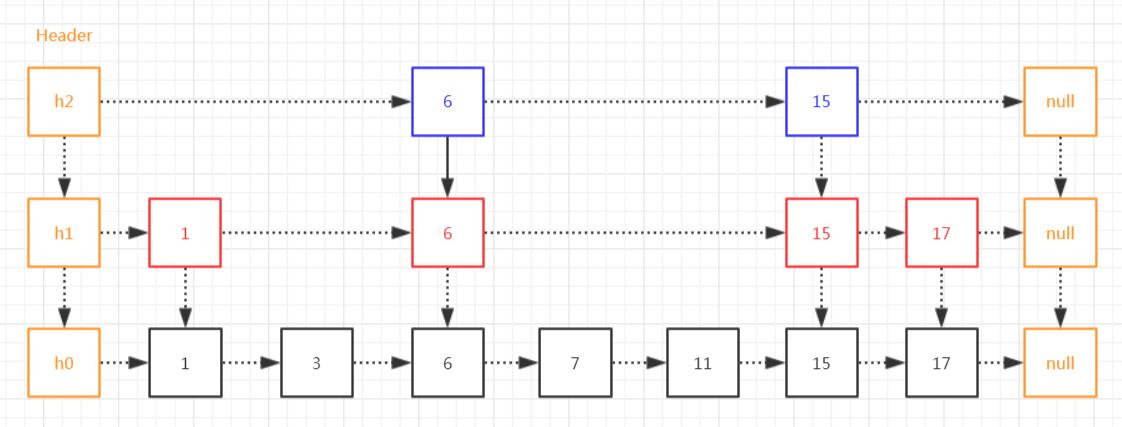
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
存储结构
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
源码分析
主要内部类
内部类跟存储结构结合着来看,大概能预测到代码的组织方式。
// 数据节点,典型的单链表结构 static final class Node<K,V> { final K key; // 注意:这里value的类型是Object,而不是V // 在删除元素的时候value会指向当前元素本身 volatile Object value; volatile Node<K,V> next; Node(K key, Object value, Node<K,V> next) { this.key = key; this.value = value; this.next = next; } Node(Node<K,V> next) { this.key = null; this.value = this; // 当前元素本身(marker) this.next = next; } } // 索引节点,存储着对应的node值,及向下和向右的索引指针 static class Index<K,V> { final Node<K,V> node; final Index<K,V> down; volatile Index<K,V> right; Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) { this.node = node; this.down = down; this.right = right; } } // 头索引节点,继承自Index,并扩展一个level字段,用于记录索引的层级 static final class HeadIndex<K,V> extends Index<K,V> { final int level; HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) { super(node, down, right); this.level = level; } }
(1)Node,数据节点,存储数据的节点,典型的单链表结构;
(2)Index,索引节点,存储着对应的node值,及向下和向右的索引指针;
(3)HeadIndex,头索引节点,继承自Index,并扩展一个level字段,用于记录索引的层级;
构造方法
public ConcurrentSkipListMap() { this.comparator = null; initialize(); } public ConcurrentSkipListMap(Comparator<? super K> comparator) { this.comparator = comparator; initialize(); } public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) { this.comparator = null; initialize(); putAll(m); } public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) { this.comparator = m.comparator(); initialize(); buildFromSorted(m); }
四个构造方法里面都调用了initialize()这个方法,那么,这个方法里面有什么呢? private static final Object BASE_HEADER = new Object(); private void initialize() { keySet = null; entrySet = null; values = null; descendingMap = null; // Node(K key, Object value, Node<K,V> next) // HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null), null, null, 1); }
