怎么从通俗意义上理解逻辑回归的损失函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么从通俗意义上理解逻辑回归的损失函数相关的知识,希望对你有一定的参考价值。
两种都见类算,目标函数看,区别于逻辑归采用logistical loss,svm采用hinge loss.两损失函数目都增加类影响较数据点权重,减少与类关系较数据点权重.SVM处理考虑support vectors,类相关少数点,习类器.逻辑归通非线性映射,减离类平面较远点权重,相提升与类相关数据点权重.两者根本目都.外,根据需要,两都增加同则化项,l1,l2等等.所实验,两种算结接近.逻辑归相说模型更简单,理解,实现起,特别规模线性类比较便.SVM理解优化相说复杂些.SVM理论基础更加牢固,套结构化风险化理论基础,虽般使用太关注.重要点,SVM转化偶问题,类需要计算与少数几支持向量距离,进行复杂核函数计算优势明显,能够简化模型计算
svm 更属于非参数模型,logistic regression 参数模型,本质同.其区别参考参数模型非参模型区别.
logic 能做 svm能做,能准确率问题,svm能做logic做 参考技术A 两种方法都是常见的分类算法,从
目标函数
来看,区别在于逻辑回归采用的是logistical
loss,svm采用的是hinge
loss.这两个
损失函数
的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重.SVM的处理方法是只考虑support
vect。 参考技术B 有一些区别,对象里面的函数可以有返回值和没有返回值的,两种。对象直接调用方法,方法是封装体,主要的目的是保护里面的属性,想要使用的时候直接调用方法接口,而不需要知道方法里面的具体的内容。 参考技术C 两害相权取其轻。
从最大似然估计的角度理解线性回归和逻辑回归
写在前面的话
转眼学习数据分析和机器学习也有一年了,虽然上手了不少项目也实际应用过很多机器学习算法,但对于算法的原理和推导确实也还在一知半解的程度。为了知其然还要知其所以然,本篇文章就从最统计学最基础的最大似然估计来推导线性回归和逻辑回归的损失函数。
最大似然估计
通俗地来说,最大似然估计所要达成的目标就是找到一组参数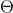 使得表达的概率分布能够在最大程度上拟合观测到的样本的联合概率分布。这句话用数学的语言表达就是:
使得表达的概率分布能够在最大程度上拟合观测到的样本的联合概率分布。这句话用数学的语言表达就是: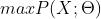 或者
或者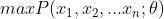 。虽然在很多非正式场合概率和似然经常被混为一谈,但是这两个概念其实是不同的。概率表达的是给定模型参数,观察到样本的概率,而似然则表达的是给定观测值后描述分布的参数是否合理。因此对于上述的问题,其实更合理的表达应为
。虽然在很多非正式场合概率和似然经常被混为一谈,但是这两个概念其实是不同的。概率表达的是给定模型参数,观察到样本的概率,而似然则表达的是给定观测值后描述分布的参数是否合理。因此对于上述的问题,其实更合理的表达应为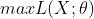 ,其中
,其中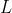 表示的就是likelihood。虽然对于问题的定义很简洁,但是实际操作起来还是有一定的问题。样本的联合概率分布可以表达为:
表示的就是likelihood。虽然对于问题的定义很简洁,但是实际操作起来还是有一定的问题。样本的联合概率分布可以表达为: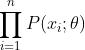 ,其中每个样本在给定参数
,其中每个样本在给定参数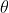 时观测到的概率一定小于1,将多个小概率连乘在实际应用中是非常不稳定的,因此可以利用
时观测到的概率一定小于1,将多个小概率连乘在实际应用中是非常不稳定的,因此可以利用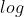 的性质将前式转化为
的性质将前式转化为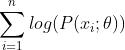 。对于优化问题,常常将求最大值转化为求最小值(因为大部分常用的优化解法默认setup都是最小化问题),因此最大似然估计的问题就变为:
。对于优化问题,常常将求最大值转化为求最小值(因为大部分常用的优化解法默认setup都是最小化问题),因此最大似然估计的问题就变为: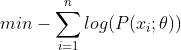
线性回归
对于有监督学习类的问题,因为样本有类别属性和目标值,因此对于观察到样本概率的表达也应转变为条件概率。且根据线性回归模型定义: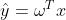 ,因此最大似然估计在这里要通过改变
,因此最大似然估计在这里要通过改变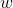 来最大化观测到样本的概率。于是对于线性回归问题,最大似然估计表达为:
来最大化观测到样本的概率。于是对于线性回归问题,最大似然估计表达为: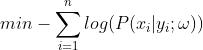 。线性回归有一个重要假设就是误差项符合正态分布,即误差项的概率密度函数可表示为:
。线性回归有一个重要假设就是误差项符合正态分布,即误差项的概率密度函数可表示为: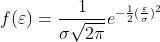 ,其中误差项
,其中误差项 可表示为
可表示为 。将概率密度函数带入最大似然估计得到:
。将概率密度函数带入最大似然估计得到: 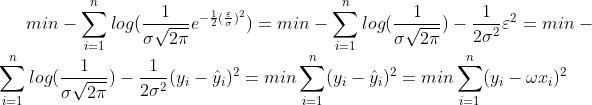
看到这里应该大家都很熟悉了,在将最大似然估计层层化简后其优化问题的目标函数和最小二乘法如出一辙。接下来的问题就好办了,目标函数为标准的二次函数,性质为凸函数,使用梯度下降和牛顿法都可求解。
逻辑回归
逻辑回归和线性回归有相似之处,但在模型的输出上却大为不同。为了使逻辑回归的输出压缩到[0,1]的范围之内,逻辑回归使用的是广义线性模型,其中联系函数为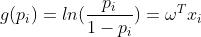 。由此推到我们熟悉的logistic function的过程如下:
。由此推到我们熟悉的logistic function的过程如下:
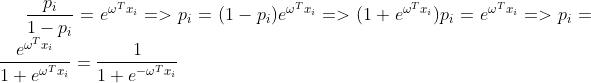
其中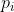 表示样本目标值为1的概率而
表示样本目标值为1的概率而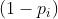 表示样本目标值为0的概率,即
表示样本目标值为0的概率,即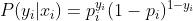 ,将其带入最大似然估计可得:
,将其带入最大似然估计可得: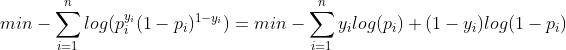
这就是我们熟悉的cross-entropy loss了。
此函数依然是一个有完美性质的凸函数,可以使用梯度下降和牛顿法求解。
求解梯度过程:设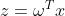 ,
,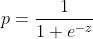 ,目标函数为
,目标函数为
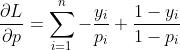
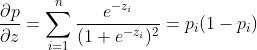
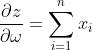
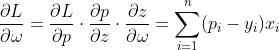
写在最后的话
文中若有错误还请指正
转载请注明出处
以上是关于怎么从通俗意义上理解逻辑回归的损失函数的主要内容,如果未能解决你的问题,请参考以下文章