Prometheus-部署grafana及模板展示
Posted LIUXU23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus-部署grafana及模板展示相关的知识,希望对你有一定的参考价值。
文章目录
一、grafana部署及模板展示
grafana是一款基于go语言开发的通用可视化工具,支持从不同的数据源加载并展示数据,可作为其数据源的部分储存系统如下所示:
TSDB:Prometheus、IfluxDB、OpenTSDB和Graphit
日志和文档存储:Loki和ElasitchSearch
分布式请求跟踪:Zipkin、Jaeger和Tenpo
SQL DB:mysql、PostgreSQL和Microsoft SQL server
grafana基础默认监听于TCP协议的3000端口,支持集成其他认证服务,且能够通过/metrics输出内建指标;
数据源(Data Source):提供用于展示的数据的储存系统
仪表盘(Dashboard):组织和管理数据的可视化面板(Panel)
团队和用户:提供了面向企业组织层级的管理能力;
二、centos系统上的部署步骤(版本7.3.6)
rpm -ivh /opt/grafana-7.3.6-1.x86_64.rpm

systemctl start grafana-server
systemctl enable grafana-server

netstat -natp | grep :3000

192.168.32.10:3000
#账号密码默认为admin,admin
grafana默认配置文件目录 /etc/grafana/grafana.ini

#直接访问ip:8500进入grafana控制台



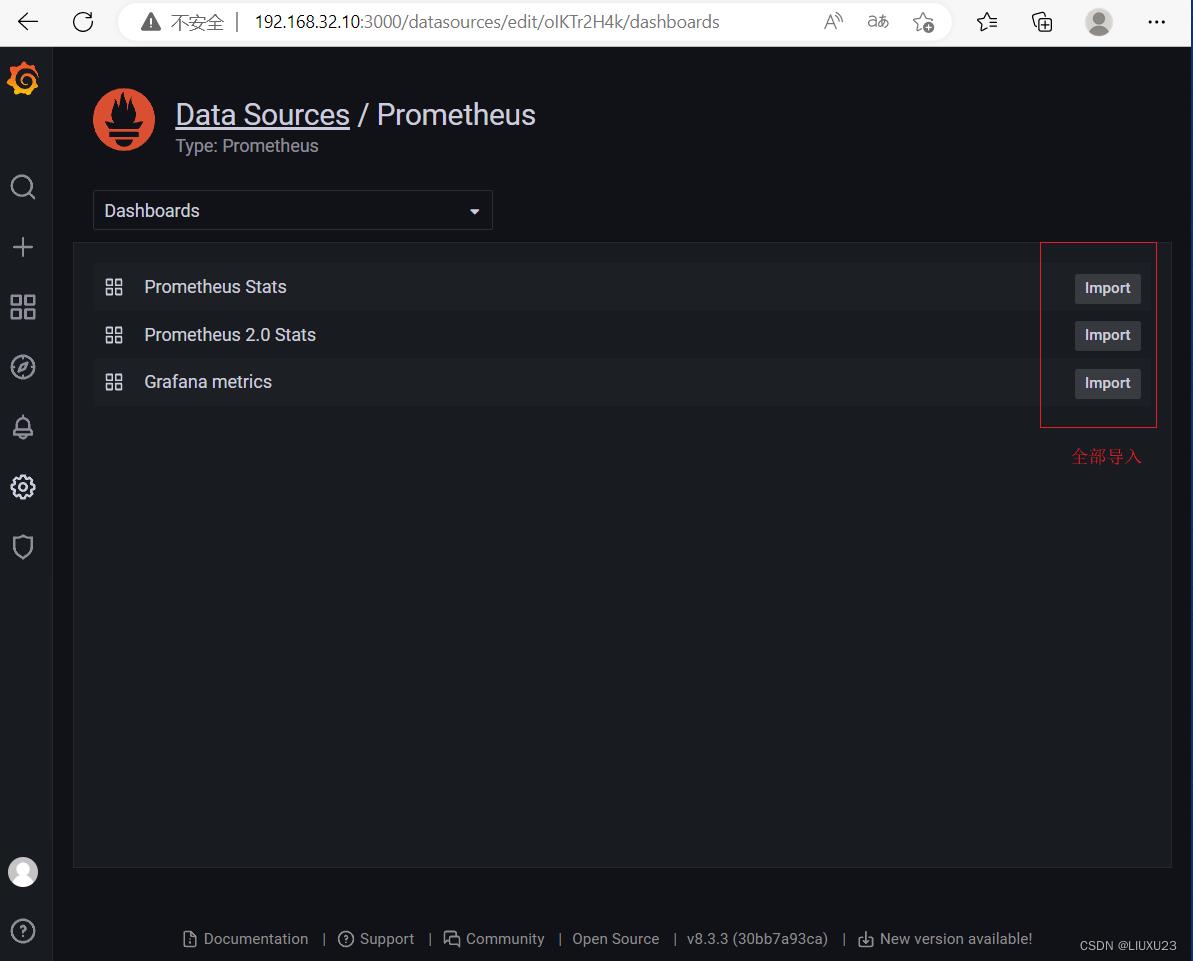


#grafana模板
浏览器访问:https://grafana.com/grafana/dashboards ,在页面中搜索 node exporter ,选择适合的面板,点击 Copy ID 或者 Download JSON

在 grafana 页面中,+ Create -> Import ,输入面板 ID 号或者上传 JSON 文件,点击 Load,即可导入监控面板
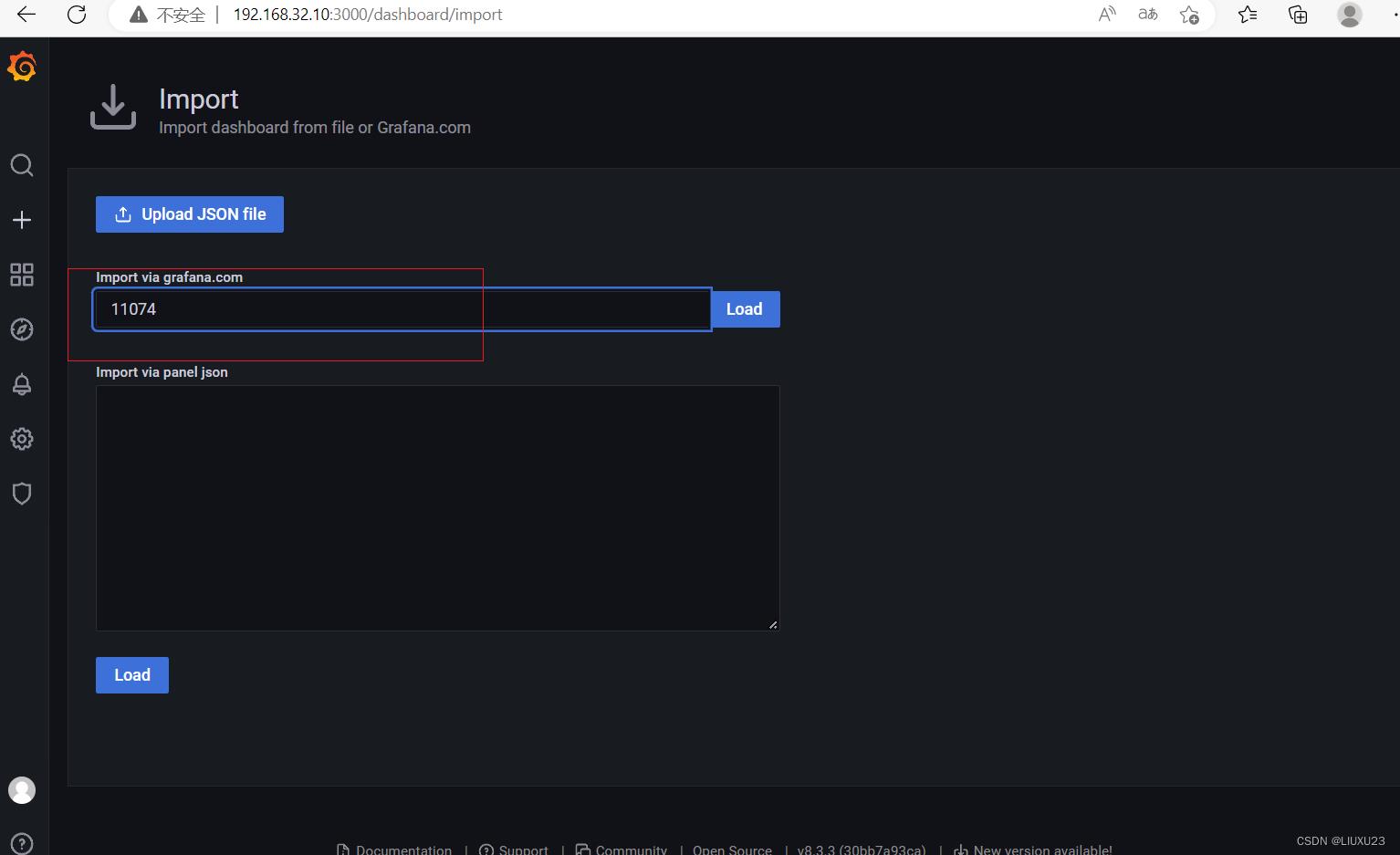

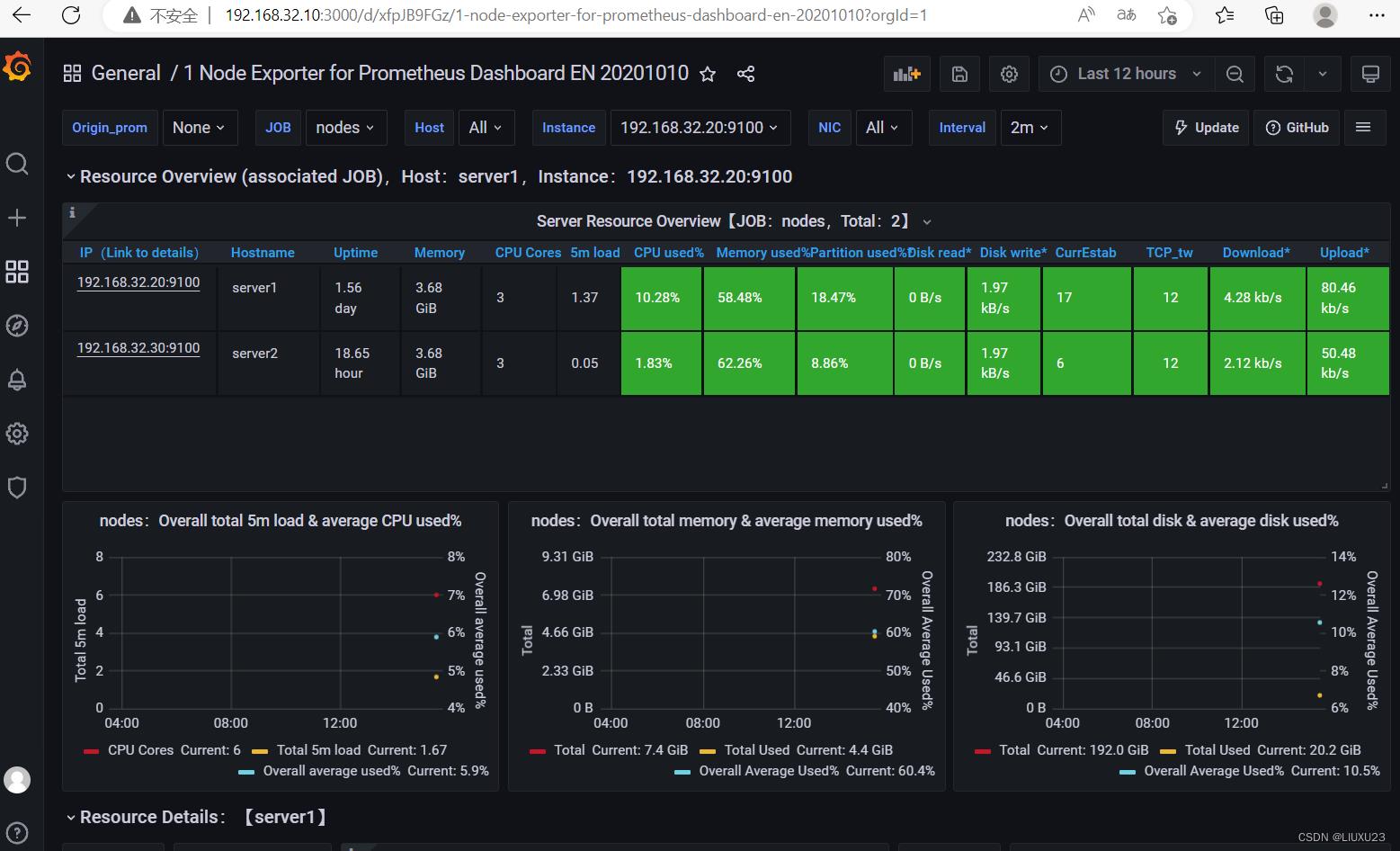
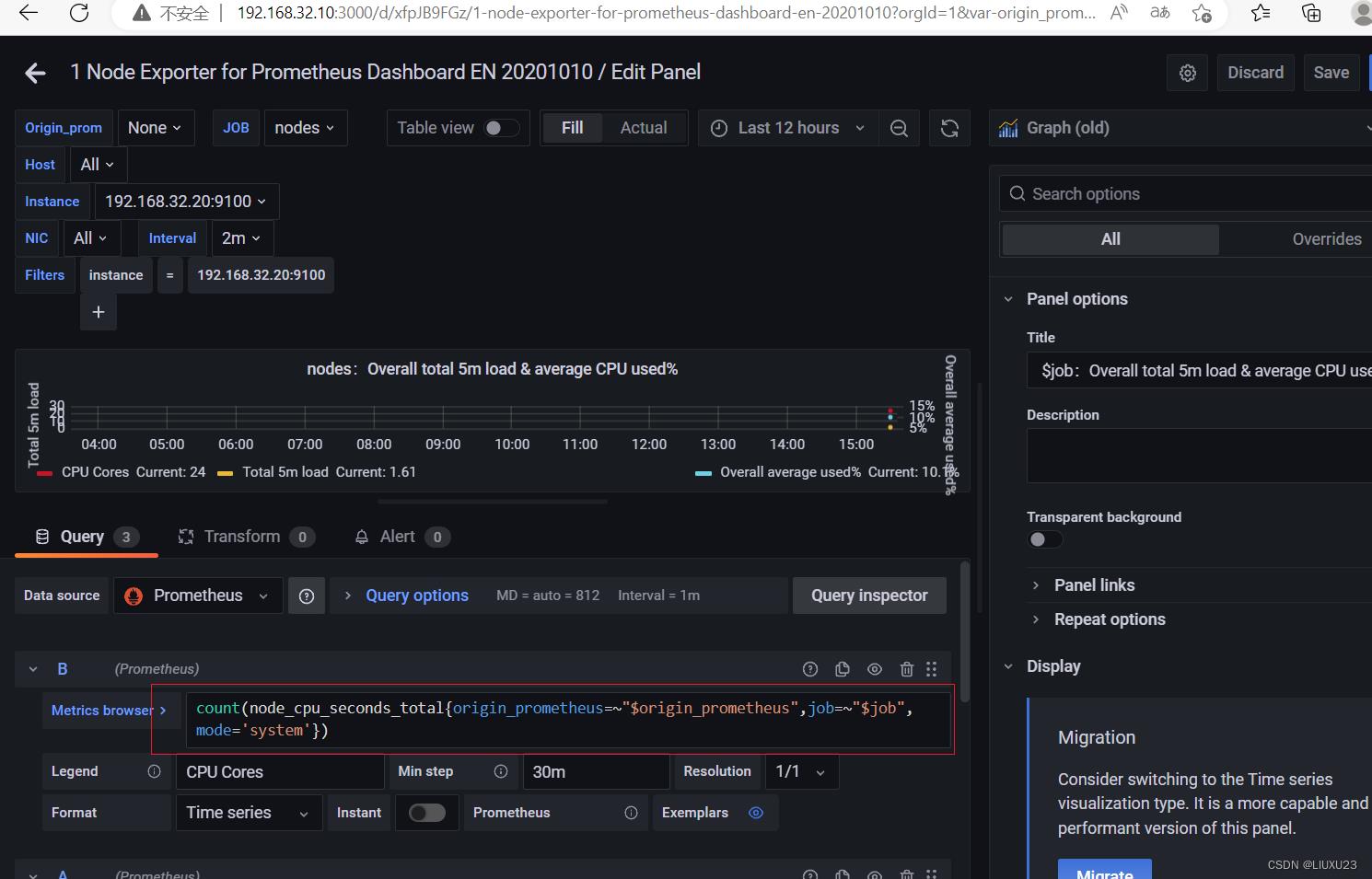
也可以选择中文版的

prometheus+grafana告警,监控部署展示
服务器信息
监控服务器
目录:/home/monitor/
nginx代理服务器
配置文件:/home/nginx/con.d/monitor
被监控服务器服务部署 数据采集
#客户端
#node-exporter主机监控 修改对应主机名
docker run -d --name node-exporter -h 主机名 --restart=always -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter
#访问url:
http://127.0.0.1:9100/metrics
