DBA 小记 — 分库分表主从读写分离
Posted jett010
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DBA 小记 — 分库分表主从读写分离相关的知识,希望对你有一定的参考价值。
前言
我在上篇博客 “Spring Boot 的实践与思考” 中比对不同规范的 ORM 框架应用场景的时候提到过主从与读写分离,本篇随笔将针对此和分库分表进行更深入地探讨。

1. 漫谈
在进入正题之前,我想先随意谈谈对架构的拓展周期的想法(仅个人观点)。首先,我认为初期规划不该太复杂或者庞大,无论项目的中长期可能会发展地如何如何,前期都应该以灵活为优先,像分库分表等操作不应该在开始的时候就考虑进去。其次,我认为需求变更是非常正常的,这点在我等开发的圈子里吐槽的最多,其中自然有 “领导们” 在业务方面欠缺整体考虑的因素,但我们也不该局限在一个观点内,市场中变则通,不变则死,前期更是如此,因此在前几版的架构中我们必须要考虑较高的可扩展性。最后,当项目经过几轮市场的洗礼和迭代开发,核心业务趋于稳定了,此时我们再结合中长期的规划给系统来一次重构,细致地去划分领域边界,该解耦的解耦,该拆分的拆分。
2. 分库分表
2.1 概述
当数据库达到一定规模后(比如说大几千万以上),切分是必须要考虑的。一般来说我们首先要进行垂直切分,即按业务分割,比如说用户相关、订单相关、统计相关等等都可以单独成库。图片来源 →
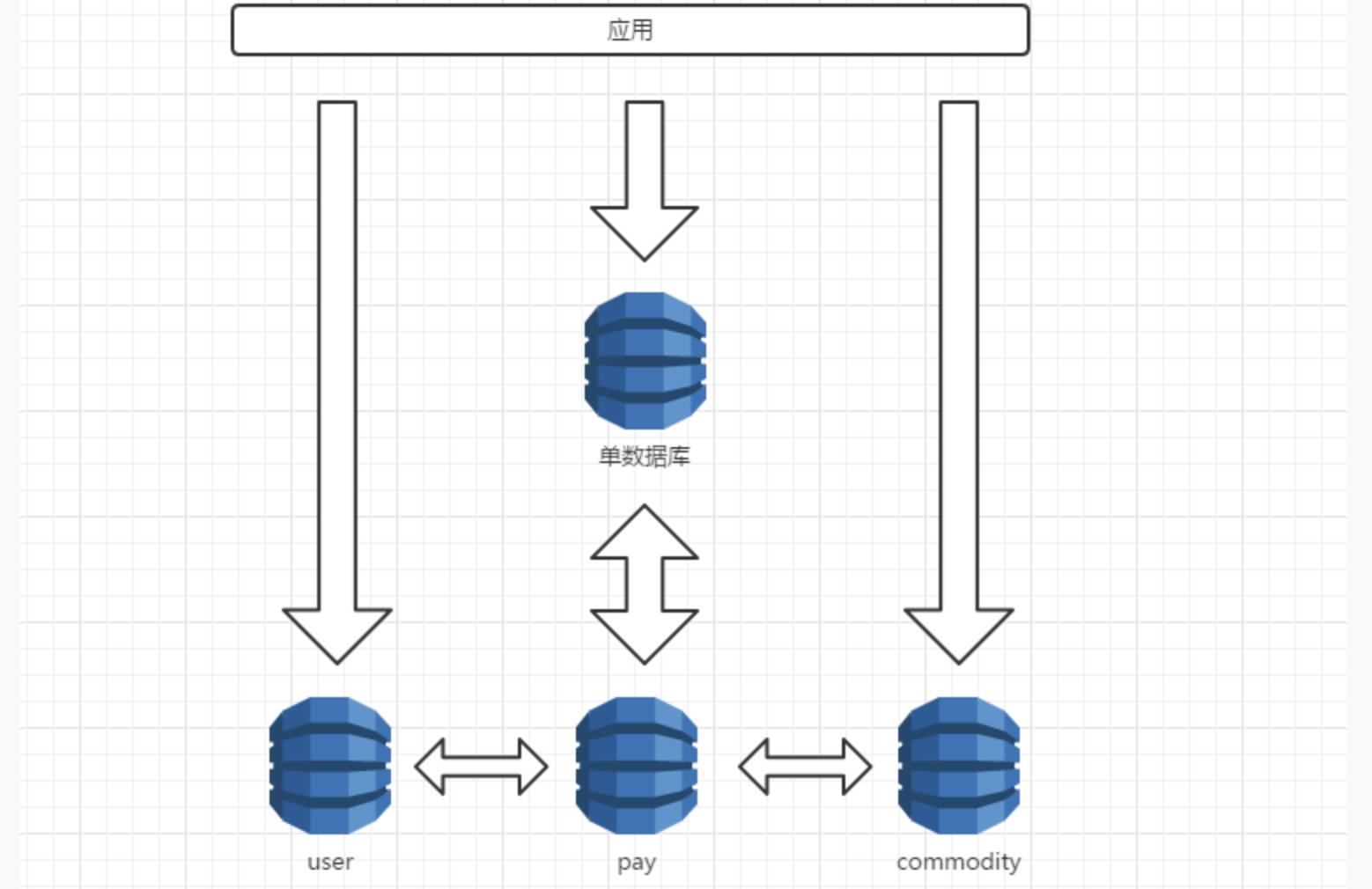
但仅仅如此这是完全不够的,垂直切分虽然剥离了一定的数据,但每个业务还是那个数量级,因此我们还得采取水平切分进一步分散数据,这也是本节论述的重点。
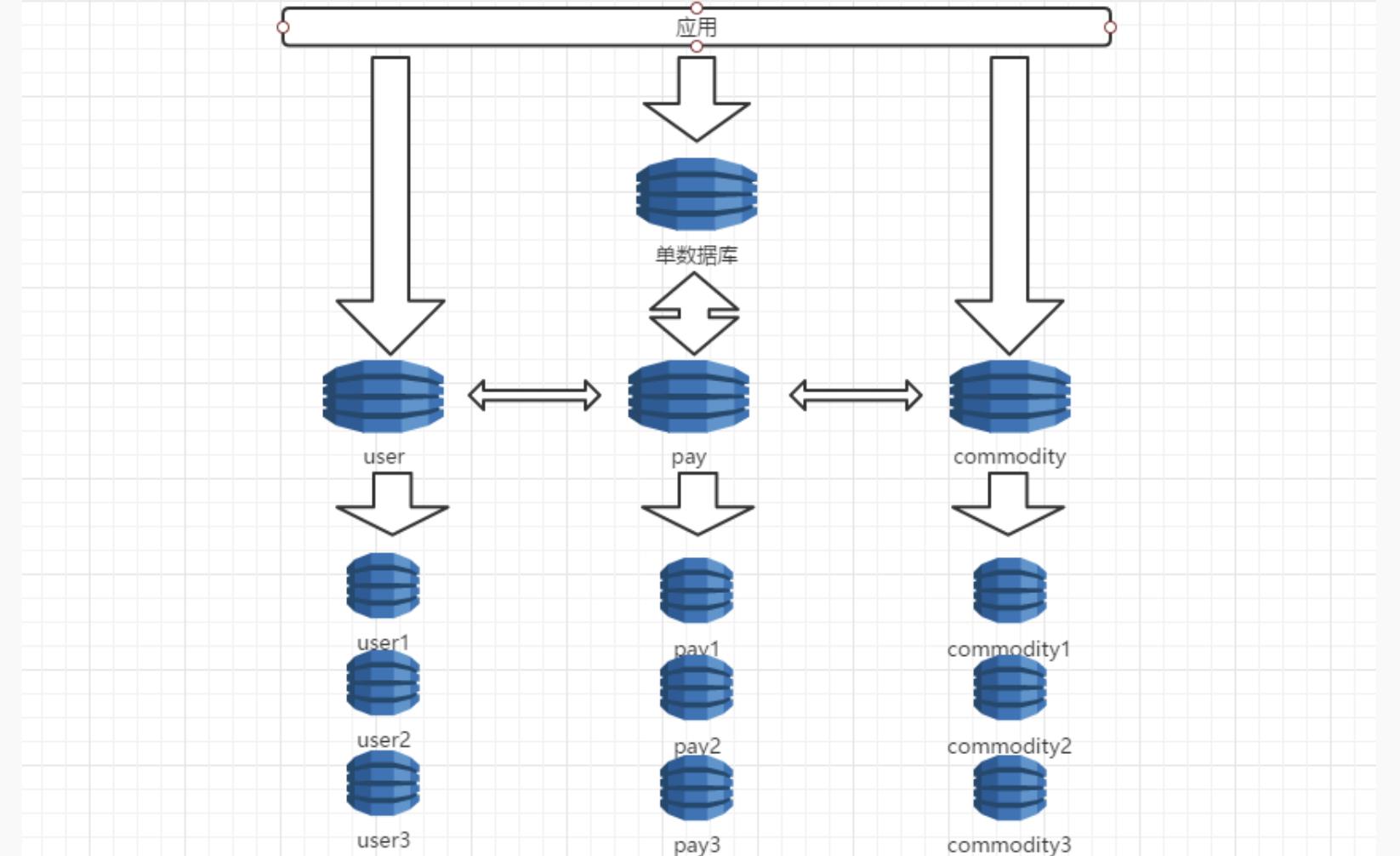
分库分表的优点相信上述两图都一目了然了,一个是专库专用,业务更集中,另一个是提升数据库服务的负载能力。But there are always two sides to a coin。 从此以后你要接受你的系统复杂度将提升一个档次,迭代、迁移、运维等都不再容易。
