CTF学习之0基础入门笔记
Posted Autumn_Hibiscus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CTF学习之0基础入门笔记相关的知识,希望对你有一定的参考价值。
ctf基本入门,从基本知识开始,本文是作者的学习计划和笔记,欢迎参考和交流
文章目录
前言
随着一系列新型的互联网产品的产生,基于Web环境的互联网应用越来越广泛
Web业务的迅速发展也引起黑客们的强烈关注,接踵而至的就是Web安全威胁的凸显。
黑客利用网站操作系统的漏洞和Web服务程序的SQL注入漏洞等得到Web服务器的控制权限,轻则篡改网页内容,重则窃取重要内部数据,更为严重的则是在网页中植入恶意代码,使得网站访问者受到侵害。这也使得越来越多的用户关注应用层的安全问题,对Web应用安全的关注度也逐渐升温。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Web应用程序的发展历程
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
1、静态内容阶段
在这个时候,Web 由大量的静态 html 文档组成,其中大多是一些学术论文。Web 服务器可以被看作是支持超文本的共享文件服务器
2、CGI 程序阶段
Web 服务器增加了一些编程 API。通过这些 API 编写的应用程序,可以向客户端提供一些动态变化的内容。这里相当于客户不仅可以看,还可以调用其中的程序。
也就是放置在服务器上的一段可执行程序。作为HTTP服务器的时候,客户端可以通过GET或者POST请求来调用这可执行程序。
3、脚本语言阶段
服务器端出现了 ASP、php、JSP、ColdFusion 等支持 session 的脚本语言技术,浏览器端出现了 Java Applet、javascript 等技术。使用这些技术,可以提供更加丰富的动态内容。
允许客户端的JavaScript脚本为局部页面提供请求服务,然后可以在无需回到服务器情况下动态刷新部分页面。
4、瘦客户端应用阶段
在服务器端出现了独立于 Web 服务器的应用服务器。
同时出现了 Web MVC 开发模式,各种 Web MVC 开发框架逐渐流行,并且占据了统治地位。基于这些框架开发的 Web 应用,通常都是瘦客户端应用,因为它们是在服务器端生成全部的动态内容。
5、RIA 应用阶段
出现了多种 RIA(Rich Internet Application)技术(丰富互联网程序,具有高度互动性、丰富用户体验以及功能强大的客户端),大幅改善了 Web 应用的用户体验。
其具有丰富的数据模型,丰富的界面元素。
应用最为广泛的 RIA 技术是 DHTML+Ajax。Ajax 技术支持在不刷新页面的情况下动态更新页面中的局部内容。同时诞生了大量的 Web 前端 DHTML 开发库。
6、移动 Web 应用阶段
在这个阶段,出现了大量面向移动设备的 Web 应用开发技术。除了 android、ios、Windows Phone 等操作系统平台原生的开发技术之外,基于 HTML5 的开发技术也变得非常流行。
从以上可以看出,Web 从最初其设计者所构思的主要支持静态文档的阶段,逐渐变得越来越动态化。Web 应用的交互模式,变得越来越复杂,web开发是大势所趋。
二、常见安全隐患说明
首先我们都知道,黑客分为两种,一种是社工类黑客,一种是技术类黑客,其中社工类黑客最常见也最防不胜防。
并且,大多数web应用程序并不安全,还是要特别注意以下漏洞,这也是我们需要特别防范的,这里只是进行一个介绍,后期会针对这些漏洞进行讲解。
1、不完善的身份验证信息
这类漏洞主要包括应用程序登录机制中的各种缺陷,可能会使攻击者破解保密性不强的密码、发动蛮力攻击或者完美避开登录。
2、不完善的访问控制措施
这类漏洞涉及的情况包括:应用程序无法为数据和功能提供全面保护,攻击者可以查看其他用户保存在服务器里面的敏感信息,或者执行一些特权操作。
3、SQL注入
通过这个漏洞,攻击者提交专门设计的输入,干扰应用程序与后端数据库的交互活动。攻击者能够从应用程序里提取任何数据、破坏其逻辑结构,或者在数据库服务器上执行命令。
4、跨站点脚本
攻击者可以利用这一漏洞攻击应用程序的其他用户、访问其信息、代表他们执行未授权的工作,或者向其发动攻击。
5、信息泄露