#启动cadvisor容器监控 修改对应主机名
docker run -d --name=cadvisor --restart=always -h 主机名 -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro -v /dev/disk/:/dev/disk:ro -p 9200:8080 google/cadvisor:latest
#访问url:
http://127.0.0.1:9200/metrics
监控服务器部署
#启动prometheus
mkdir /home/monitor/prometheus/
cd /home/monitor/prometheus/
vim prometheus.yml
docker run -d --name prometheus --restart=always -p 9090:9090 -v /home/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /home/monitor/prometheus/data:/prometheus prom/prometheus
#访问url:
http://0.0.0.0:9090/graph
#启动grafana
mkdir /home/monitor/grafana-storage
chmod 777 -R /home/monitor/grafana-storage
docker run -d --name grafana --restart=always -p 5000:3000 --name=grafana -v /home/monitor/grafana-storage:/var/lib/grafana grafana/grafana
#访问url默认认的用户名和密码都是admin
http://127.0.0.1:3000/
#创建告警规则
docker cp /home/monitor/prometheus/rules/ prometheus:/etc/prometheus/
docker restart prometheus
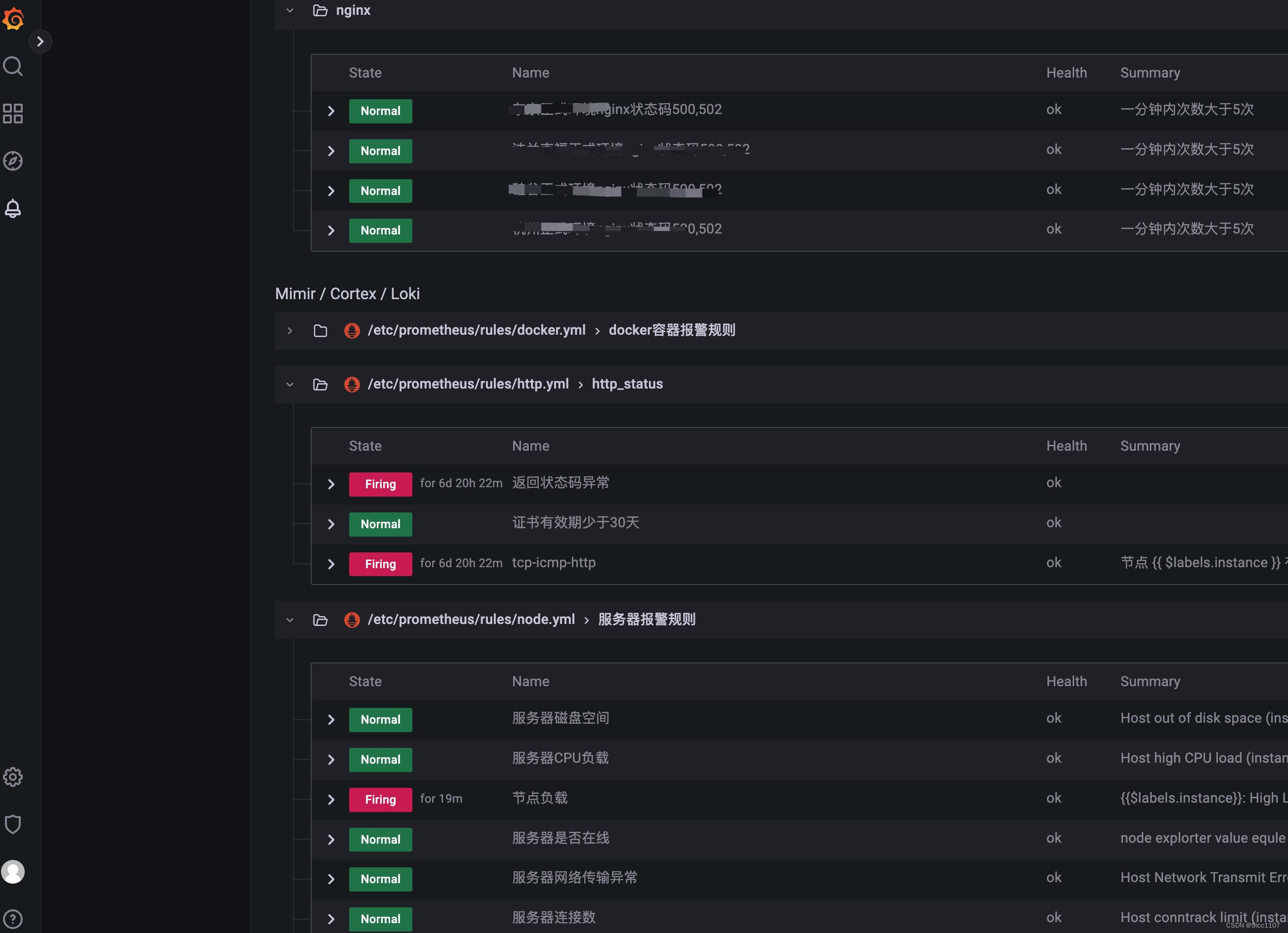
http://0.0.0.0:9090/rules #验证页面,查看告警规则是否加上
#新增钉钉机器人
#alertmanager告警接收转发器
docker run -d --name alertmanager -p 9093:9093 -v /home/monitor/alertmanager:/etc/alertmanager/ quay.io/prometheus/alertmanager --config.file=/etc/alertmanager/alertmanager.yml
#webhook-dingding钉钉告警插件
docker run -d --restart always -p 9060:8060 --name webhook-dingding -v /home/monitor/webhookdingding/dingding.tmpl:/opt/dingding.tmpl timonwong/prometheus-webhook-dingtalk:v1.4.0 --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=aaaa" --template.file="/opt/dingding.tmpl"
#测试钉钉消息发送
curl -XPOST http://127.0.0.1:9093/api/v1/alerts -d '[
"labels":
"alertname": "DiskRunningFull",
"dev": "sda1",
"instance": "中文测试",
"route": "WEBHOOK"
,
"annotations":
"info": "The disk sda1 is running full",
"summary": "please check the instance example1"
]'
#启动blackbox 监测 http tcp icmp
docker run -d --restart always --name blackbox_exporter -p 9115:9115 -v /home/monitor/blackbox/config.yml:/etc/blackbox_exporter/config.yml prom/blackbox-exporter --config.file=/etc/blackbox_exporter/config.yml
prometheus配置文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanagerip:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["prometheusip:9090"]
