hadoop的简介与伪分布的搭建
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop的简介与伪分布的搭建相关的知识,希望对你有一定的参考价值。
- 一:大数据hadoop简介
- 二:hadoop的伪分布安装
- 三:运行wordcount测试
- 四:hadoop 常用端口号
- 五:hadoop的四大模块包含
- 六:启动脚本:
一: 大数据hadoop简介
hadoop 简介:
开源软件,可靠的,可分布式,可伸缩的。
去IOE
---------
IBM // ibm 小型机
Oracle // oracle 数据库服务器
EMC // 共享存储柜
cluster:
-----------
集群
1T = 1024G
1P = 1024T
1E = 1024P
1Z = 1024E
1Y = 1024Z
1N = 1024Y
海量的数据:
------
PB
大数据解决了两个问题:
---------------------
1. 存储
分布式存储
2. 计算
分布式计算
云计算:
------
1. 服务
2. 虚拟化
分布式:
--------------
由分布在不同主机上的进程协同在一起,才能构成整个应用
b/s 结构
---------------------
Browser /http server: 瘦客端模式
failure over // 容灾
fault over // 荣错
大数据4V特点:
-------------------
Volume : 容量大
variety: 多样化
velocity : 速度快
valueless : 价值密度低
Hadoop 的四个模块
------------------
1. common
2. hdfs
3. hadoop yarn
4. mapreduce (mr)
hadoop 的安装模式:
1. 独立模式 (standalone,local)
nothing !
2. 伪分布模式 (pseudodistributed mode)
3. 集群模式 (cluster mode)二:hadoop的伪分布安装
2.1 软件所需
1. jdk-8u151-linux-x64.tar.gz
2. hadoop-2.7.4.tar.gz
2.2 安装jdk
(1) 卸载原有jdk:
