大数据的概述
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据的概述相关的知识,希望对你有一定的参考价值。
- 一. 大数据的应用场景
- 二. hadoop 2.x 概述
- 三. hadoop 2.x 的生态系统
一:大数据的应用场景
-
1.1 2015 大数据峰会:
过去7年我们从互联网创业到互联网产业,很快进入互联网经济, 而且正在从IT走向DT时代,也许昨天称为IT领袖峰会,未来要称DT领袖峰会, DT不仅仅 是技术提升,而是思想观念的提升。 DT和IT时代区别,IT以我为中心,DT以别人为中心,DT要让企业越来越强大, 让你员工强大。DT越来越讲究开放、透明。 我们所有企业都要思考什么样的文化、什么样的组织、 什么样的人才才能适应未来DT时代,相信整个DT时代到来,在海外这被称为D经济。 -
1.2 大数据hadoop的应用
大数据应用分析 1)统计 2)推荐 3)机器学习 4)人工智能,预测(算法) SQL on Hadoop 1)Hive 2)Prestore 3)Impala 4)Phoneix(基于HBase) 5)Spark SQL - 1.3 大数据的4V特性
大数据的特征(4V+1O):
数据量大(Volume)。第一个特征是数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
类型繁多(Variety)。第二个特征是种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
价值密度低(Value)。第三个特征是数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
速度快时效高(Velocity)。第四个特征数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