# Create a job for Docker daemon.
#
# This example requires Docker daemon to be configured to expose
# Prometheus metrics, as documented here:
# https://docs.docker.com/config/daemon/prometheus/
- job_name: 'mysqld-exporter'
scrape_interval: 10s
#metrics_path: /metrics
static_configs:
- targets: []
labels:
instance:
- job_name: "容器集群1 test"
static_configs:
- targets: ["被监控服务1:9200","被监控服务2:9200","被监控服务3:9200"]
labels:
instance: "docker"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: "容器集群2 sim"
static_configs:
- targets: ["被监控服务1:9200","被监控服务2:9200","被监控服务3:9200"]
labels:
instance: "docker"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: "容器集群3 pro"
static_configs:
- targets: ["被监控服务1:9200","被监控服务2:9200","被监控服务3:9200"]
labels:
instance: "docker"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: "主机集群1"
static_configs:
- targets: ["被监控服务1:9100","被监控服务2:9100","被监控服务3:9100"]
labels:
instance: "host"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: "主机集群2"
static_configs:
- targets: ["被监控服务1:9100","被监控服务2:9100","被监控服务3:9100"]
labels:
instance: "host"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: "主机集群3"
static_configs:
- targets: ["被监控服务1:9100","被监控服务2:9100","被监控服务3:9100"]
labels:
instance: "host"
relabel_configs:
- source_labels: [__address__]
target_label: instance
- job_name: 'icmp监控'
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets: ["被监控ip1","被监控ip2","被监控ip3"]
labels:
instance: node_status
group: 'node'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackboxIP:9115
- job_name: 'tcp监控'
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets: ["被监控ip1:端口","被监控ip2:端口","被监控ip3:端口"]
labels:
instance: 'port_status'
group: 'tcp'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackboxIP:9115
- job_name: 'web监控'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- https://aaa.com被监控站点
- https://bbb.com被监控站点
- https://ccc.com被监控站点
labels:
instance: dev_web_status
group: 'web'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackboxIP:9115
容器告警规则
groups:
- name: docker容器报警规则
rules:
- alert: 容器CPU使用率
expr: (sum(rate(container_cpu_usage_seconds_totalname=~".+",image!=""[3m])) BY (instance, name) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
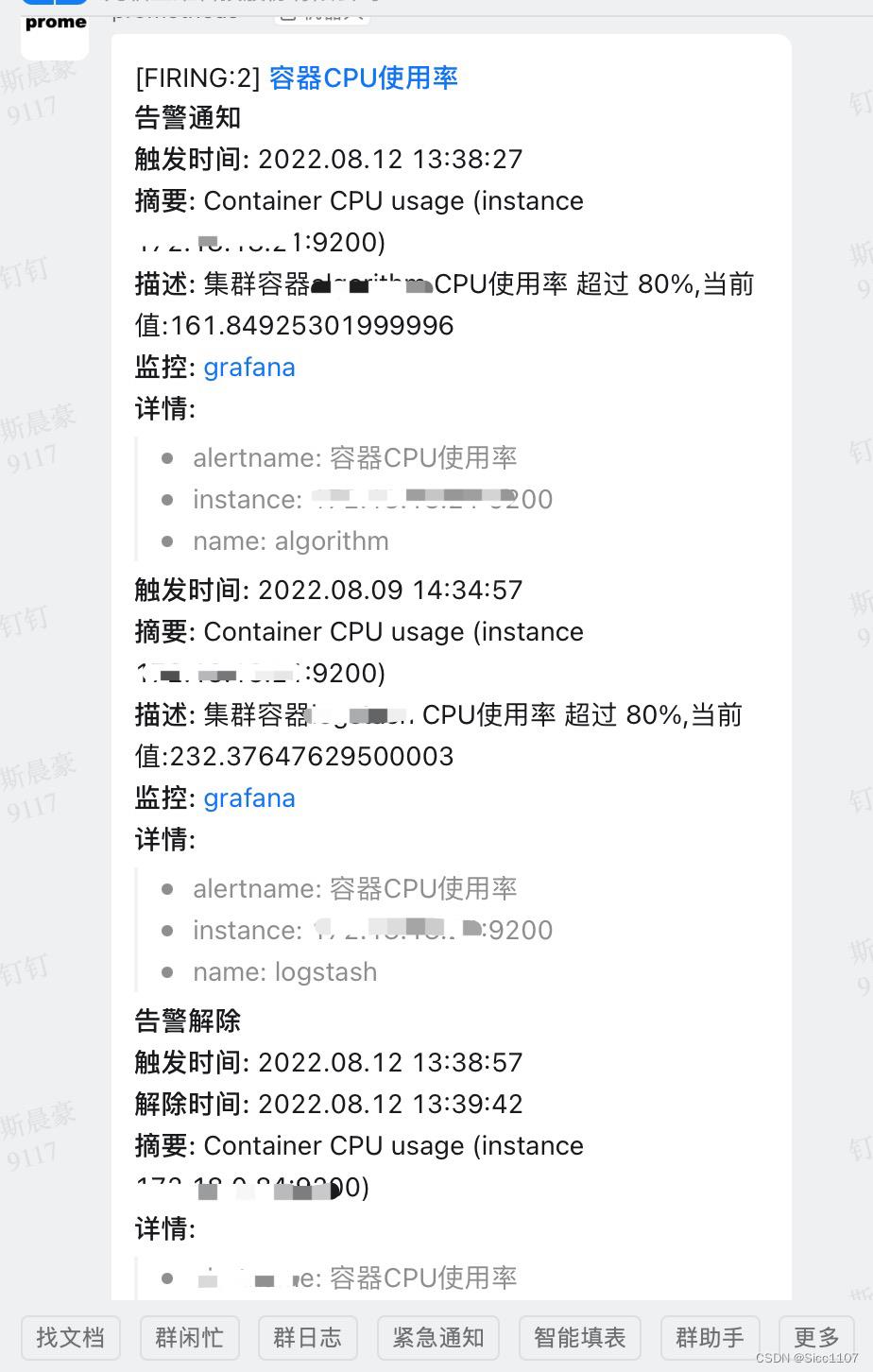
summary: Container CPU usage (instance $labels.instance )
description: "集群 $labels.job 容器 $labels.name CPU使用率 超过 80%,当前值: $value "
- alert: 容器内存使用率
expr: (sum(container_memory_working_set_bytes name=~".+",image!="" ) BY (instance, name) / sum(container_spec_memory_limit_bytes name=~".+",image!="" > 0) BY (instance, name) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: Container Memory usage (instance $labels.instance )
description: "集群 $labels.job 容器$labels.name 的内存使用率超过了80%,当前值为 $value "
# - alert: 容器磁盘使用率
# expr: (1 - (sum(container_fs_inodes_free name=~".+",image!="" ) BY (instance,name) / sum(container_fs_inodes_total name=~".+",image!="") BY(instance,name))) * 100 > 80
# for: 2m
# labels:
# severity: warning
# annotations:
# summary: Container Volume usage (instance $labels.instance )
# description: "集群 $labels.job 容器$labels.name 的磁盘使用率超过80%,当前值为 $value "
- alert: 容器磁盘IO
expr: (sum(container_fs_io_current name=~".+",image!="") BY (instance, name) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: Container Volume IO usage (instance $labels.instance )