rpm -e java-1.8.0-openjdk-devel-1.8.0.131-11.b12.el7.x86_64 java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64 copy-jdk-configs-2.2-3.el7.noarch java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64 java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el7_3.x86_64 java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64 java-1.6.0-openjdk-devel-1.6.0.41-1.13.13.1.el7_3.x86_64 java-1.7.0-openjdk-devel-1.7.0.141-2.6.10.5.el7.x86_64 --nodeps
(2) 创建安装目录:
mkdir /soft
tar -zxvf jdk-8u151-linux-x64.tar.gz -C /soft
cd /soft
ln -s jdk1.8.0_151 jdk
-----
配置环境变量
vim /etc/profile
----
最后加上:
# jdk
export JAVA_HOME=/soft/jdk
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
---
source /etc/profile
java -version 
2.3 安装hadoop
cd software
tar -zxvf hadoop-2.7.4.tar.gz -C /soft
cd /soft
ln -s hadoop-2.7.4 hadoop
配置环境变量
vim /etc/profile
----
到最后加上
# hadoop
export HADOOP_HOME=/soft/hadoop
PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
---
source /etc/profile
cd /soft/hadoop/
bin/hadoop version
cd /soft/hadoop/etc/hadoop
编辑core-site.xml 文件:
vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/soft/hadoop/data</value>