2.2 切分策略
垂直切分在实现上就是一个多数据源的问题,没啥好讲的。以下 Demo 为水平切分,基于 Sharding-JDBC 中间件,我只做逻辑上的陈述,有关其更详细的信息和配置请移步 “官方文档”。
首先,我们得在配置文件中定义分片策略,application.yml:
server:
port: 8001
mybatis:
config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mybatis/mappers/*.xml
sharding:
jdbc:
datasource:
names: youclk_0,youclk_1
youclk_0:
type: org.apache.commons.dbcp.BasicDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://mysql:3306/youclk_0?useSSL=false
username: root
password: youclk
youclk_1:
type: org.apache.commons.dbcp.BasicDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://mysql:3306/youclk_1?useSSL=false
username: root
password: youclk
config:
sharding:
default-database-strategy:
inline:
sharding-column: number
algorithm-expression: youclk_${number % 2}
tables:
user:
actual-data-nodes: youclk_${0..1}.user具体每个参数的含义在官方文档有详细解释,其实看名称也能理解个大概了,我定义将 number 为偶数的数据存入 youclk_0,奇数存入 youclk_1。
User:
@Data
public class User {
private String id;
private Integer number;
private Date createTime;
}UserRepository:
@Mapper
public interface UserRepository {
void insert(User user);
}UserMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.youclk.data.repository.UserRepository">
<resultMap id="BaseResultMap" type="com.youclk.data.entity.User">
<id column="id" property="id" jdbcType="CHAR"/>
<result column="number" property="number" jdbcType="INTEGER"/>
<result column="createTime" property="create_time" jdbcType="DATE"/>
</resultMap>
<sql id="Base_Column_List">
id, number, createTime
</sql>
<insert id="insert">
INSERT INTO user (
id, number
)
VALUES (
uuid(),
#{number,jdbcType=INTEGER}
)
</insert>
</mapper>UserService:
@Service
public class UserService {
@Resource
private UserRepository userRepository;
public void insert() {
for (int i = 0; i < 10; i++) {
User user = new User();
