男子用AI人工智能技术还原蒙娜丽莎,网友直呼不够美
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了男子用AI人工智能技术还原蒙娜丽莎,网友直呼不够美相关的知识,希望对你有一定的参考价值。
参考技术A人工智能已经变得非常容易被公众使用,这使其非常受欢迎。各地的艺术家都在结合自己的技能和AI来进行各种编辑。甚至大多数应用程序都具有使用AI的过滤器,以使您看起来更老,更年轻,甚至性别不同。
这位总部位于旧金山的图形艺术家使用这项新技术来查看著名的绘画和卡通人物在现实情况下的外观,以及人工智能如何从绘画或钞票上的肖像中再现 历史 人物。
内森(Nathan)在他的网站上说:“我是技术总监,创意技术专家,视觉效果主管和动态图形艺术家,拥有十多年的经验。目前正在 探索 艺术与人工智能的交集。”
让我们欣赏一下人工智能仿真模拟的魅力吧!
伦勃朗
内森·希普利(Nathan Shipley)为我们回答了一些问题。他告诉我们是什么激发了他进行这些编辑的灵感:“一方面,我喜欢创建不可能的图像并 探索 新技术。我拥有动画和视觉效果的背景,一旦我看到了使用AI和机器学习可以实现的目标我意识到使用这些工具可以完成很多事情,否则这些事情是不可能的,甚至在VFX和CG上在技术上可能实现的某些事情仍然非常耗时或昂贵,而AI则带来了全新的可能性。
另一方面, 探索 建立在具有特定框架的特定数据集上的AI模型如何“看到”世界然后转换图像也很有趣。AI仅“知道”已经看到的内容,并通过此镜头过滤整个世界。对数据集,训练参数,模型和输入图像的每个小调整都可以更改输出。这是一个 探索 人造神经网络如何以与我们自己的思维相似的方式解释世界的空间。我并不是说我创建的图像是Mona Lisa实际的样子,而是机器根据这种特殊的变量排列看待她的方式。对我来说,这很令人着迷。”
#蜘蛛侠# 里的Miles Morales
“我一直喜欢绘画,拍照和绘画。自从上小学以来,我就一直使用计算机,使用的是286,带有MS-DOS,没有硬盘。传统艺术与技术的结合是一种我很自然地迈出了第一步,并带领我从事了视觉特效和动画领域。
我目前对使用AI和机器学习 探索 人脸操纵和生成艺术的兴趣始于萨尔瓦多·达利博物馆的一个名为Dali Lives的项目,该项目于2018年开始。我使用早期的Deepfake代码将Dali带回博物馆,与参观者讨论他的艺术。从这里开始,我开始研究GAN,并意识到神经网络对于图像处理和生成有多么强大!对我来说,创造艺术既是好奇心的表达,也是通过过程的 探索 行为。”
#世界名画# 蒙娜丽莎
超人特工队的Elastigirl
“关于艺术创作,我最喜欢的部分是实际的创作过程;旅程以及随之而来的所有 探索 。我喜欢遇到问题,却不知道该如何解决,戴上耳机,迷失方向时间,然后尝试尝试直到可行。
看到完成的图像真是太好了,但是尝试新代码,以非本意的方式使用代码,将不同的工具组合在一起并通过新的流程创造出全新的艺术品,这将更加令人兴奋。”
来自可可的Miguel
本杰明·富兰克林
内森(Nathan)有一个4岁的儿子,他喜欢和他一起 探索 世界:“我们钓鱼,去海滩,绘画,绘画,阅读,打棒球和假装。否则我喜欢跑步-它使我平静下来,让我集中精神。”
艺术家告诉我们更多有关他自己的信息:“我只是一个来自美国中西部的人。我在印第安纳州长大,就读于印第安纳大学,然后在印第安纳波利斯赛车场从事电视动画制作工作。准备离开印第安纳州去加利福尼亚。
