pandas读取excel文件出错啥原因?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas读取excel文件出错啥原因?相关的知识,希望对你有一定的参考价值。
代码如下:import pandas as pdimport xlrdf = open("D:/python/input.xlsx")content = pd.read_excel(f)print(content)请高手指点下
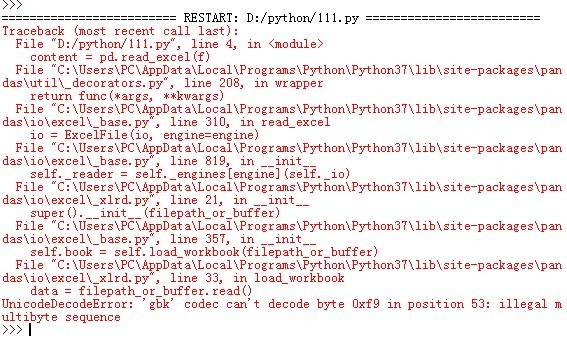
FileNotFoundError: [Errno 2] No such file or directory: 'J:/Pepole.xlsx'
这表示此文件在你电脑中不存在,请检查该路径的合法性! 参考技术A import pandas as pd
import openpyxl
df = pd.read_excel(r"D:/python/input.xlsx", engine='openpyxl')
print(df)
读取 CSV 文件时 Python Pandas 出错
【中文标题】读取 CSV 文件时 Python Pandas 出错【英文标题】:Error in Python Pandas when Reading CSV File 【发布时间】:2020-01-29 08:33:28 【问题描述】:我正在尝试读取一个 CSV 文件,但它抛出了一个错误。我无法理解我的语法有什么问题,或者我需要向我的 read_csv 添加更多属性。
我尝试了解决方案
UnicodeDecodeError: 'utf-8' 编解码器无法解码位置 0x96 字节 21:无效的起始字节 也是。但它不起作用
import pandas as pd
#Assign file_path variable
file_path = 'rawdump_24th_Sep.csv'
#assign dataframe
df1 = pd.read_csv(file_path,index_col=0)
df.head()
[错误]
UnicodeDecodeError Traceback(最近调用 最后)pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_tokens()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_with_dtype()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._string_convert()
pandas/_libs/parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: 'utf-8' 编解码器无法解码位置 0x96 字节 21: 无效的起始字节
在处理上述异常的过程中,又发生了一个异常:
UnicodeDecodeError Traceback(最近调用 最后)在 6 7 #分配数据帧 ----> 8 df1 = pd.read_csv(file_path,index_col=0) 9 10 df.head()
~\Anaconda3\lib\site-packages\pandas\io\parsers.py 在 parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols,挤压,前缀,mangle_dupe_cols,dtype,引擎,转换器, true_values、false_values、skipinitialspace、skirows、skipfooter、 nrows,na_values,keep_default_na,na_filter,详细, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser,dayfirst,迭代器,块大小,压缩,数千, 十进制,换行符,quotechar,quoting,doublequote,escapechar, 注释、编码、方言、tupleize_cols、error_bad_lines、 warn_bad_lines,delim_whitespace,low_memory,memory_map, 浮点精度) 第700章 701 --> 702 返回_read(filepath_or_buffer, kwds) 703 704 parser_f.名称=名称
~\Anaconda3\lib\site-packages\pandas\io\parsers.py 在 _read(filepath_or_buffer, kwds) 433 434 尝试: --> 435 数据 = parser.read(nrows) 最后436: 第437章
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1137 def 读取(self, nrows=None): 1138 nrows = _validate_integer('nrows', nrows) -> 1139 ret = self._engine.read(nrows) 1140 1141 # 可能改变列/col_dict
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1993 def read(self, nrows=None): 1994 尝试: -> 1995 data = self._reader.read(nrows) 1996 除了 StopIteration: 1997 if self._first_chunk:
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._read_low_memory()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._read_rows()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_column_data()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_tokens()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_with_dtype()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._string_convert()
pandas/_libs/parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: 'utf-8' 编解码器无法解码位置 0x96 字节 21: 无效的起始字节`
更新
import pandas as pd
#Assign file_path variable
file_path = 'rawdump_24th_Sep.csv'
#assign dataframe
df1 = pd.read_csv(file_path,index_col=0)
df1.head()
UnicodeDecodeError Traceback(最近调用 最后)pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_tokens()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_with_dtype()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._string_convert()
pandas/_libs/parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: 'utf-8' 编解码器无法解码位置 0x96 字节 21: 无效的起始字节
在处理上述异常的过程中,又发生了一个异常:
UnicodeDecodeError Traceback(最近调用 最后)在 6 7 #分配数据帧 ----> 8 df1 = pd.read_csv(file_path,index_col=0) 9 10 df1.head()
~\Anaconda3\lib\site-packages\pandas\io\parsers.py 在 parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols,挤压,前缀,mangle_dupe_cols,dtype,引擎,转换器, true_values、false_values、skipinitialspace、skirows、skipfooter、 nrows,na_values,keep_default_na,na_filter,详细, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser,dayfirst,迭代器,块大小,压缩,数千, 十进制,换行符,quotechar,quoting,doublequote,escapechar, 注释、编码、方言、tupleize_cols、error_bad_lines、 warn_bad_lines,delim_whitespace,low_memory,memory_map, 浮点精度) 第700章 701 --> 702 返回_read(filepath_or_buffer, kwds) 703 704 parser_f.名称=名称
~\Anaconda3\lib\site-packages\pandas\io\parsers.py 在 _read(filepath_or_buffer, kwds) 433 434 尝试: --> 435 数据 = parser.read(nrows) 最后436: 第437章
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1137 def 读取(self, nrows=None): 1138 nrows = _validate_integer('nrows', nrows) -> 1139 ret = self._engine.read(nrows) 1140 1141 # 可能改变列/col_dict
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1993 def read(self, nrows=None): 1994 尝试: -> 1995 data = self._reader.read(nrows) 1996 除了 StopIteration: 1997 if self._first_chunk:
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._read_low_memory()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._read_rows()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_column_data()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_tokens()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._convert_with_dtype()
pandas/_libs/parsers.pyx 在 pandas._libs.parsers.TextReader._string_convert()
pandas/_libs/parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: 'utf-8' 编解码器无法解码位置 0x96 字节 21: 无效的起始字节
【问题讨论】:
***.com/questions/18171739/… 谢谢迈克尔 它工作。现在可以通过将 encoding = "ISO-8859-1" 添加到 read_csv 来使用它 【参考方案1】:'rawdump_24th_Sep.csv' 应该在保存 .py 文件的同一文件夹中
import pandas as pd
df1 = pd.read_csv('rawdump_24th_Sep.csv')
df1
【讨论】:
将 df 更改为 df1。该文件与提到的位置位于同一文件夹中。通过将 df 更改为 df1 更新了我上面的问题 尝试了同样的错误 'utf-8' 编解码器无法解码位置 21 中的字节 0x96:无效起始字节【参考方案2】:如果您的 csv 文件不适合,那么您可能会收到此错误。您应该尝试另一个数据集。
【讨论】:
以上是关于pandas读取excel文件出错啥原因?的主要内容,如果未能解决你的问题,请参考以下文章