<description>hadoop_temp</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://node01.yangyang.com:8020</value>
<description>hdfs_derect</description>
</property>
</configuration> 编辑hdfs-site.xml
vim hdfs-site.xml
------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>num</description>
<name>dfs.namenode.http-address</name>
<value>node01.yangyang.com:50070</value>
</property>
</configuration>编辑 mapred-site.xml
cp -p mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01.yangyang.com:19888</value>
</property>
</configuration>配置yarn-site.xml
vim yarn-site.xml
-----------------
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>#echo "export JAVA_HOME=/soft/jdk" >> hadoop-env.sh
#echo "export JAVA_HOME=/soft/jdk" >> mapred-env.sh
#echo "export JAVA_HOME=/soft/jdk" >> yarn-env.sh格式化文件系统:
bin/hdfs namenode -format 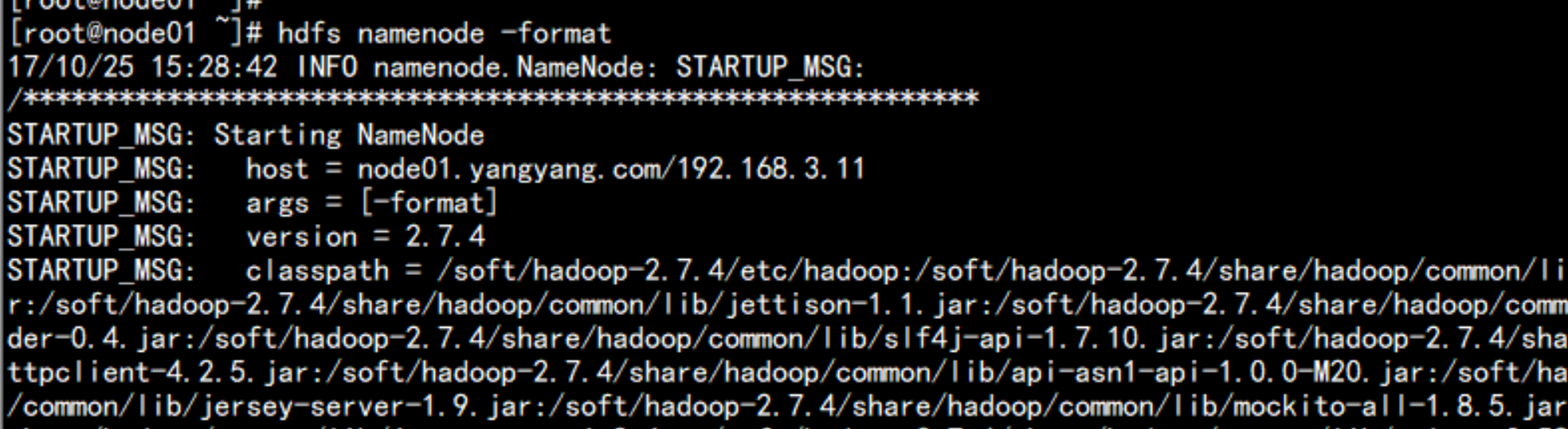
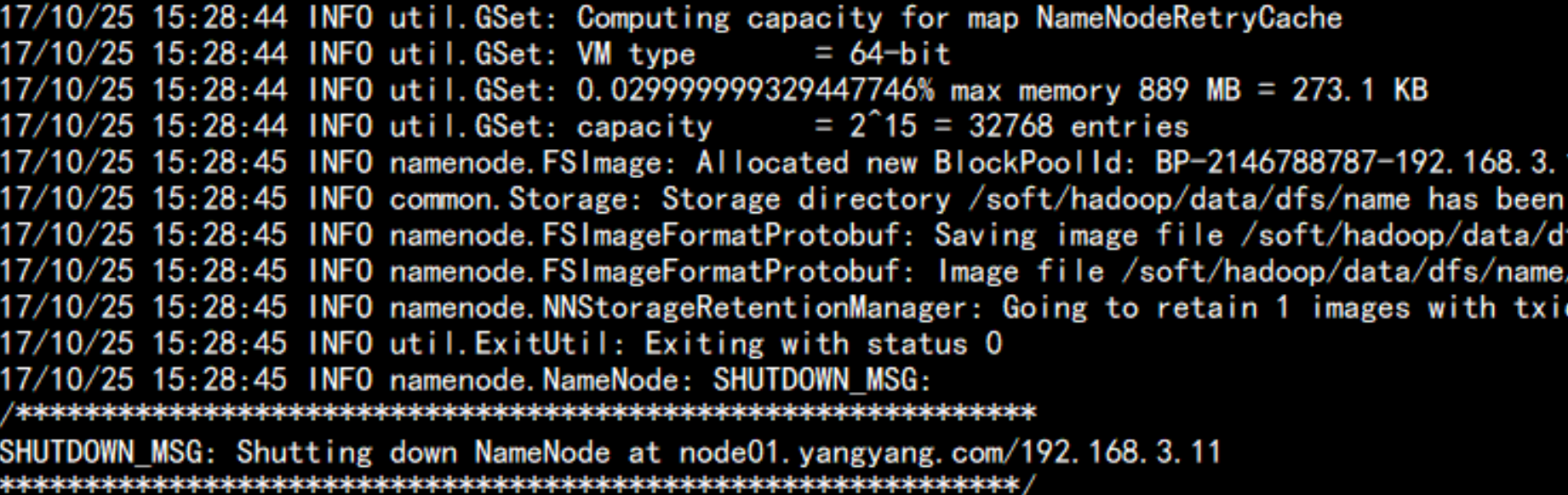
启动namenode 与 datanode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
打开浏览器: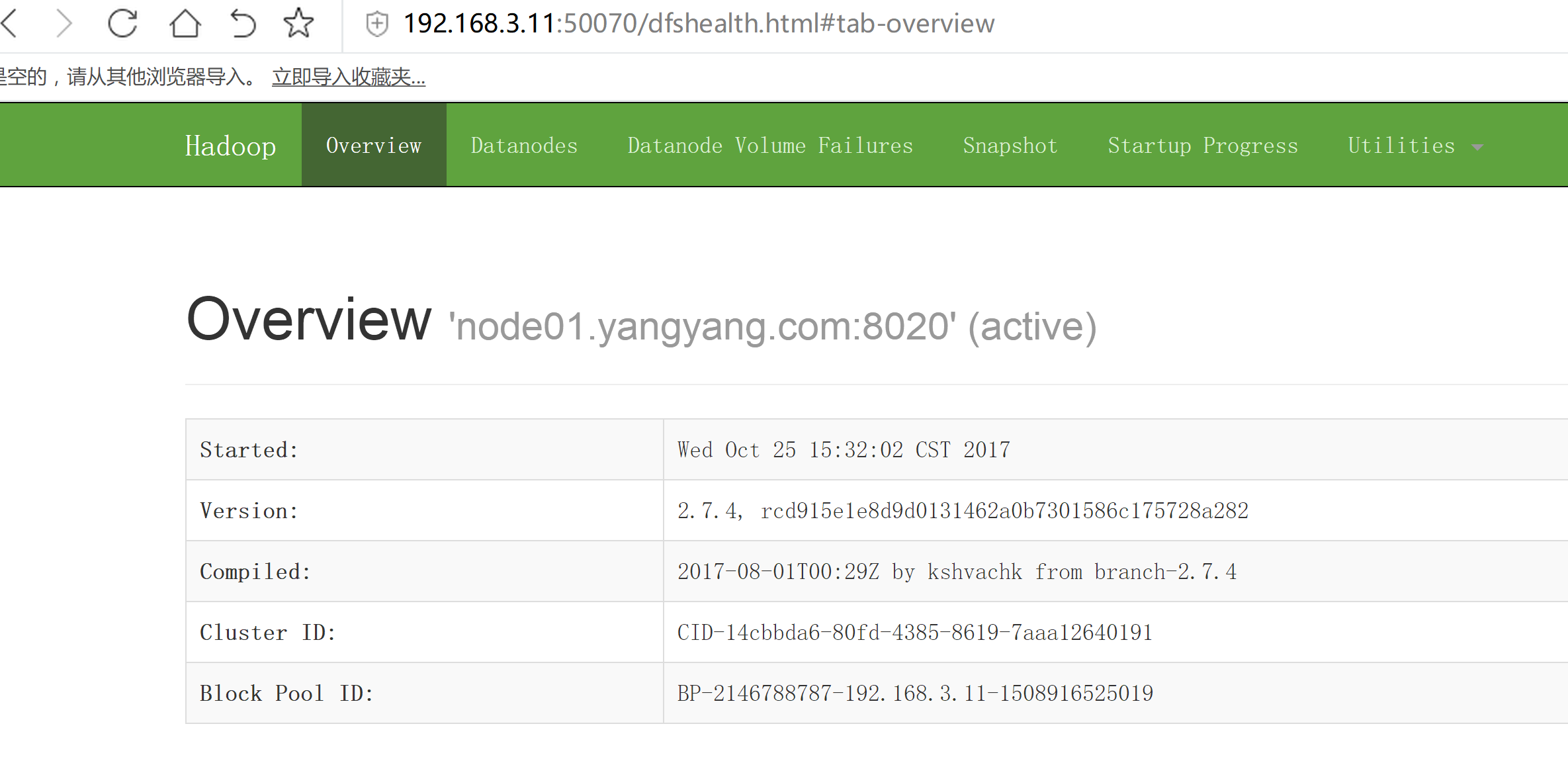
启动yarn
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