可以看到,这里初始化了一些属性,并创建了一个头索引节点,里面存储着一个数据节点,这个数据节点的值是空对象,且它的层级是1。
所以,初始化的时候,跳表中只有一个头索引节点,层级是1,数据节点是一个空对象,down和right都是null。
通过内部类的结构我们知道,一个头索引指针包含node, down, right三个指针,为了便于理解,我们把指向node的指针用虚线表示,其它两个用实线表示,也就是虚线不是表明方向的。
添加元素
通过【跳表!】中的分析,我们知道跳表插入元素的时候会通过抛硬币的方式决定出它需要的层级,然后找到各层链中它所在的位置,最后通过单链表插入的方式把节点及索引插入进去来实现的。
那么,ConcurrentSkipList中是这么做的吗?让我们一起来探个究竟:
public V put(K key, V value) { // 不能存储value为null的元素 // 因为value为null标记该元素被删除(后面会看到) if (value == null) throw new NullPointerException(); // 调用doPut()方法添加元素 return doPut(key, value, false); } private V doPut(K key, V value, boolean onlyIfAbsent) { // 添加元素后存储在z中 Node<K,V> z; // added node // key也不能为null if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; // Part I:找到目标节点的位置并插入 // 这里的目标节点是数据节点,也就是最底层的那条链 // 自旋 outer: for (;;) { // 寻找目标节点之前最近的一个索引对应的数据节点,存储在b中,b=before // 并把b的下一个数据节点存储在n中,n=next // 为了便于描述,我这里把b叫做当前节点,n叫做下一个节点 for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { // 如果下一个节点不为空 // 就拿其key与目标节点的key比较,找到目标节点应该插入的位置 if (n != null) { // v=value,存储节点value值 // c=compare,存储两个节点比较的大小 Object v; int c; // n的下一个数据节点,也就是b的下一个节点的下一个节点(孙子节点) Node<K,V> f = n.next; // 如果n不为b的下一个节点 // 说明有其它线程修改了数据,则跳出内层循环 // 也就是回到了外层循环自旋的位置,从头来过 if (n != b.next) // inconsistent read break; // 如果n的value值为空,说明该节点已删除,协助删除节点 if ((v = n.value) == null) { // n is deleted // todo 这里为啥会协助删除?后面讲 n.helpDelete(b, f); break; } // 如果b的值为空或者v等于n,说明b已被删除 // 这时候n就是marker节点,那b就是被删除的那个 if (b.value == null || v == n) // b is deleted break; // 如果目标key与下一个节点的key大 // 说明目标元素所在的位置还在下一个节点的后面 if ((c = cpr(cmp, key, n.key)) > 0) { // 就把当前节点往后移一位 // 同样的下一个节点也往后移一位 // 再重新检查新n是否为空,它与目标key的关系 b = n; n = f; continue; } // 如果比较时发现下一个节点的key与目标key相同 // 说明链表中本身就存在目标节点 if (c == 0) { // 则用新值替换旧值,并返回旧值(onlyIfAbsent=false) if (onlyIfAbsent || n.casValue(v, value)) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; } // 如果替换旧值时失败,说明其它线程先一步修改了值,从头来过 break; // restart if lost race to replace