攻击者利用应用程序泄露的敏感信息,通过有缺陷的错误处理或者其他攻击行为攻击应用程序。
比如可以通过访问的网页,爬取网站信息。
6、跨站点请求伪造
攻击者可以利用这类漏洞,诱使用户无意中是用自己的用户权限地应用程序执行操作。恶意Web站点可以利用该漏洞,通过受害用户与应用程序进行交互,执行用户并不打算执行的操作。
web 服务器(特卡--CPU资源被占用)-->用户量访问量大-->web服务代码中有病毒代码信息(可能外部植入)
7、弱口令
攻击者可以利用弱口令(系统登录口令的设置强度不高,容易被攻击者猜到或破解)漏洞,获取合法用户的权限,从而能够查看用户的敏感信息,还有可以进行钓鱼等操作,甚至可以破解管理员的密码从而能够拿到管理员的权限,通过查找网站是否还有其它危害较大的漏洞,进而控制整个站点。
8、任意文件上传
攻击者的主要是把一些恶意代码上传到要攻击的系统中。然后,攻击者只需要找到一种方法来让代码被执行即可完成攻击,极大可能造成主机系统失陷、文件系统或数据库过载、被作为攻击后端系统的跳板机等。
9、远程代码执行漏洞
攻击者直接向后台服务器远程注入操作系统命令或代码,从而控制后台系统,盗取各种信息。
其实,我们的网页出现问题,被攻击,很大一部分的原因是:
1、不成熟的安全意识
2、独立开发(应用程序和第三方组件自定义或拼接在一起,很可能包含独有的缺陷)
欺骗性的简化(编写功能性代码与编写安全代码存在巨大的差异
4、逐渐发展起来的威胁(随着网络安全的发展,黑客攻击也在提升)
5、资源与时间的限制(把功能放在主要位置忽视掉不明显的安全问题)
6、技术上强其所难(开发人员沿用之前的技术来满足新的需求,没有什么大的变化)
7、对功能的需求不断增强(添加一些不在能力范围之内或者不必要的功能,实际上增大了该站点的受攻击可能性)
……
总结
最后,这里提供各种提交漏洞,学习的网站:
1、腾讯:http://security.tencent.com
2、网易: http://aq.163.com
3、京东: http://security.jd.com
4、百度: http://sec.baidu.com
5、Sebug: http://sebug.net/
6、补天:https://www.butian.com
漏洞银行:https://www.bugbank.cn
7、freebuf:http://www.freebuf.com/
8、wooyun 镜像: http://www.anquan.us/
9、全球黑客攻防学习站点: https://link-base.org/
10、安全圈:https://www.anquanquan.info/
小伙伴们可以学习,看一看。
Netty笔记2-Netty学习之NIO基础
Netty学习之NIO基础
本博客是根据黑马程序员Netty实战学习时所做的笔记
可先参考博客 [Java NIO](https://nyimac.gitee.io/2020/11/30/Java NIO/)
non-blocking io:非阻塞IO
一、三大组件简介
Channel与Buffer
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。
通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理
简而言之,通道负责传输,缓冲区负责存储
常见的Channel有以下四种,其中FileChannel主要用于文件传输,其余三种用于网络通信
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
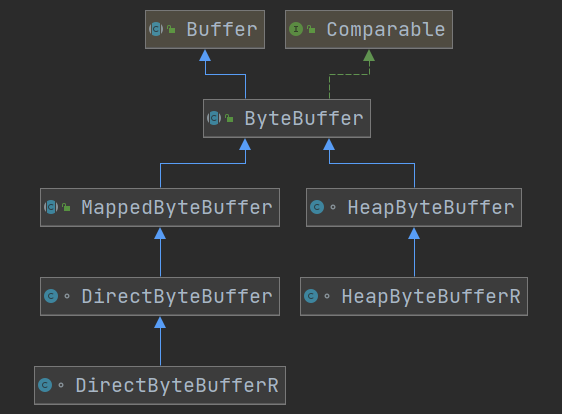
Buffer有以下几种,其中使用较多的是ByteBuffer
ByteBuffer- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
1.1 Selector
在使用Selector之前,处理socket连接还有以下两种方法
多线程版设计
为每个连接分别开辟一个线程,分别去处理对应的socket连接
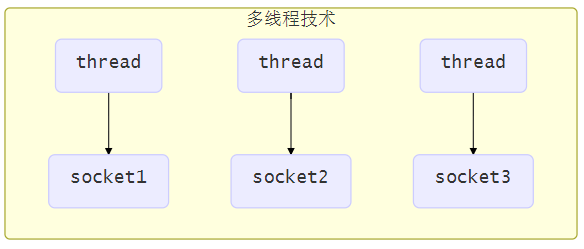
⚠️这种方法存在以下几个问题【餐馆,服务员&客人】
- 内存占用高