打开浏览器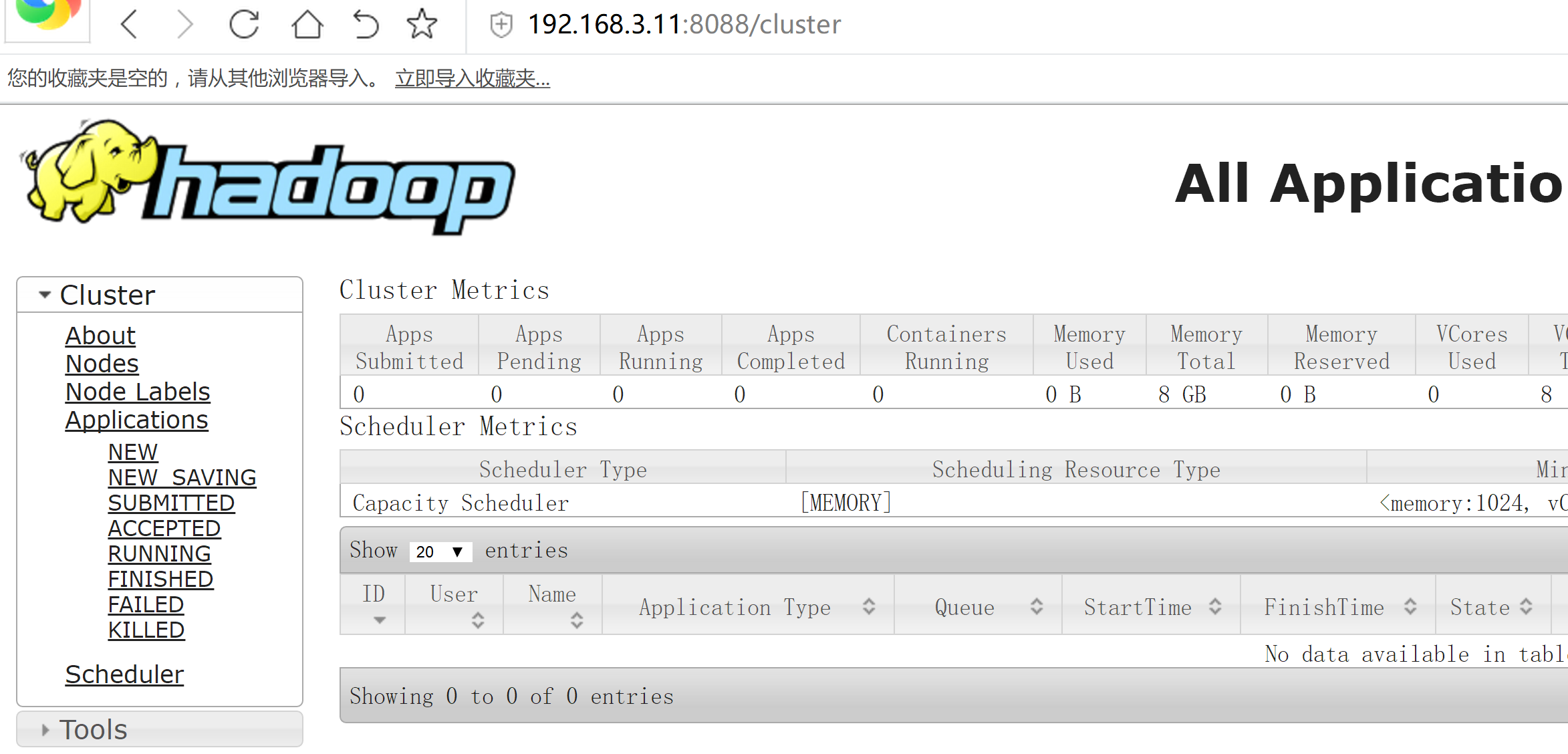
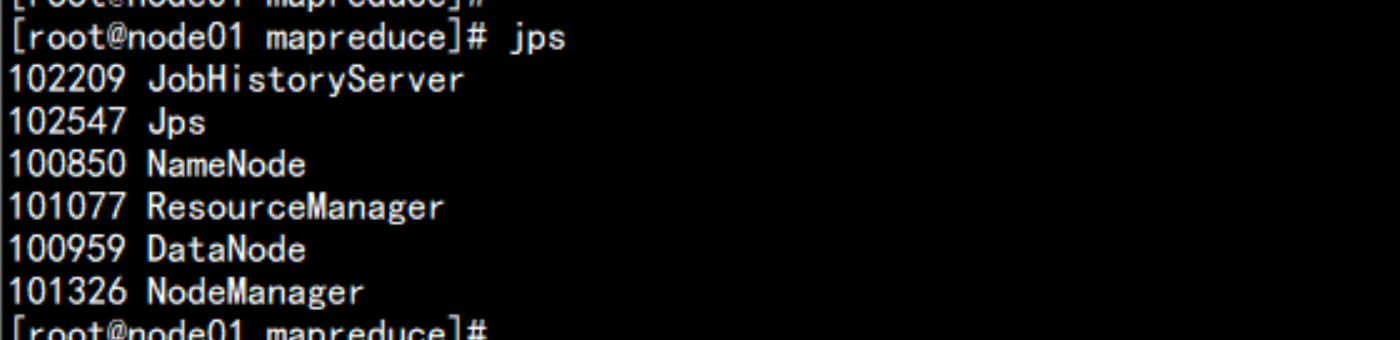
三:运行wordcount测试
hdfs dfs -mkdir /input
vim file1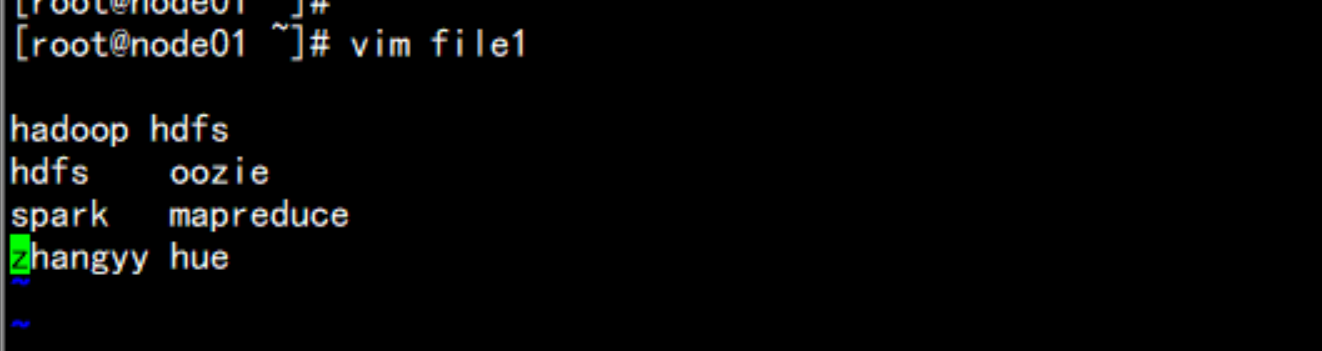
hdfs dfs -put file1 /input
cd /soft/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.7.4.jar wordcount /input /output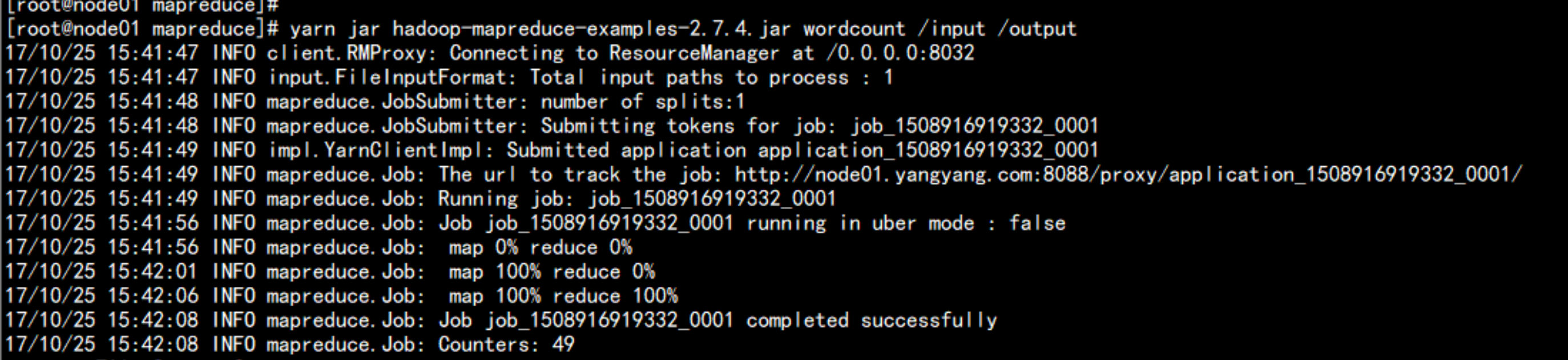
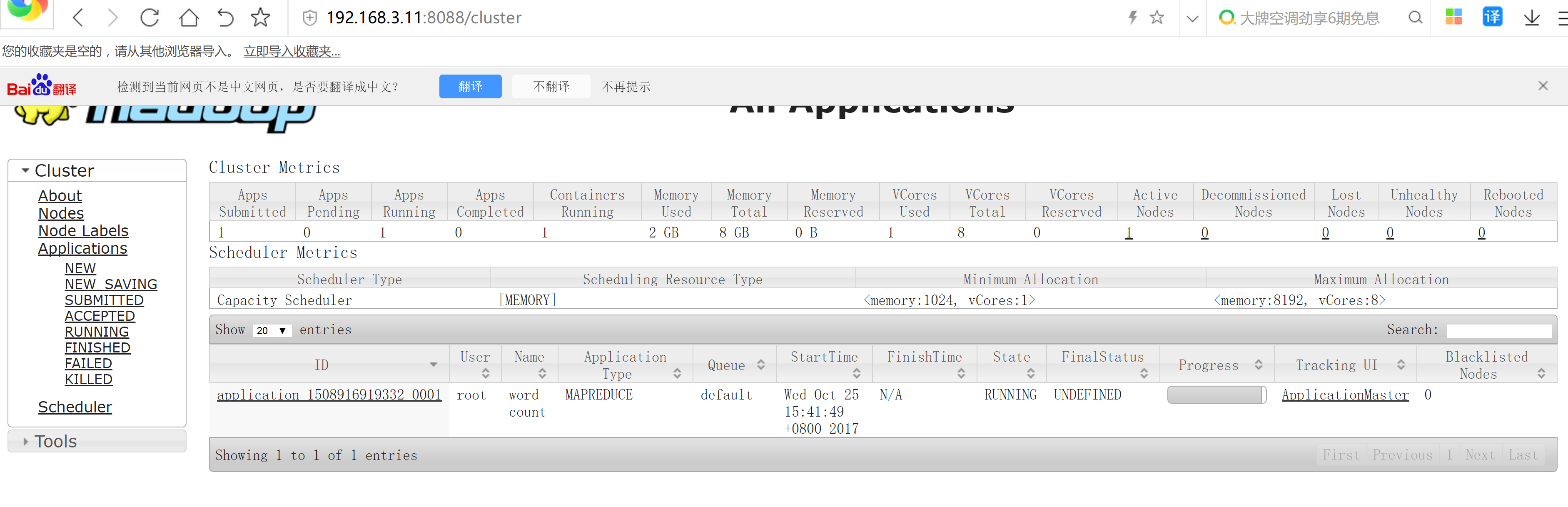
hdfs dfs -ls /output
hdfs dfs -get /output 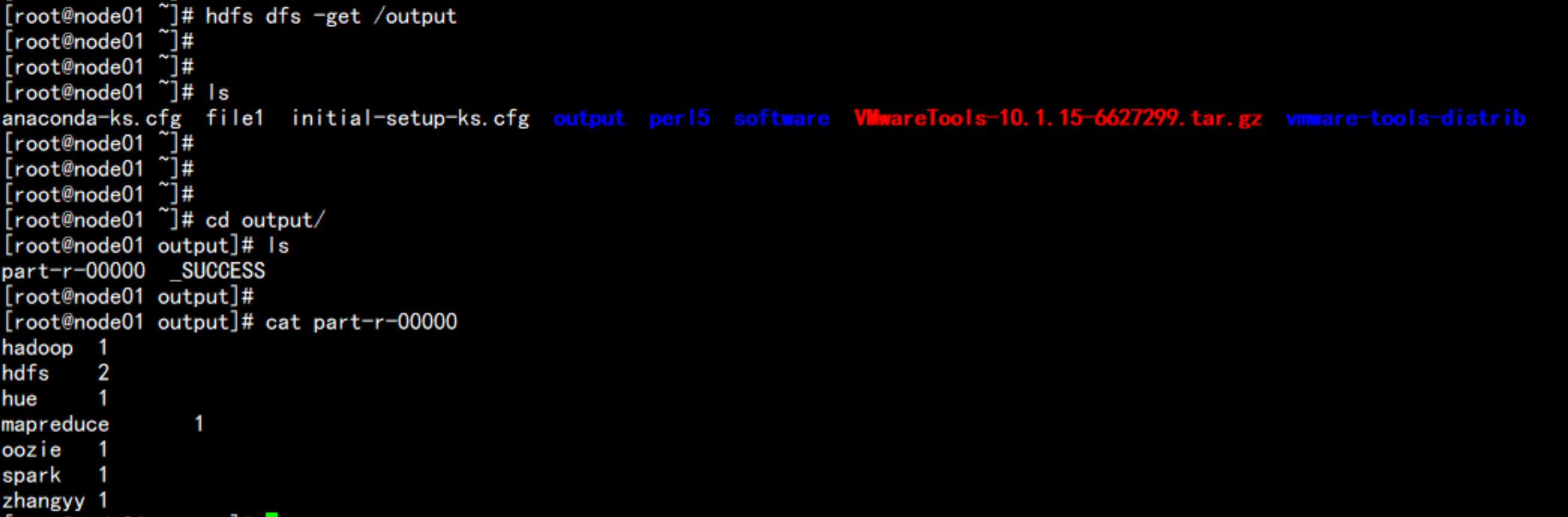

启动jobhistoryserver
mr-jobhistory-daemon.sh start historyserver