value } // 如果c<0,就往下走,也就是找到了目标节点的位置 // else c < 0; fall through } // 有两种情况会到这里 // 一是到链表尾部了,也就是n为null了 // 二是找到了目标节点的位置,也就是上面的c<0 // 新建目标节点,并赋值给z // 这里把n作为新节点的next // 如果到链表尾部了,n为null,这毫无疑问 // 如果c<0,则n的key比目标key大,相妆于在b和n之间插入目标节点z z = new Node<K,V>(key, value, n); // 原子更新b的下一个节点为目标节点z if (!b.casNext(n, z)) // 如果更新失败,说明其它线程先一步修改了值,从头来过 break; // restart if lost race to append to b // 如果更新成功,跳出自旋状态 break outer; } } // 经过Part I,目标节点已经插入到有序链表中了 // Part II:随机决定是否需要建立索引及其层次,如果需要则建立自上而下的索引 // 取个随机数 int rnd = ThreadLocalRandom.nextSecondarySeed(); // 0x80000001展开为二进制为10000000000000000000000000000001 // 只有两头是1 // 这里(rnd & 0x80000001) == 0 // 相当于排除了负数(负数最高位是1),排除了奇数(奇数最低位是1) // 只有最高位最低位都不为1的数跟0x80000001做&操作才会为0 // 也就是正偶数 if ((rnd & 0x80000001) == 0) { // test highest and lowest bits // 默认level为1,也就是只要到这里了就会至少建立一层索引 int level = 1, max; // 随机数从最低位的第二位开始,有几个连续的1则level就加几 // 因为最低位肯定是0,正偶数嘛 // 比如,1100110,level就加2 while (((rnd >>>= 1) & 1) != 0) ++level; // 用于记录目标节点建立的最高的那层索引节点 Index<K,V> idx = null; // 取头索引节点(这是最高层的头索引节点) HeadIndex<K,V> h = head; // 如果生成的层数小于等于当前最高层的层级 // 也就是跳表的高度不会超过现有高度 if (level <= (max = h.level)) { // 从第一层开始建立一条竖直的索引链表 // 这条链表使用down指针连接起来 // 每个索引节点里面都存储着目标节点这个数据节点 // 最后idx存储的是这条索引链表的最高层节点 for (int i = 1; i <= level; ++i) idx = new Index<K,V>(z, idx, null); } else { // try to grow by one level // 如果新的层数超过了现有跳表的高度 // 则最多只增加一层 // 比如现在只有一层索引,那下一次最多增加到两层索引,增加多了也没有意义 level = max + 1; // hold in array and later pick the one to use // idxs用于存储目标节点建立的竖起索引的所有索引节点 // 其实这里直接使用idx这个最高节点也是可以完成的 // 只是用一个数组存储所有节点要方便一些 // 注意,这里数组0号位是没有使用的 @SuppressWarnings("unchecked")Index<K,V>[] idxs = (Index<K,V>[])new Index<?,?