数据是在线的(Online)。数据是永远在线的,是随时能调用和计算的,这是大数据区别于传统数据最大的特征。现在我们所谈到的大数据不仅仅是大,更重要的是数据变的在线了,这是互联网高速发展背景下的特点。比如,对于打车工具,客户的数据和出租司机数据都是实时在线的,这样的数据才有意义。如果是放在磁盘中而且是离线的,这些数据远远不如在线的商业价值大。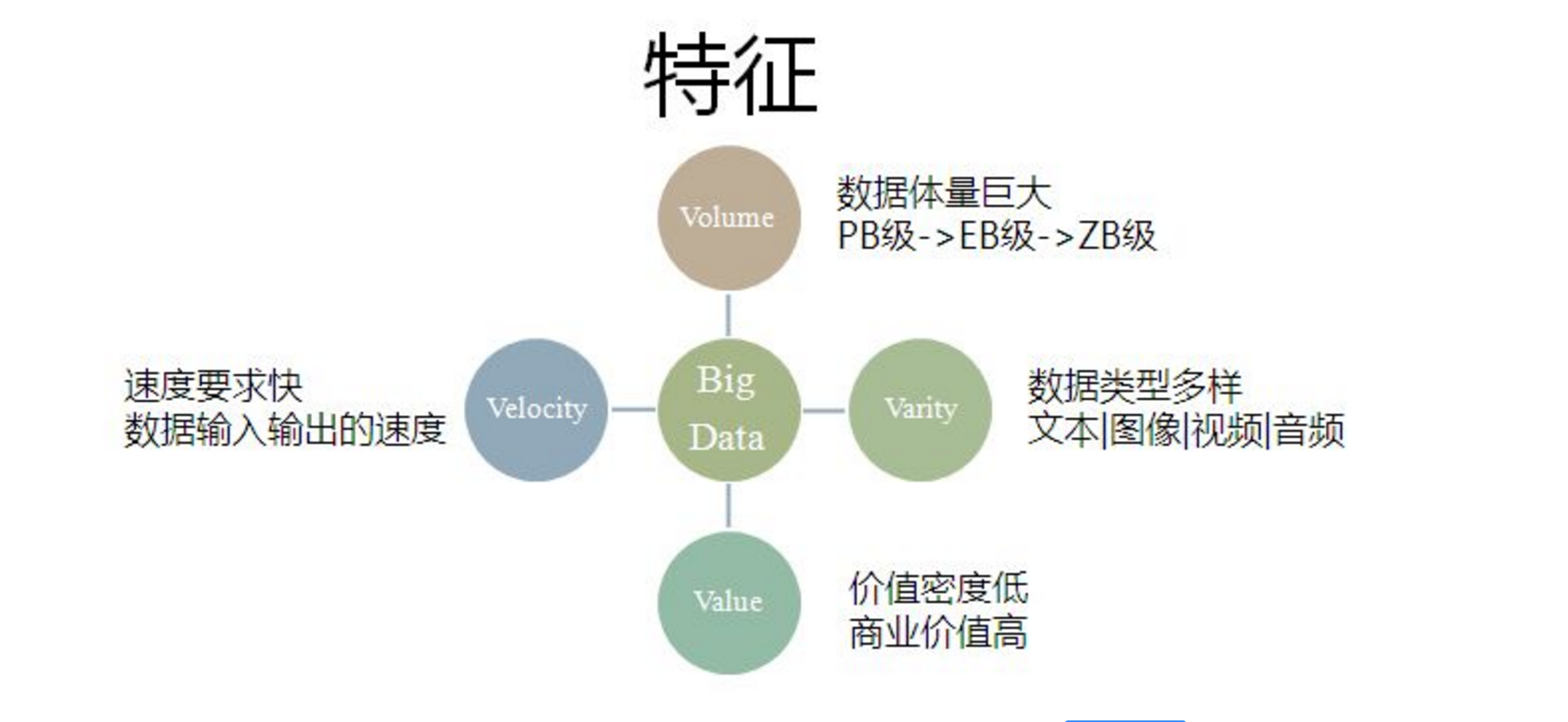
二: hadoop 2.x 的概述
-
2.1 hadoop 包含的四大模块
Hadoop Common: 为其他Hadoop模块提供基础设施。 Hadoop HDFS: 一个高可靠、高吞吐量的分布式文件系统 Hadoop MapReduce: 一个分布式的离线并行计算框架 Hadoop YARN: 一个新的MapReduce框架,任务调度与资源管理 -
2.2 apache hadoop 的起源
Apache Lucene: 开源的高性能全文检索工具包 Apache Nutch: 开源的 Web 搜索引擎 Google 三大论文: MapReduce / GFS / BigTable Apache Hadoop: 大规模数据处理 -
2.3 HDFS 系统架构图
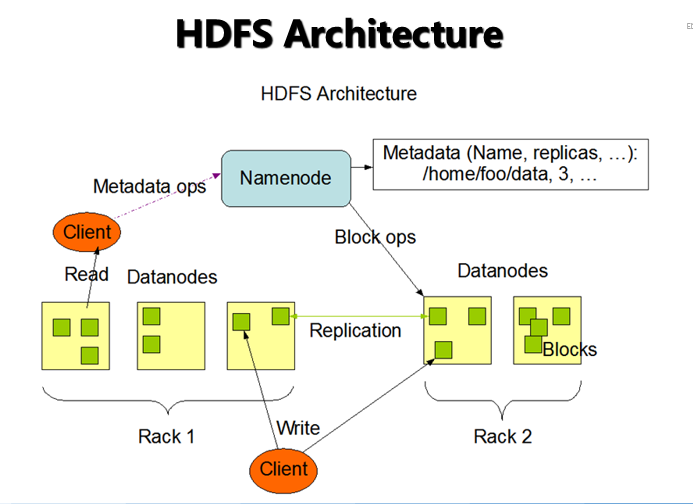
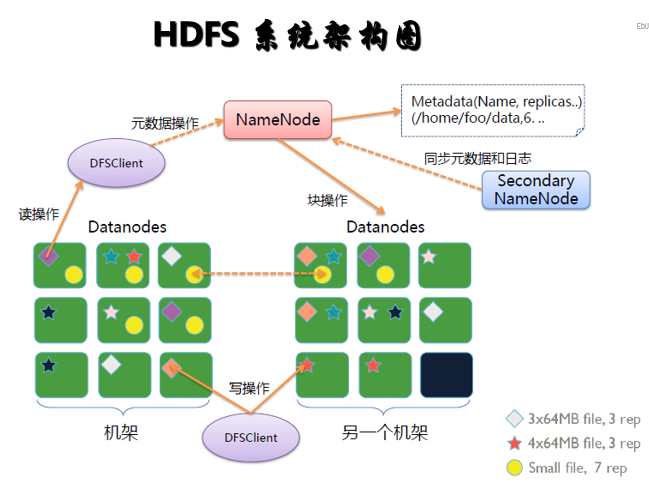
HDFS 服务功能
NameNode
主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。
DataNode
在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照- 2.4 YARN 架构图

YARN 服务功能
ResourceManager
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配与调度
NodeManager
单个节点上的资源管理
