一、问题描述:
数据库中字段 nvarchar类型 存放数据如下:
‘3.3×10‘
二、解决方案:
--测试用例
CREATE TABLE #temp
(NAME NVARCHAR(20) null)
INSERT INTO #temp select FecalColiform from WaterQuality
select * from #temp
update #temp set Name=replace(Name,‘‘,‘‘) ; --- 1
update #temp set Name=replace(Name,‘‘,‘‘) ; --- 2
update #temp set Name=replace(Name,‘‘,‘‘) ; --- 3
update #temp set Name=replace(Name,‘‘,‘‘) ; --- 4
--结果有效 。
--实际项目运用
update WaterQuality set FecalColiform=replace(FecalColiform,‘‘,‘‘) ; --- 1
update WaterQuality set FecalColiform=replace(FecalColiform,‘‘,‘‘) ; --- 2
update WaterQuality set FecalColiform=replace(FecalColiform,‘‘,‘‘) ; --- 3
update WaterQuality set FecalColiform=replace(FecalColiform,‘‘,‘‘) ; --- 4
你可能有一个疑问 为什么重复执行相同的操作??
答:‘‘ 这个东西看起来相同,实际又各不相同。
你需要完整的复制出该列,然后全部选中看他们的后面凹凸状态 是否都为空了。
然后把那些没修改成功的空格单独复制出来再修改。
例如 复制出放入单引号中观察 ‘2.0×10‘ ,然后复制出它的特有的‘’,然后在执行一次修改。
修改前:
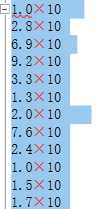
修改后:

三、失败经验:
1.trim方法
select ltrim(‘ 3.3×10‘) --去除左边的空格
select rtrim(‘3.3×10 ‘) --去除右边的空格
select ltrim(rtrim(‘ 3.3×10 ‘)) --去除首尾空格
结果有效。
但是真实的数据是这样的 ‘3.3×10‘
select ltrim(rtrim(‘3.3×10‘)) --去除首尾空格
结果无效。
参考过的文章:
https://zhidao.baidu.com/question/183968041.html
https://www.cnblogs.com/TurboWay/p/5924445.html