>[level+1]; // 从第一层开始建立一条竖的索引链表(跟上面一样,只是这里顺便把索引节点放到数组里面了) for (int i = 1; i <= level; ++i) idxs[i] = idx = new Index<K,V>(z, idx, null); // 自旋 for (;;) { // 旧的最高层头索引节点 h = head; // 旧的最高层级 int oldLevel = h.level; // 再次检查,如果旧的最高层级已经不比新层级矮了 // 说明有其它线程先一步修改了值,从头来过 if (level <= oldLevel) // lost race to add level break; // 新的最高层头索引节点 HeadIndex<K,V> newh = h; // 头节点指向的数据节点 Node<K,V> oldbase = h.node; // 超出的部分建立新的头索引节点 for (int j = oldLevel+1; j <= level; ++j) newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j); // 原子更新头索引节点 if (casHead(h, newh)) { // h指向新的最高层头索引节点 h = newh; // 把level赋值为旧的最高层级的 // idx指向的不是最高的索引节点了 // 而是与旧最高层平齐的索引节点 idx = idxs[level = oldLevel]; break; } } } // 经过上面的步骤,有两种情况 // 一是没有超出高度,新建一条目标节点的索引节点链 // 二是超出了高度,新建一条目标节点的索引节点链,同时最高层头索引节点同样往上长 // Part III:将新建的索引节点(包含头索引节点)与其它索引节点通过右指针连接在一起 // 这时level是等于旧的最高层级的,自旋 splice: for (int insertionLevel = level;;) { // h为最高头索引节点 int j = h.level; // 从头索引节点开始遍历 // 为了方便,这里叫q为当前节点,r为右节点,d为下节点,t为目标节点相应层级的索引 for (Index<K,V> q = h, r = q.right, t = idx;;) { // 如果遍历到了最右边,或者最下边, // 也就是遍历到头了,则退出外层循环 if (q == null || t == null) break splice; // 如果右节点不为空 if (r != null) { // n是右节点的数据节点,为了方便,这里直接叫右节点的值 Node<K,V> n = r.node; // 比较目标key与右节点的值 int c = cpr(cmp, key, n.key); // 如果右节点的值为空了,则表示此节点已删除 if (n.value == null) { // 则把右节点删除 if (!q.unlink(r)) // 如果删除失败,说明有其它线程先一步修改了,从头来过 break; // 删除成功后重新取右节点 r = q.right; continue; } // 如果比较c>0,表示目标节点还要往右 if (c > 0) { // 则把当前节点和右节点分别右移 q = r; r = r.right; continue; } } // 到这里说明已经到当前层级的最右边了 // 这里实际是会先走第二个if // 第一个if // j与insertionLevel相等了 // 实际是先走的第二个if,j自减后应该与insertionLevel相等 if (j == insertionLevel) { // 这里是真正连右指针的地方 if (!q.link(r, t)) // 连接失败,从头来过 break; // restart // t节点的值为空,可能是其它线程删除了这个元素 if (t.node.value == null) { // 这里会去协助删除元素 findNode(key); break splice; } // 当前层级右指针连接完毕,向下移一层继续连接 // 如果移到了最下面一层,则说明都连接完成了,退出外层循环 if (--insertionLevel == 0) break splice; } // 第二个if // j先自减1,再与两个level比较 // j、insertionLevel和t(idx)三者是对应的,都是还未把右指针连好的那个层级 if (--j >= insertionLevel && j < level) // t往下移 t = t.down; // 当前层级到最右边了 // 那只能往下一层级去走了 // 当前节点下移 // 再取相应的右节点 q = q.down; r = q.right; } } } return null; } // 寻找目标节点之前最近的一个索引对应的数据节点 private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) { // key不能为空 