大数据笔记(十八)——Pig的自定义函数
Posted lingluo2017
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据笔记(十八)——Pig的自定义函数相关的知识,希望对你有一定的参考价值。
Pig的自定义函数有三种:
1、自定义过滤函数:相当于where条件
2、自定义运算函数:
3、自定义加载函数:使用load语句加载数据,生成一个bag
默认:一行解析成一个Tuple
需要MR的jar包
一.自定义过滤函数
package demo.pig; import java.io.IOException; import org.apache.pig.FilterFunc; import org.apache.pig.data.Tuple; //实现自定义的过滤函数,实现:查询过滤薪水大于2000的员工 public class IsSalaryTooHigh extends FilterFunc{ @Override public Boolean exec(Tuple tuple) throws IOException { /*参数tuple:调用的时候 传递的参数 * * 在PigLatin调用 * myresult1 = filter emp by demo.pig.IsSalaryTooHigh(sal) */ //取出薪水 int sal = (int) tuple.get(0); return sal>2000?true:false; } }
二.自定义运算函数
package demo.pig; import java.io.IOException; import org.apache.pig.EvalFunc; import org.apache.pig.data.Tuple; //根据员工的薪水判断级别 public class CheckSalaryGrade extends EvalFunc<String>{ @Override public String exec(Tuple tuple) throws IOException { // myresult2 = foreach emp generate ename,sal,demo.pig.CheckSalaryGrade(sal); int sal = (int)tuple.get(0); if(sal<1000) return "Grade A"; else if(sal>=1000 && sal<3000) return "Grade B"; else return "Grade C"; } }
三.自定义加载函数
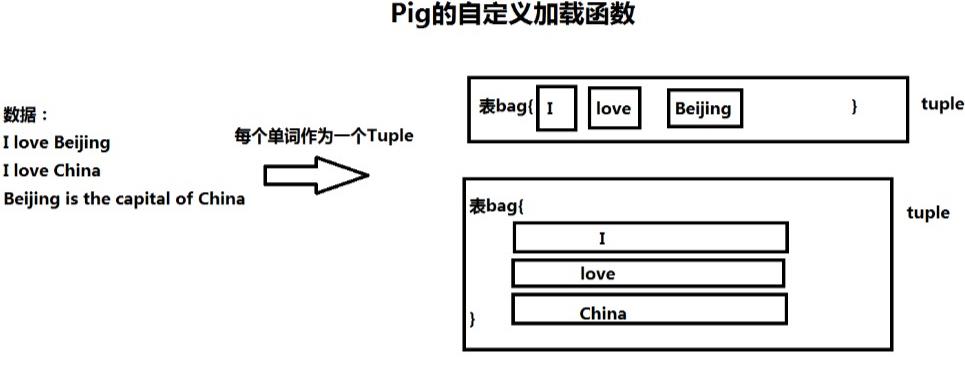
package demo.pig; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.pig.LoadFunc; import org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigSplit; import org.apache.pig.data.BagFactory; import org.apache.pig.data.DataBag; import org.apache.pig.data.Tuple; import org.apache.pig.data.TupleFactory; public class MyLoadFunc extends LoadFunc{ //定义一个变量保存输入流 private RecordReader reader ; @Override public InputFormat getInputFormat() throws IOException { // 输入数据的格式:字符串 return new TextInputFormat(); } @Override public Tuple getNext() throws IOException { // 从输入流读取一行,如何解析生成返回的tuple //数据:I love Beijing Tuple result = null; try{ //判断是否读入了数据 if(!this.reader.nextKeyValue()){ //没有数据 return result; //----> 是nullֵ } //数据:I love Beijing String data = this.reader.getCurrentValue().toString(); //生成返回的结果:Tuple result = TupleFactory.getInstance().newTuple(); //分词 String[] words = data.split(" "); //每一个单词单独生成一个tuple,再把tuple放入bag中 //再把这个bag放入result中 //创建一个表 DataBag bag = BagFactory.getInstance().newDefaultBag(); for(String w:words){ //为每个单词生成一个tuple Tuple aTuple = TupleFactory.getInstance().newTuple(); aTuple.append(w); //将单词放到tuple中 //把这些tuple放入一个bag中 bag.add(aTuple); } //把bag放入result result.append(bag); }catch(Exception ex){ ex.printStackTrace(); } return result; } @Override public void prepareToRead(RecordReader reader, PigSplit arg1) throws IOException { // RecordReader reader:代表HDFS输入流 this.reader = reader; } @Override public void setLocation(String path, Job job) throws IOException { // 从HDFS输入的路径 FileInputFormat.setInputPaths(job, new Path(path)); } }
注册jar包: register define
register /root/temp/p1.jar
myresult3 = load \'/input/data.txt\' using demo.pig.MyLoadFunc();
定义别名:define myload demo.pig.MyLoadFunc;

以上是关于大数据笔记(十八)——Pig的自定义函数的主要内容,如果未能解决你的问题,请参考以下文章