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
ApplicationMaster
数据切分
为应用程序申请资源,并分配给内部任务
任务监控与容错
Container
对任务运行环境的抽象,封装了CPU内存等多维资源以及环境变量、启动命令等任务运 行相关的信息.离线计算框架 MapReduce
一: 将计算过程分为两个阶段,map和reduce
map 阶段并行处理输入数据
reduce 阶段对map 结果进行汇总。
二:shuffle 连接map 和Reduce 两个阶段
map task 将数据写到本地磁盘
reduce task 从每个map TASK 上读取一份数据
三: 仅适合 离线批处理
具有很好的容错性和扩展性
适合简单的批处理任务
四: 缺点明显
启动开销大,过多使用磁盘导致效率底下等。
-
2.5 MapReduce on YARN
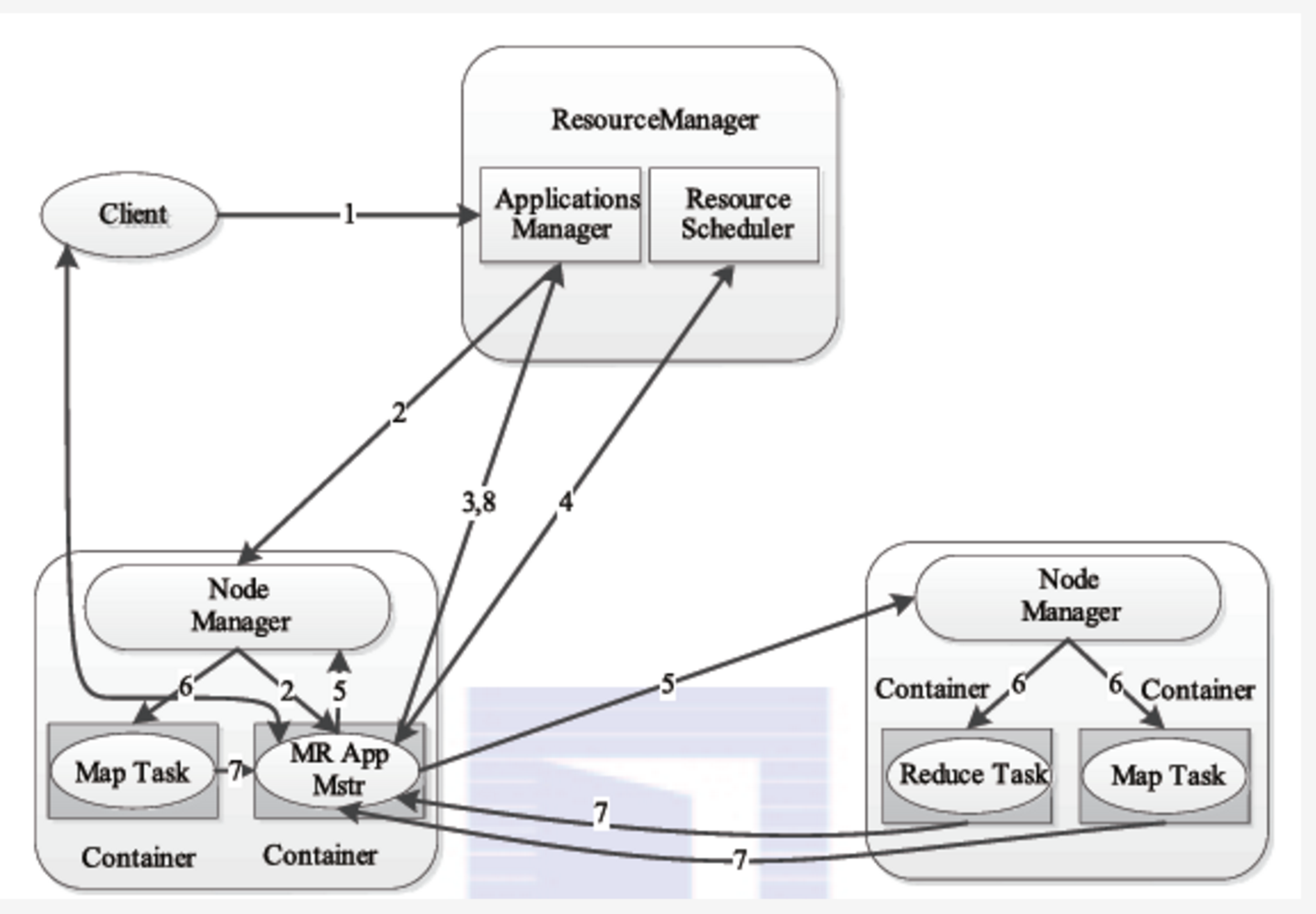
1)用户向YARN中提交应用程序/作业,其中包括ApplicaitonMaster程序、启动ApplicationMaster的命令、用户程序等; 2)ResourceManager为作业分配第一个Container,并与对应的NodeManager通信,要求它在这个Containter中启动该作业的ApplicationMaster; 3)ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查询作业的运行状态;然后它将为各个任务申请资源并监控任务的运行状态,直到运行结束。即重复步骤4-7; 4)ApplicationMaster采用轮询的方式通过RPC请求向ResourceManager申请和领取资源; 5)一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务; 6)NodeManager启动任务; 