if (key == null) throw new NullPointerException(); // don‘t postpone errors // 自旋 for (;;) { // 从最高层头索引节点开始查找,先向右,再向下 // 直到找到目标位置之前的那个索引 for (Index<K,V> q = head, r = q.right, d;;) { // 如果右节点不为空 if (r != null) { // 右节点对应的数据节点,为了方便,我们叫右节点的值 Node<K,V> n = r.node; K k = n.key; // 如果右节点的value为空 // 说明其它线程把这个节点标记为删除了 // 则协助删除 if (n.value == null) { if (!q.unlink(r)) // 如果删除失败 // 说明其它线程先删除了,从头来过 break; // restart // 删除之后重新读取右节点 r = q.right; // reread r continue; } // 如果目标key比右节点还大,继续向右寻找 if (cpr(cmp, key, k) > 0) { // 往右移 q = r; // 重新取右节点 r = r.right; continue; } // 如果c<0,说明不能再往右了 } // 到这里说明当前层级已经到最右了 // 两种情况:一是r==null,二是c<0 // 再从下一级开始找 // 如果没有下一级了,就返回这个索引对应的数据节点 if ((d = q.down) == null) return q.node; // 往下移 q = d; // 重新取右节点 r = d.right; } } } // Node.class中的方法,协助删除元素 void helpDelete(Node<K,V> b, Node<K,V> f) { /* * Rechecking links and then doing only one of the * help-out stages per call tends to minimize CAS * interference among helping threads. */ // 这里的调用者this==n,三者关系是b->n->f if (f == next && this == b.next) { // 将n的值设置为null后,会先把n的下个节点设置为marker节点 // 这个marker节点的值是它自己 // 这里如果不是它自己说明marker失败了,重新marker if (f == null || f.value != f) // not already marked casNext(f, new Node<K,V>(f)); else // marker过了,就把b的下个节点指向marker的下个节点 b.casNext(this, f.next); } } // Index.class中的方法,删除succ节点 final boolean unlink(Index<K,V> succ) { // 原子更新当前节点指向下一个节点的下一个节点 // 也就是删除下一个节点 return node.value != null && casRight(succ, succ.right); } // Index.class中的方法,在当前节点与succ之间插入newSucc节点 final boolean link(Index<K,V> succ, Index<K,V> newSucc) { // 在当前节点与下一个节点中间插入一个节点 Node<K,V> n = node; // 新节点指向当前节点的下一个节点 newSucc.right = succ; // 原子更新当前节点的下一个节点指向新节点 return n.value != null && casRight(succ, newSucc); }
我们这里把整个插入过程分成三个部分:
Part I:找到目标节点的位置并插入
(1)这里的目标节点是数据节点,也就是最底层的那条链;
(2)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(3)从这个数据节点开始往后遍历,直到找到目标节点应该插入的位置;
(4)如果这个位置有元素,就更新其值(onlyIfAbsent=false);