我很幸运能够在没有任何计划的情况下,先有机会环游世界一年,然后再前往旧金山。我以单程机票飞往秘鲁利马,并在接下来的12个月里住在南美,东欧,土耳其,印度和泰国的一些城市。如果到了自己喜欢的地方,我就住了一个月。
出差旅行,对世界充满好奇并结识许多不同的人,这与创造艺术和一般生活息息相关。
我最终确实到达了旧金山,在过去的十年中,我在Google,Intel以及目前的广告代理商Goodby,Silverstein&Partners从事动画,VFX和创意技术项目。
弗里达·卡罗
乔治华盛顿
内森(Nathan)解释了他是如何创建这些编辑的:“这是一个非常反复和 探索 性的过程。用最简单的术语来说,人脸被用作软件的输入,并且软件根据输入生成新的人脸。绘画或卡通人物的“真实”版本,以及真实人物的卡通版本。
更具体地说,要创建真实的人,该过程的中心部分使用机器学习来查找与Nvidia创建的AI网络中的面孔形状相似的人。该网络是使用GAN(一种机器学习框架,称为GAN)创建的,并在70,000人脸的数据集(称为FFHQ)上进行了训练。人工智能学会了如何概括人脸的外观,然后可以生成实际上并不存在但看起来非常真实的新人脸。
由于该网络是根据真实人物的图像进行训练的,因此即使您输入的只是一幅图画或绘画,它也非常善于创建更多真实人物。
我还有其他示例使用同一工具(StyleGAN)根据Aesop寓言插图的400年木刻,Beeple的日常生活库甚至是自定义数据集创建新图像,以为Qrion和Hiatus等音乐家制作音乐视频。很多这些都是在我的网站在这里。”
迭戈·里维拉
“我从动画和VFX的背景中使用了一套核心工具(Photoshop,After Effects,C4D,Maya,Nuke),但最有趣的工具通常来自学者和机器学习研究人员发布的Github回购协议。这些是通常是通过在控制机器学习库(如Tensorflow或PyTorch)的Linux机器上编辑Python代码来运行的。
实际上,关于这些面部图像的几乎所有内容都直接来自Python代码。我对 探索 Nvidia的StyleGAN和一个称为pixel2style2pixel的StyleGAN编码器特别感兴趣。”
内森说,实际的图像需要花费几分钟的时间来创建,但是他必须走很长的一段路才能学到所有东西:“我需要指出的所有学习和背景都是经过几年的 探索 和反复试验。我甚至在2019年参加了麻省理工学院的一次名为GANocracy的会议。
例如,我建立了一个美术播放器,可以实时生成全新的,永无止境的,完全新颖的艺术品。框架是即时制作的!但是,训练模型并为玩家编写代码需要花费数周的工作和处理时间。”
伦勃朗
安德鲁·杰克逊
艺术家分享了他如何选择要重现人物或角色的方式:“我选择自己喜欢的人物(例如,来自Coco的米格尔)或我们实际上没有照片的 历史 人物。其他的,但是当获得引人注目的结果时,确实是令人兴奋的!其中很多是反复试验,我只是在公开分享自己进行的测试。
例如,我很想看看蒙娜丽莎(Mona Lisa)可能是什么样子,现在我有了一张可能像她的逼真的面孔。我并不是说这是蒙娜丽莎,但有可能。
莉·米克拉(Lil Miquela)
难以置信的先生,感觉很熟悉,你们补充
“总的来说,我认为生成艺术和AI艺术的领域非常有趣,而且值得深入研究。我当然会鼓励感兴趣的读者尝试一下!技术上的障碍似乎令人生畏,但有一定的背景知识,您真的可以通过很多方式使用Google。
这也是学者和研究人员以非常学术或听起来复杂的方式介绍这些技术的一种方式。理解一篇名为“用于生成对抗网络的基于样式的生成器体系结构”的论文似乎令人生畏。但是,看到由具有相同技术的艺术家创作的图像可能会非常鼓舞人心!
