“在古时候,人们用牛来拉重物。当一头牛拉不动一根圆木时,人们从来没有考虑过要想方设法培育出一种更强壮的牛。同理,我们也不该想方设法打造什么超级计算机,而应该千方百计综合利用更多计算机来解决问题。”
——Grace Hopper
1.1数据爆炸
随着互联网的发展,积累的数据量在不断增加,呈现出数据爆炸的现象。二十一世纪初的的时候,Google发布了他们处理庞大数据使用的“三架马车”的论文,三架马车分别是GFS、MapReduce和Bigtable,随后Apache Lucene的创始人Doug Cutting实现了“三架马车”的大数据开源框架Hadoop。关于Hadoop这个名字由来是一件比较有趣的事,Hadoop之父Doug Cutting这样解释:
“这个名字是我的孩子给他的毛绒象玩具取的。我的命名标准是好拼读,含义宽泛,不会被用于其他地方。小朋友是这方面的高手。Googol就是他们起的。”
数据“洪流”有很多来源。以下面列出的为例:
- 纽约证交所每天产生的交易数据大约在4TB至5TB之间;
- Facebook存储的照片超过2400亿张,并以每月至少7PB的速度增长;
- Ancestry.com存储的数据约为10PB;
- 互联网档案馆存储的数据约为18.5PB;
- 瑞士日内瓦附近的大型强子对撞机每年产生的数据约为30PB。
以Astrometry.net为例,主要查看和分析Flicker网站上天体测量兴趣小组所拍摄的星空照片。
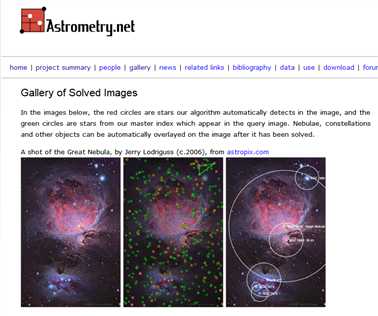
有句话说得好:“大数据胜于好算法。”不论算法多牛,基于小数据的推荐效果往往都不如基于大量可用数据的一般算法的推荐效果。
1.2数据存储与分析
对于如此庞大的数据,在这些年,我们的存储设备磁盘容量提高了一些,但是读写速度却没有比较大的提升。于是通过多个硬盘并行读写数据可以比较好的提升数据存储的速度,但还有更多问题要解决。
- 需要解决的是硬件故障问题。
- 大多数分析任务需要以某种方式结合大部分数据来共同完成分析。
1.3查询所有数据
Hadoop通过MapReduce来查询所有数据,关于MapReduce,以后的博客会有介绍。举个实际应用MapReduce的例子,Rackspace公司的邮件部门Mailtrust就用Hadoop来处理邮件日志。他们写了一条特别的查询用于帮助找出用户的地理分布。他们是这么描述的:“这些数据非常有用,我们每月运行一次MapReduce任务来帮助我们决定扩容时将新的邮件服务器放在哪些Rackspace数据中心。”
在过去几年中,出现了许多不同的,能与Hadoop协同工作的处理模式。以下是一些例子。
- 交互式SQL(impala,Hive)
- 迭代处理(spark)
- 流处理(storm,spark streaming,samza)
- 搜索(solr)