(5)如果这个位置没有元素,就把目标节点插入;
(6)至此,目标节点已经插入到最底层的数据节点链表中了;
Part II:随机决定是否需要建立索引及其层次,如果需要则建立自上而下的索引
(1)取个随机数rnd,计算(rnd & 0x80000001);
(2)如果不等于0,结束插入过程,也就是不需要创建索引,返回;
(3)如果等于0,才进入创建索引的过程(只要正偶数才会等于0);
(4)计算while (((rnd >>>= 1) & 1) != 0),决定层级数,level从1开始;
(5)如果算出来的层级不高于现有最高层级,则直接建立一条竖直的索引链表(只有down有值),并结束Part II;
(6)如果算出来的层级高于现有最高层级,则新的层级只能比现有最高层级多1;
(7)同样建立一条竖直的索引链表(只有down有值);
(8)将头索引也向上增加到相应的高度,结束Part II;
(9)也就是说,如果层级不超过现有高度,只建立一条索引链,否则还要额外增加头索引链的高度(脑补一下,后面举例说明);
Part III:将新建的索引节点(包含头索引节点)与其它索引节点通过右指针连接在一起(补上right指针)
(1)从最高层级的头索引节点开始,向右遍历,找到目标索引节点的位置;
(2)如果当前层有目标索引,则把目标索引插入到这个位置,并把目标索引前一个索引向下移一个层级;
(3)如果当前层没有目标索引,则把目标索引位置前一个索引向下移一个层级;
(4)同样地,再向右遍历,寻找新的层级中目标索引的位置,回到第(2)步;
(5)依次循环找到所有层级目标索引的位置并把它们插入到横向的索引链表中;
总结起来,一共就是三大步:
(1)插入目标节点到数据节点链表中;
(2)建立竖直的down链表;
(3)建立横向的right链表;
添加元素举例
假设初始链表是这样:
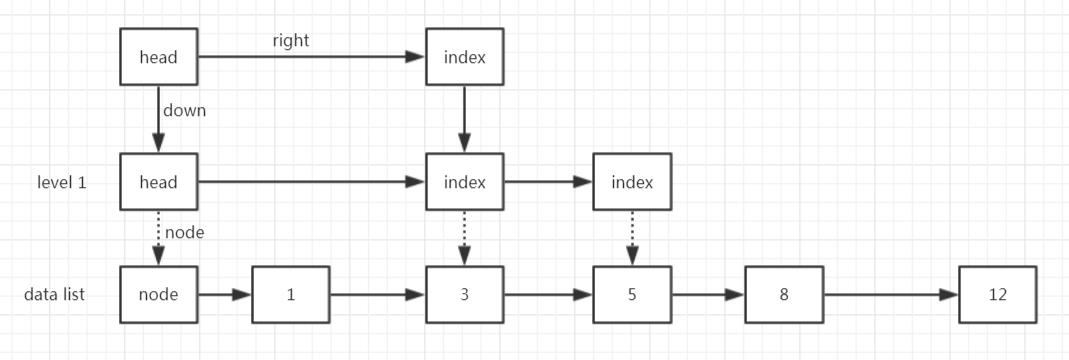
假如,我们现在要插入一个元素9。
(1)寻找目标节点之前最近的一个索引对应的数据节点,在这里也就是找到了5这个数据节点;
(2)从5开始向后遍历,找到目标节点的位置,也就是在8和12之间;
(3)插入9这个元素,Part I 结束;
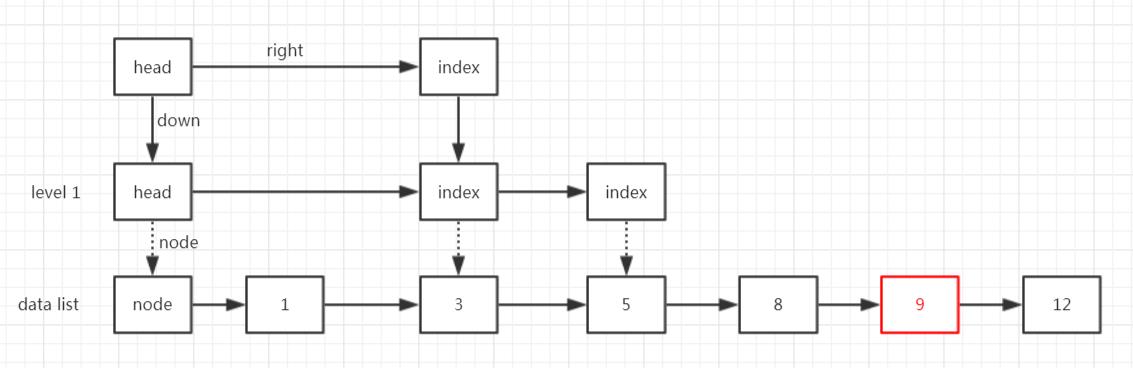
然后,计算其索引层级,假如是3,也就是level=3。
(1)建立竖直的down索引链表;
(2)超过了现有高度2,还要再增加head索引链的高度;
(3)至此,Part II 结束;
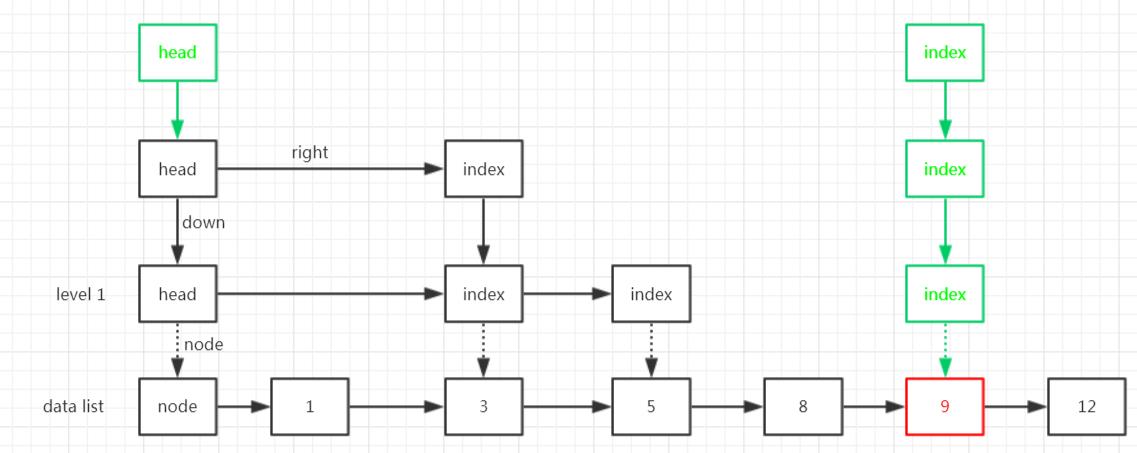
最后,把right指针补齐。
(1)从第3层的head往右找当前层级目标索引的位置;
(2)找到就把目标索引和它前面索引的right指针连上,这里前一个正好是head;
(3)然后前一个索引向下移,这里就是head下移;
(4)再往右找目标索引的位置;
(5)找到了就把right指针连上,这里前一个是3的索引;
(6)然后3的索引下移;
(7)再往右找目标索引的位置;
(8)找到了就把right指针连上,这里前一个是5的索引;
(9)然后5下移,到底了,Part III 结束,整个插入过程结束;
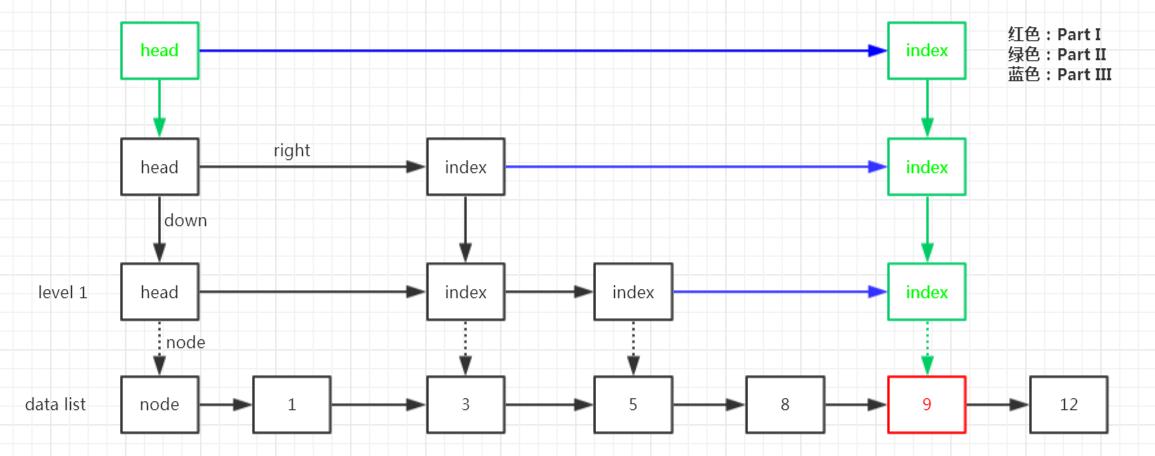
是不是很简单^^
删除元素
删除元素,就是把各层级中对应的元素删除即可,真的这么简单吗?来让我们上代码:
public V remove(Object key) { return doRemove(key, null); } final V doRemove(Object key, Object value) { // key不为空 if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; // 自旋 outer: for (;;) { // 寻找目标节点之前的最近的索引节点对应的数据节点 // 为了方便,这里叫b为当前节点,n为下一个节点,f为下下个节点 for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; // 整个链表都遍历完了也没找到目标节点,退出外层循环 if (n == null) break outer; // 下下个节点 Node<K,V> f = n.next; // 再次检查 // 如果n不是b的下一个节点了 // 说明有其它线程先一步修改了,从头来过 if (n != b.next) // inconsistent read break; // 如果下个节点的值奕为null了 // 说明有其它线程标记该元素为删除状态了 if ((v = n.value) == null) { // n is deleted // 协助删除 n.helpDelete(b, f); break; } // 如果b的值为空或者v等于n,说明b已被删除 // 这时候n就是marker节点,那b就是被删除的那个 if (b.value == null || v == n) // b is deleted break; // 如果c<0,说明没找到元素,退出外层循环 if ((c = cpr(cmp, key, n.key)) < 0) break outer; // 如果c>0,说明还没找到,继续向右找 if (c > 0) { // 当前节点往后移 b = n; // 下一个节点往后移 n = f; continue; } // c=0,说明n就是要找的元素 // 如果value不为空且不等于找到元素的value,不需要删除,退出外层循环 if (value != null && !value.equals(v)) break outer; // 如果value为空,或者相等 // 原子标记n的value值为空 if (!n.casValue(v, null)) // 如果删除失败,说明其它线程先一步修改了,从头来过 break; // P.S.到了这里n的值肯定是设置成null了 // 关键!!!! // 让n的下一个节点指向一个market节点 // 这个market节点的key为null,value为marker自己,next为n的下个节点f // 或者让b的下一个节点指向下下个节点 // 注意:这里是或者||,因为两个CAS不能保证都成功,只能一个一个去尝试 // 这里有两层意思: // 一是如果标记market成功,再尝试将b的下个节点指向下下个节点,如果第二步失败了,进入条件,如果成功了就不用进入条件了 // 二是如果标记market失败了,直接进入条件 if (!n.appendMarker(f) || !b.casNext(n, f)) // 通过findNode()重试删除(里面有个helpDelete()方法) findNode(key); // retry via findNode else { // 上面两步操作都成功了,才会进入这里,不太好理解,上面两个条件都有非"!"操作 // 说明节点已经删除了,通过findPredecessor()方法删除索引节点 // findPredecessor()里面有unlink()操作 findPredecessor(key, cmp); // clean index // 如果最高层头索引节点没有右节点,则跳表的高度降级 if (head.right == null) tryReduceLevel(); } // 返回删除的元素值 @SuppressWarnings("unchecked") V vv = (V)v; return vv; } } return null; }
(1)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(2)从这个数据节点开始往后遍历,直到找到目标节点的位置;
(3)如果这个位置没有元素,直接返回null,表示没有要删除的元素;
(4)如果这个位置有元素,先通过n.casValue(v, null)原子更新把其value设置为null;
(5)通过n.appendMarker(f)在当前元素后面添加一个marker元素标记当前元素是要删除的元素;
(6)通过b.casNext(n, f)尝试删除元素;
(7)如果上面两步中的任意一步失败了都通过findNode(key)中的n.helpDelete(b, f)再去不断尝试删除;
(8)如果上面两步都成功了,再通过findPredecessor(key, cmp)中的q.unlink(r)删除索引节点;
(9)如果head的right指针指向了null,则跳表高度降级;
删除元素举例
假如初始跳表如下图所示,我们要删除9这个元素。
(1)找到9这个数据节点;
(2)把9这个节点的value值设置为null;
(3)在9后面添加一个marker节点,标记9已经删除了;