我强烈鼓励读者阅读Memo Akten,Scott Eaton,Mario Klingemann,Refik Anandol,Helena Sarin和Ben Snell的著作。这些艺术家对于我 探索 AI和机器学习的兴趣非常重要。”
迭戈·里维拉
尤利西斯·格兰特(Ulysses S.Grant)
这个也好熟悉,交给动漫迷们补充啦~
伦勃朗
这个一定是随机的,不认识不认识
伦勃朗
#飞屋环游记# 里的小男孩罗素Russell
蒙娜丽莎Rap的秘密 这个AI算法绝不能错过
蒙娜丽莎说 Rap、苏轼先生开口念诗、Gollum 唱 Black Pink 的 Ice Cream。是的,你没有看错,本篇给大家介绍的这个 AI 算法可以让你零基础5分钟实现上述超级 Fancy 的特效,亲手制作点击量过百万、霸榜热搜的超级视频。
话不多说,让我们先看效果!


不仅如此哦~最近大火的虚拟美妆博主柳夜熙、上周百度发布的央视总台首个 AI 手语主播以及各大虚拟偶像等等数字人的核心技术中,让数字人开口说话的也是这个 AI 算法。
那这到底是什么神奇的技术呢?
答案就是飞桨开源套件 PaddleGAN 中的新晋宠儿——Wav2lip 模型
赶紧上项目查看源码及文档教程吧,这个项目还提供热门 GAN 模型,如 AnimeGANv2、GauGAN、First Order Motion 的实现,开源不易,希望大家 Star 支持!
https://github.com/PaddlePaddle/PaddleGAN/blob/develop/README_cn.md

更贴心的是,完整项目代码已公开于 AI Studio,大家动动手指即可体验:
https://aistudio.baidu.com/aistudio/projectdetail/3156519?ref=baiduai2
下面给大家拆解下技术原理和具体的操作步骤,手把手教你实现苏轼念诗,蒙娜丽莎唱 Rap 或者任何你心仪的 Idol 说情话⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄。
这是一个输入一段语音,使目标人物图片、视频的唇形,根据语音进行自动匹配并运动起来的任务。因此,我们需要准备一段音频和一段人像/动漫人物视频,将音频和视频输入 Wav2lip 模型中,经过 Wav2lip 模型预测后,便会输出一段目标人物/动漫人物说出输入音频的视频,至此,「千万级」配音视频就完成啦~

PaddleGAN 的唇形迁移能力——Wav2lip
Wav2lip 模型实现唇形与语音精准同步突破的关键在于:
-
采用了唇形同步判别器,以强制生成器持续产生准确而逼真的唇部运动。
-
此外,通过在鉴别器中,使用多个连续帧而不是单个帧,并使用视觉质量损失(而不仅仅是对比损失)来考虑时间相关性,从而改善了视觉质量。
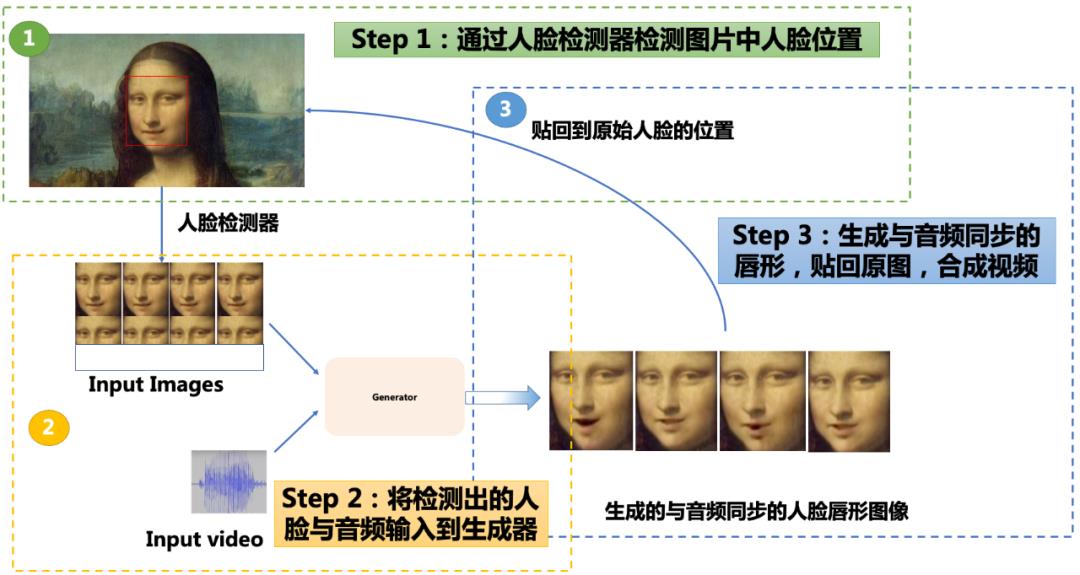
万能的 Wav2lip 模型适用于任何人脸、任何语音、任何语言!对任意视频都能达到很高的准确率,都可以实现无缝地与原始视频融合,无论是视频效果还是语音效果都很逼真。