description: "集群 $labels.job 容器$labels.name 的磁盘IO超过80%,当前值为: $value "
- alert: 容器消失
expr: rate(container_last_seenname!=""[1m]) < 0.5
# expr: time() - container_last_seen > 60
# expr: absent(container_last_seen)
for: 0m
labels:
severity: warning
annotations:
summary: Container killed (instance $labels.instance )
description: "集群 $labels.job 容器$labels.name 已被删除或停止,请检查"
主机告警规则
groups:
- name: 服务器报警规则
rules:
- alert: 服务器磁盘空间
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host out of disk space (instance $labels.instance )
description: "$labels.instance 的磁盘空间 小于10%, 目前占用$value"
- alert: 服务器CPU负载
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_totalmode="idle"[2m])) * 100) > 80
for: 0m
labels:
severity: warning
annotations:
summary: Host high CPU load (instance $labels.instance )
description: "$labels.instanceCPU负载大于80%,目前负载:$value"
- alert: 节点负载
expr: (node_load5 > 5)
for: 2m
labels:
severity: critical
annotations:
description: "$labels.instance的负载过高,告警阈值:5 当前负载:$value"
summary: '$labels.instance: High Load : $value '
- alert: 服务器是否在线
for: 0s
expr: avg_over_time(upinstance=~"$instance"[10s]) < 0.5
labels:
serverity: critical
annotations:
description: " $labels.instance 宕机超过5分钟,当前值: $value "
summary: "node explorter value equle 0"
- alert: 服务器网络传输异常
expr: rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Transmit Errors (instance $labels.instance )
description: "服务器 $labels.instance 在过去5分钟内有网络传输错误"
- alert: 服务器连接数
expr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: Host conntrack limit (instance $labels.instance )
description: " $labels.instance 的连接数 接近极限,目前连接数为value:$value"
- alert: 服务器内存
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 20
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance $labels.instance )
description: "$labels.instance 的内存剩余小于10%,目前占用$value"
http告警规则
groups:
- name: http_status
rules:
- alert: 返回状态码异常
expr: probe_http_status_code > 399
for: 1m
labels:
user: prometheus
severity: warning
annotations:
description: " $labels.instance of job $labels.job $value 网页异常"
- alert: 证书有效期少于30天
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 10m
labels:
user: prometheus
severity: warning
annotations:
description: " $labels.instance of job $labels.job $value 证书快到期"
- alert: tcp-icmp-http
expr: probe_success == 0
for: 1m
labels:
severity: critical
annotations:
summary: "节点 $labels.instance 有问题"
description: "节点 $labels.instance 有问题"
alertmanager配置文件
global:
resolve_timeout: 5m # 在没有报警的情况下声明为已解决的时间
# # 配置邮件发送信息
# smtp_smarthost: 'smtp.test.com:465'
# smtp_from: 'your_email'
# smtp_auth_username: 'your_email'
# smtp_auth_password: 'email_passwd'
# smtp_hello: 'your_email'
# smtp_require_tls: false
# 设置报警的分发策略
route:
receiver: webhook1 # 发送警报的接收者的名称,默认的receiver
group_wait: 10s # 当一个新的报警分组被创建后,需要至少等待多久时间发送一组警报的通知
group_interval: 1m # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息
repeat_interval: 24h # 报警发送成功后,重新发送等待的时间
group_by: ['alertname'] # 报警分组依据
# #子路由,使用email发送
# routes:
# - receiver: email
# match_re:
# serverity : email # label 匹配email
# group_wait: 10s
# 定义警报接收者信息
receivers:
- name: webhook1 # 与route匹配
webhook_configs:
- url: http://webhook-dingdingIP:9060/dingtalk/webhook1/send
send_resolved: true # 发送已解决通知
#- name: 'email'