(4)让8指向12;
(5)把索引节点与它前一个索引的right断开联系;
(6)跳表高度降级;
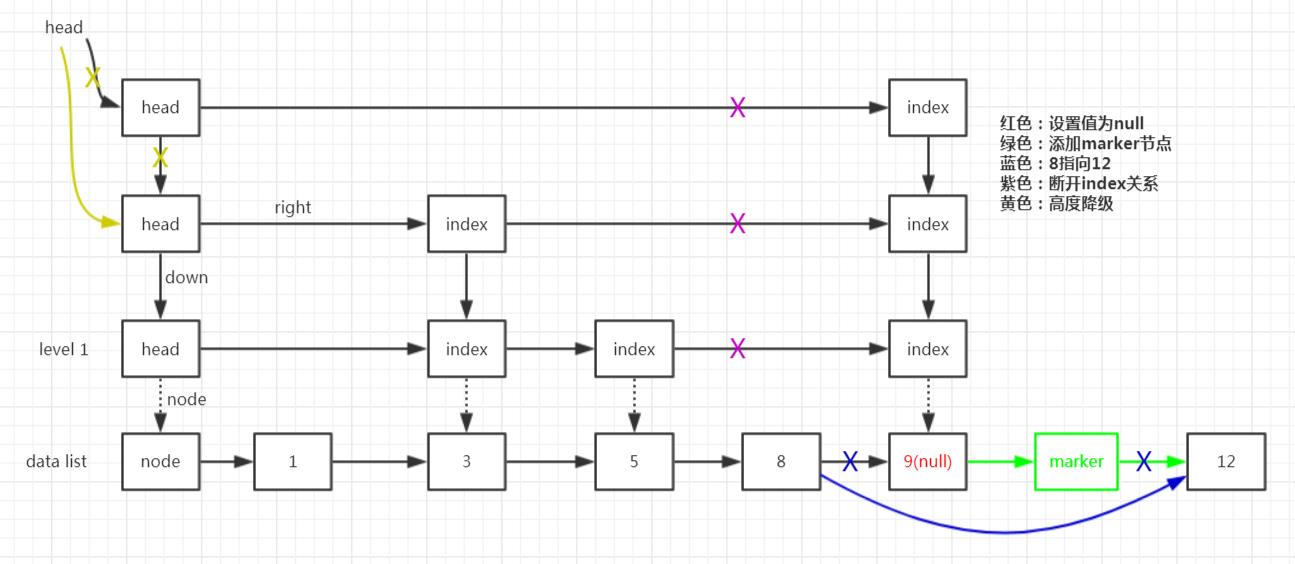
至于,为什么要有(2)(3)(4)这么多步骤呢,因为多线程下如果直接让8指向12,可以其它线程先一步在9和12间插入了一个元素10呢,这时候就不对了。
所以这里搞了三步来保证多线程下操作的正确性。
如果第(2)步失败了,则直接重试;
如果第(3)或(4)步失败了,因为第(2)步是成功的,则通过helpDelete()不断重试去删除;
其实helpDelete()里面也是不断地重试(3)和(4);
只有这三步都正确完成了,才能说明这个元素彻底被删除了。
这一块结合上面图中的红绿蓝色好好理解一下,一定要想在并发环境中会怎么样。
查找元素
经过上面的插入和删除,查找元素就比较简单了,直接上代码:
public V get(Object key) { return doGet(key); } private V doGet(Object key) { // key不为空 if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; // 自旋 outer: for (;;) { // 寻找目标节点之前最近的索引对应的数据节点 // 为了方便,这里叫b为当前节点,n为下个节点,f为下下个节点 for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; // 如果链表到头还没找到元素,则跳出外层循环 if (n == null) break outer; // 下下个节点 Node<K,V> f = n.next; // 如果不一致读,从头来过 if (n != b.next) // inconsistent read break; // 如果n的值为空,说明节点已被其它线程标记为删除 if ((v = n.value) == null) { // n is deleted // 协助删除,再重试 n.helpDelete(b, f); break; } // 如果b的值为空或者v等于n,说明b已被删除 // 这时候n就是marker节点,那b就是被删除的那个 if (b.value == null || v == n) // b is deleted break; // 如果c==0,说明找到了元素,就返回元素值 if ((c = cpr(cmp, key, n.key)) == 0) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; } // 如果c<0,说明没找到元素 if (c < 0) break outer; // 如果c>0,说明还没找到,继续寻找 // 当前节点往后移 b = n; // 下一个节点往后移 n = f; } } return null; }
(1)寻找目标节点之前最近的一个索引对应的数据节点(数据节点都是在最底层的链表上);
(2)从这个数据节点开始往后遍历,直到找到目标节点的位置;
(3)如果这个位置没有元素,直接返回null,表示没有找到元素;
(4)如果这个位置有元素,返回元素的value值;
查找元素举例
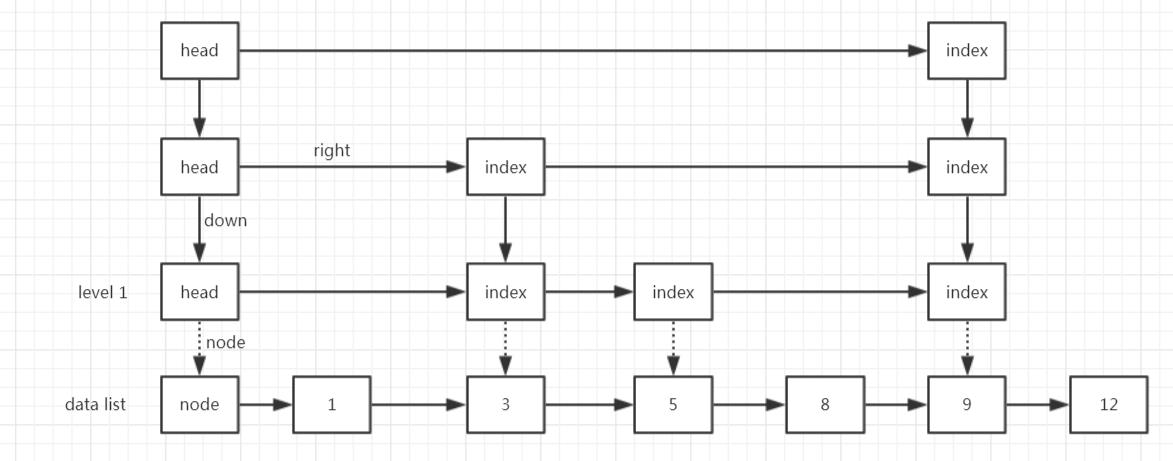
假如有如下图所示这个跳表,我们要查找9这个元素,它走过的路径是怎样的呢?可能跟你相像的不一样。。
(1)寻找目标节点之前最近的一个索引对应的数据节点,这里就是5;
(2)从5开始往后遍历,经过8,到9;
(3)找到了返回;
整个路径如下图所示:
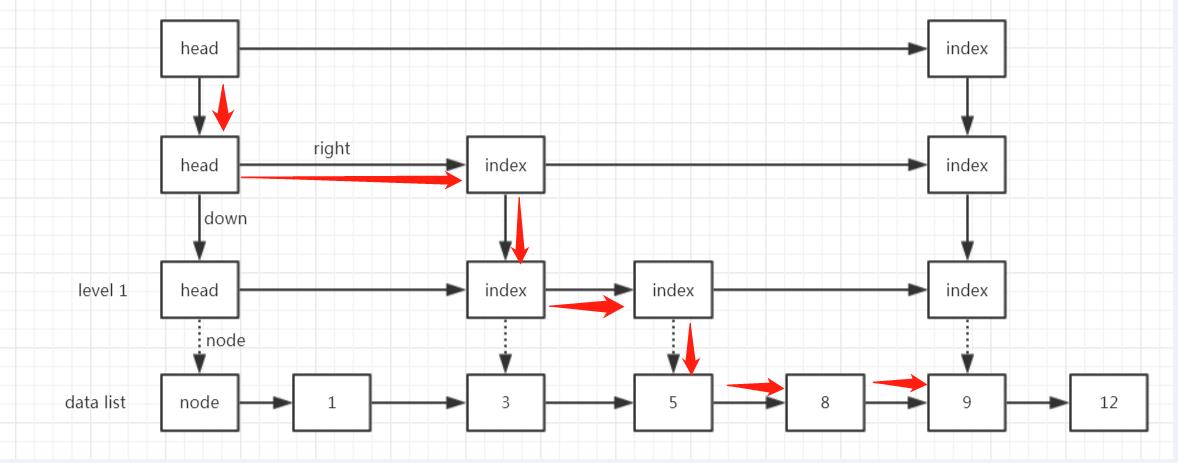
为啥不从9的索引直接过来呢?
从我实际打断点调试来看确实是按照上图的路径来走的。
我猜测可能是因为findPredecessor()这个方法是插入、删除、查找元素多个方法共用的,在单链表中插入和删除元素是需要记录前一个元素的,而查找并不需要,这里为了兼容三者使得编码相对简单一点,所以就使用了同样的逻辑,而没有单独对查找元素进行优化。
思考
为什么Redis选择使用跳表而不是红黑树来实现有序集合?
请查看【跳表!】这篇文章。
以上是关于集合操作 用单链表模拟有序集合,实现集合的加入一个元素、删除一个元素、集合的交、并、差运算。的主要内容,如果未能解决你的问题,请参考以下文章