7)各个任务通过RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicaitonMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务; 在作业运行过程中,用户可随时通过RPC向ApplicationMaster查询作业当前运行状态; 8)作业完成后,ApplicationMaster向ResourceManager注销并关闭自己;
三. hadoop 2.x 的生态系统
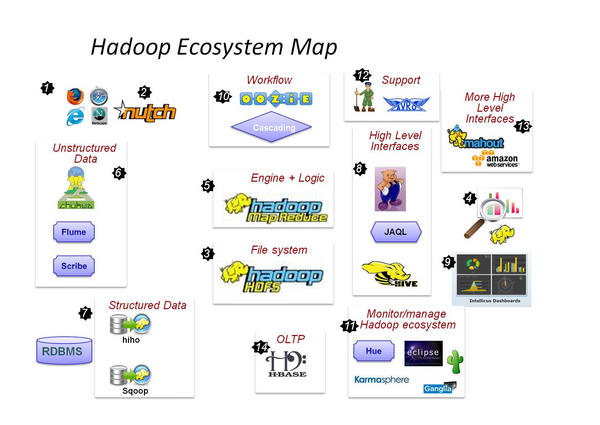
数据抓取系统 - Nutch 海量数据怎么存,当然是用分布式文件系统 - HDFS 数据怎么用呢,分析,处理 MapReduce框架,让你编写代码来实现对大数据的分析工作 非结构化数据(日志)收集处理 - fuse,webdav, chukwa, flume, Scribe 数据导入到HDFS中,至此RDBSM也可以加入HDFS的狂欢了 - Hiho, sqoop MapReduce太麻烦,好吧,让你用熟悉的方式来操作Hadoop里的数据 – Pig, Hive, Jaql 让你的数据可见 - drilldown, Intellicus 用高级语言管理你的任务流 – oozie, Cascading Hadoop当然也有自己的监控管理工具 – Hue, karmasphere, eclipse plugin, cacti, ganglia 数据序列化处理与任务调度 – Avro, Zookeeper 更多构建在Hadoop上层的服务 – Mahout, Elastic map Reduce OLTP存储系统 – Hbase
以上是关于大数据的概述的主要内容,如果未能解决你的问题,请参考以下文章
14.VisualVM使用详解15.VisualVM堆查看器使用的内存不足19.class文件--文件结构--魔数20.文件结构--常量池21.文件结构访问标志(2个字节)22.类加载机制概(代码片段