# email_configs:
# - to: 'email@qq.com'
# send_resolved: true
# 抑制规则配置
#inhibit_rules:
# [ - <inhibit_rule> ... ]
#target_match:
# [ <labelname>: <labelvalue>, ... ]
#target_match_re:
# [ <labelname>: <regex>, ... ]
#source_match:
# [ <labelname>: <labelvalue>, ... ]
#source_match_re:
# [ <labelname>: <regex>, ... ]
#[ equal: '[' <labelname>, ... ']' ]
webhook-dingding钉钉告警模版
define "__subject" [ .Status | toUpper if eq .Status "firing" : .Alerts.Firing | len end ] .GroupLabels.SortedPairs.Values | join " " if gt (len .CommonLabels) (len .GroupLabels) ( with .CommonLabels.Remove .GroupLabels.Names .Values | join " " end ) end end
define "__alertmanagerURL" $alertURL := "http://10.10.1.58:9093" - $alertURL -/#/alerts?receiver= .Receiver &tmp= .ExternalURL end
define "__text_alert_list" range .
**Labels**
range .Labels.SortedPairs > - .Name : .Value | markdown | html
end
**Annotations**
range .Annotations.SortedPairs > - .Name : .Value | markdown | html
end
**Source:** [ .GeneratorURL ]( .GeneratorURL )
end end
/* Firing */
define "default.__text_alert_list" range .
**触发时间:** dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai"
**摘要:** .Annotations.summary
**描述:** .Annotations.description
**监控:** [grafana](https://monitor.aaa.com)
**详情:**
range .Labels.SortedPairs if and (ne (.Name) "severity") (ne (.Name) "summary") > - .Name : .Value | markdown | html
end end
end end
/* Resolved */
define "default.__text_resolved_list" range .
**触发时间:** dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai"
**解除时间:** dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai"
**摘要:** .Annotations.summary
**详情:**
range .Labels.SortedPairs if and (ne (.Name) "severity") (ne (.Name) "summary") > - .Name : .Value | markdown | html
end end
end end
/* Default */
define "default.title" template "__subject" . end
define "default.content" #### \\[ .Status | toUpper if eq .Status "firing" : .Alerts.Firing | len end \\] **[ index .GroupLabels "alertname" ]( template "__alertmanagerURL" . )**
if gt (len .Alerts.Firing) 0 -
**告警通知**
template "default.__text_alert_list" .Alerts.Firing
- end
if gt (len .Alerts.Resolved) 0 -
**告警解除**
template "default.__text_resolved_list" .Alerts.Resolved
- end
- end
/* Legacy */
define "legacy.title" template "__subject" . end
define "legacy.content" #### \\[ .Status | toUpper if eq .Status "firing" : .Alerts.Firing | len end \\] **[ index .GroupLabels "alertname" ]( template "__alertmanagerURL" . )**
template "__text_alert_list" .Alerts.Firing
- end
/* Following names for compatibility */
define "ding.link.title" template "default.title" . end
define "ding.link.content" template "default.content" . end
nginx代理配置文件
server
listen 80;
server_name aaa.com;
if ($scheme = http)
return 301 https://aaa.com$request_uri;
server
listen 443 ssl;
server_name aaa.com;
ssl_certificate ssl/aaa/7623463.com.pem;
ssl_certificate_key ssl/aaa/7623463.com.key;
ssl_session_timeout 5m;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
location /robots.txt
add_header Content-Type text/plain;
return 200 "User-agent: *\\nDisallow: *";
location /
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_pass http://grafanaip:5000;
grafana Dashbpards效果图 监控模版json有需要私聊
集群整体图

单台主机效果图

容器效果图

站点监控

告警效果图
以上是关于Prometheus-部署grafana及模板展示的主要内容,如果未能解决你的问题,请参考以下文章