与此同时,PaddleGAN 针对 Wav2Lip 模型进行了高清优化,使唇形拟合更细腻,更加逼真。

PaddleGAN Wav2lip 的使用方法
在 PaddleGAN 的帮助下,完成上述神奇的自制「配音/对口型」只需两步:
1、下载 PaddleGAN 并所需安装包
# 下载 PaddlePaddle 安装包
# 从 github 上克隆 PaddleGAN 代码(如下载速度过慢,可用 gitee 源)
!git clone
https://gitee.com/PaddlePaddle/PaddleGAN
#!git clone
https://github.com/PaddlePaddle/PaddleGAN
#本地安装 PaddleGAN
%cd /home/aistudio/PaddleGAN
!pip install -v -e .
!pip install -r requirements.txt
!pip install librosa!pip install numba==0.53.1
2、使用唇形合成命令
%cd applications/
!python tools/wav2lip.py \\
--face /home/aistudio/1.jpeg \\
--audio /home/aistudio/2.m4a \\
--outfile /home/aistudio/pp_put.mp4 \\
--face_enhancement
只需在如下命令中的 face 参数和 audio 参数分别换成自己的视频和音频路径,然后运行即可生成和音频同步的视频,运行完成后,会在当前文件夹下生成文件名为 outfile 参数指定的视频文件,该文件即为和音频同步的视频文件:
-
lface:原始视频,视频中的人物的唇形将根据音频进行唇形合成
-
laudio:驱动唇形合成的音频,视频中的人物将根据此音频进行唇形合成
-
loutfile:成品视频名
-
lface_enhancement:添加人脸增加特效
PaddleGAN 的花样玩法
以为 PaddleGAN 就止于此?NoNoNo~
免费开源的宝藏套件 PaddleGAN 的能力当然不止于唇形迁移/生成的技术,里面满满都是种类丰富、趣味的图像/视频生成、处理能力。热门的前沿模型,如 AnimeGANv2、GauGAN、First Order Motion 等模型等待大家探索。
如图像风格迁移、视频修复、图像超分辨率、人像动漫化、照片动漫化、人脸编辑等等。


PaddleGAN 就如一个「游乐场」,欢迎各位「玩家」加入,体验各类「游戏设施」,无需门票,如果玩得开心,记得点 Star 支持下~
https://github.com/PaddlePaddle/PaddleGAN/blob/develop/README_cn.md

以上是关于男子用AI人工智能技术还原蒙娜丽莎,网友直呼不够美的主要内容,如果未能解决你的问题,请参考以下文章
程序员加班崩溃,过路外卖小哥主动帮忙改代码,网友直呼太暖了!