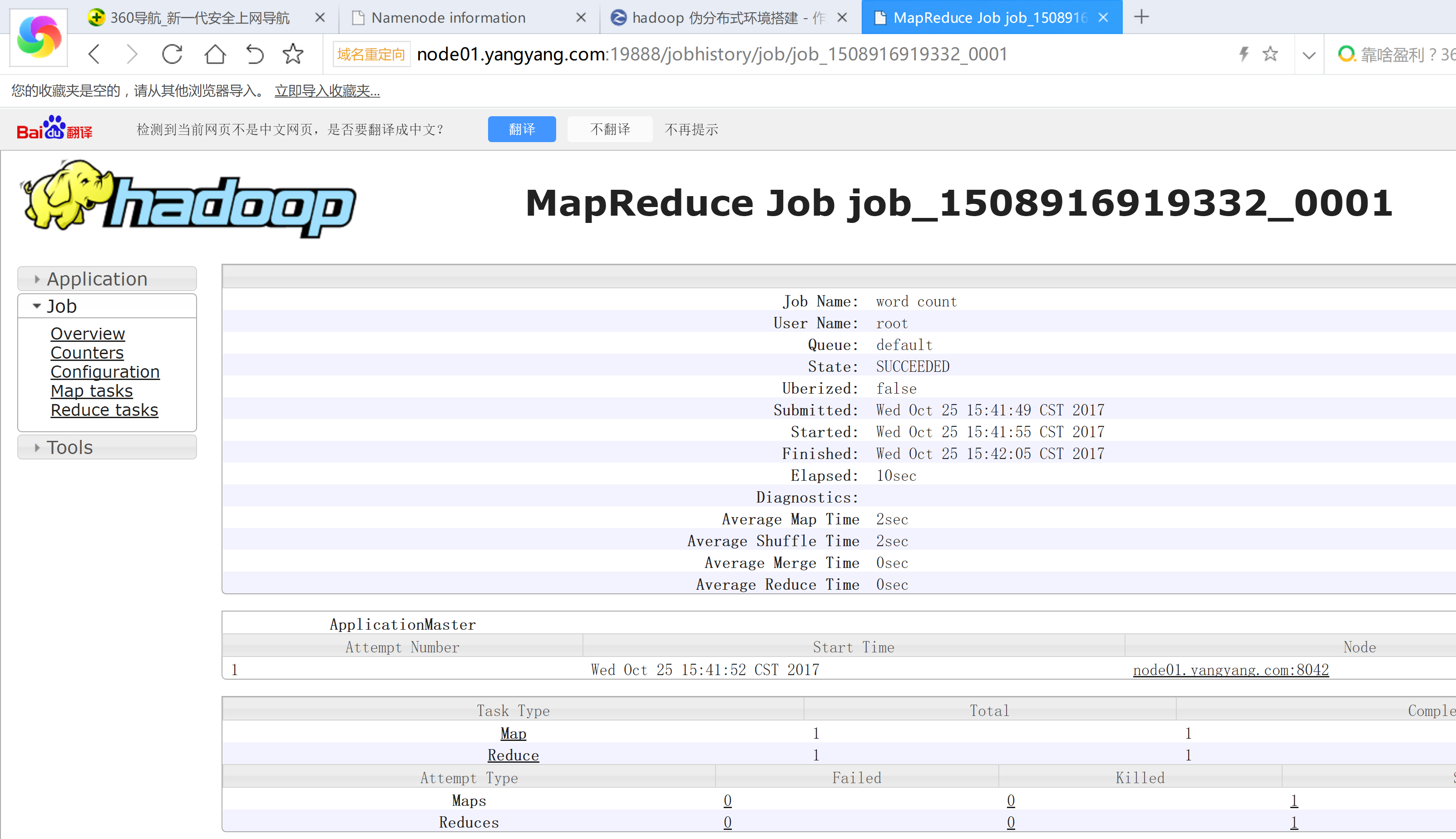
四: hadoop 常用端口号:
50070 //namenode http port
50075 //datanode http port
50090 //SecondaryNameNode http port
8020 // namenode rpc port
50010 // datanode rpc port
8088 //yarn http port
8042 //nodemanager http port
19888 // jobhistoryserver http port五: hadoop的四大模块包含
common
hdfs // namenode + datanode+ secondarynamenode
mapred
yarn //rescourcemanager + nodemanager六: 启动脚本:
1. start-all.sh // 启动所有进程
2. stop-all.sh // 停止所有进程
3. start-dfs.sh //
NN ,DN , SNN
4. start-yarn.sh //
RM,NM以上是关于hadoop的简介与伪分布的搭建的主要内容,如果未能解决你的问题,请参考以下文章