user.setNumber(i);
userRepository.insert(user);
}
}
}Result:
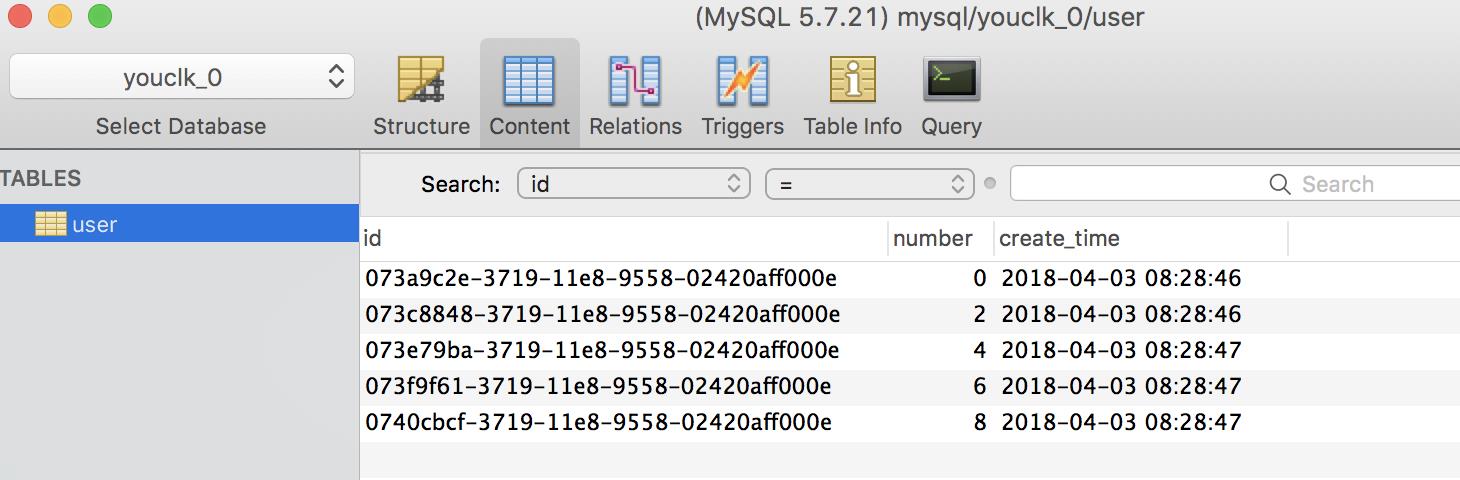
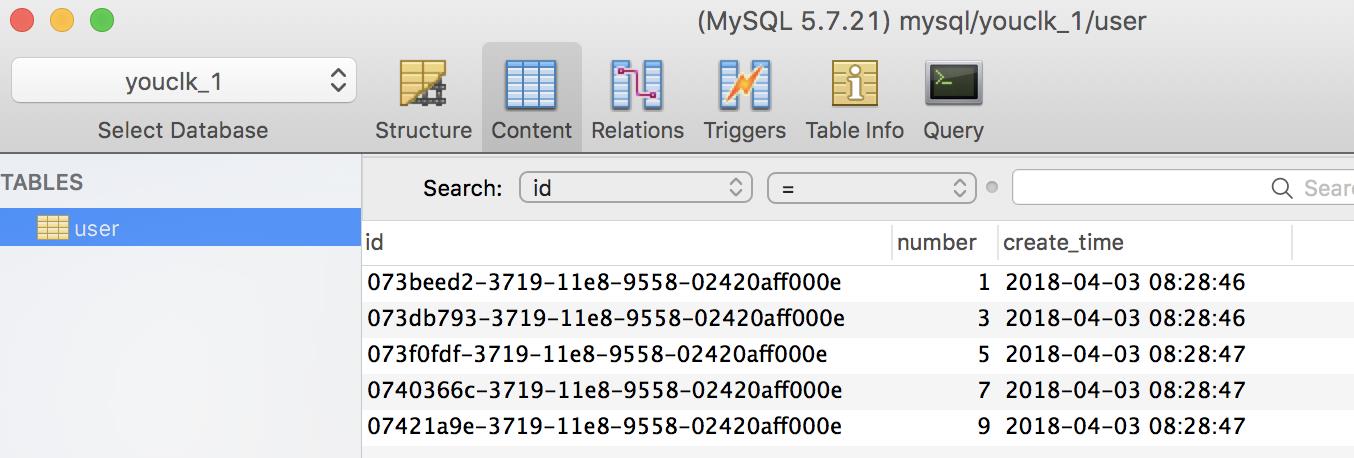
以上做了一个简单的循环插入,可以看到数据已经按策略分库存储,结果符合我们的预期。
分库之后在查询方面要比之前更加谨慎,既然按策略去切了,那最好就是按策略去查,否则...比如我水平切分了 100个库,若不按策略去查询 LIMIT 100000, 10 这么一组数据,那最后扫描的数量级别是 100 * (100000 + 10), 这是比较恐怖的,虽然 Sharding-JDBC 做了一些优化,比如他不是一次性去查询到内存中,而是采用流式处理 + 归并排序的方式,但仍然比较耗资源,能避免还是尽量去避免吧。
2.3 分布式事务
在任何系统中事务都是顶要紧的事情,面对已分库的系统更是如此,保证夸库事务的安全从来不容易。分布式事务的场景有两种,一个是在分布式服务中,这个后续有机会再探讨,本节重点关注夸库事务。
Sharding-JDBC 自动包含了弱XA事务支持,即能够保证逻辑上的事务安全,但因网络或硬件导致的异常无法回滚,实现上与一般事务无异:
@Test
@Transactional
public void insertTest() {
userService.insert();
int error = Integer.parseInt("I want error");
userService.insert();
}
可以看到夸库事务已回滚,除此之外 Sharding-JDBC 还提供了最大努力送达型柔性事务(将执行过程记录到日志中,失败重试,成功后删除,若最终还是失败则保留事务日志,供人工干预),虽然安全性更高,但无法保证时效,限制也很多,这里留个待续吧,后续有空再深入探讨(主要是比较晚了,想早点写完休息
以上是关于DBA 小记 — 分库分表主从读写分离的主要内容,如果未能解决你的问题,请参考以下文章