- 每个线程都需要占用一定的内存,当连接较多时,会开辟大量线程,导致占用大量内存
- 线程上下文切换成本高
- 只适合连接数少的场景
- 连接数过多,会导致创建很多线程,从而出现问题
线程池版设计
使用线程池,让线程池中的线程去处理连接
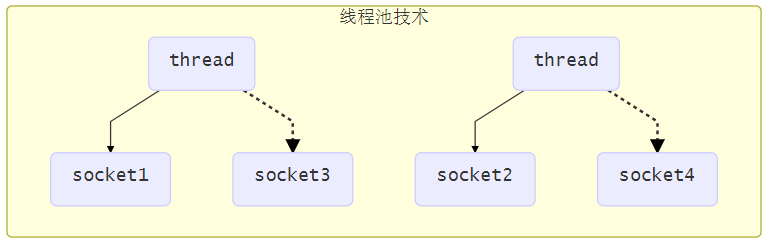
⚠️线程池版缺点
-
阻塞模式下,线程仅能处理一个连接
- 线程池中的线程获取任务(task)后,只有当其执行完任务之后(断开连接后),才会去获取并执行下一个任务
- 若socke连接一直未断开,则其对应的线程无法处理其他socke连接
-
仅适合短连接场景
- 短连接即建立连接发送请求并响应后就立即断开,使得线程池中的线程可以快速处理其他连接
Selector版设计
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务。适合连接数多,但流量较少的场景
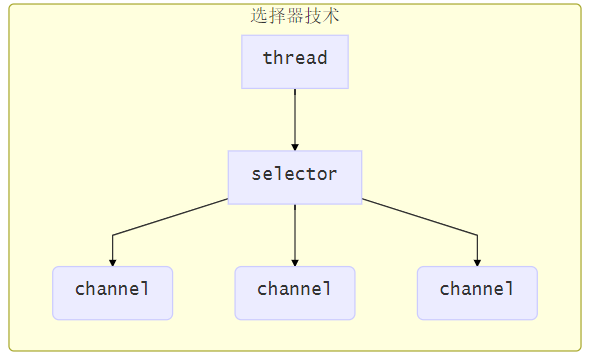
若事件未就绪,调用 selector 的 select() 方法会阻塞线程,直到 channel 发生了就绪事件。这些事件就绪后,select 方法就会返回这些事件交给 thread 来处理
1.2 ByteBuffer
使用案例
使用方式
-
向 buffer 写入数据,例如调用 channel.read(buffer)
-
调用 flip() 切换至
读模式- flip会使得buffer中的limit变为position,position变为0
-
从 buffer 读取数据,例如调用 buffer.get()
-
调用 clear() 或者compact()切换至
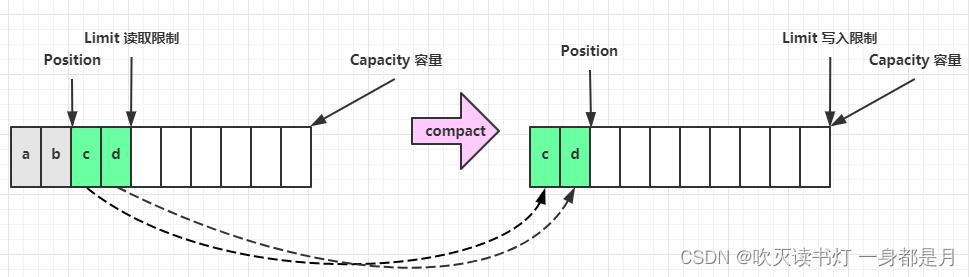
写模式- 调用clear()方法时position=0,limit变为capacity
- 调用compact()方法时,会将缓冲区中的未读数据压缩到缓冲区前面
-
重复以上步骤
使用ByteBuffer读取文件中的内容
public class TestByteBuffer
public static void main(String[] args)
// 获得FileChannel
try (FileChannel channel = new FileInputStream("stu.txt").getChannel())
// 获得缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
//从channel读取数据,向buffer写
int hasNext = 0;
StringBuilder builder = new StringBuilder();
while((hasNext = channel.read(buffer)) > 0) //【“多次”从缓冲区读取】
// 切换【读】模式 limit=position, position=0
buffer.flip();
// 当buffer中还有数据时,获取其中的数据
while(buffer.hasRemaining())
builder.append((char)buffer.get());
// 切换【写】模式 position=0, limit=capacity
buffer.clear();
System.out.println(builder.toString());
catch (IOException e)
打印结果
0123456789abcdef
核心属性
字节缓冲区的父类Buffer中有几个核心属性,如下
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity; //读写指针
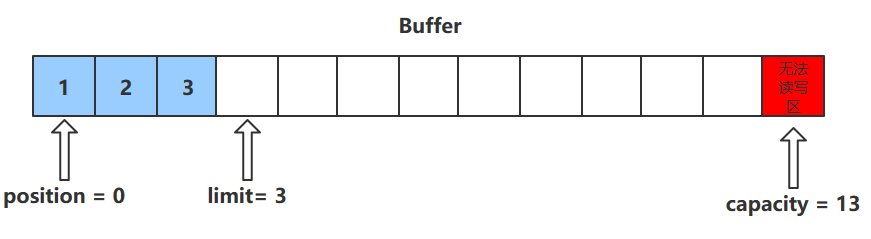
- capacity:缓冲区的容量。通过构造函数赋予,一旦设置,无法更改
- limit:缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量
- position:下一个读写位置的索引(类似PC)。缓冲区的位置不能为负,并且不能大于limit
- mark:记录当前position的值。position被改变后,可以通过调用reset() 方法恢复到mark的位置。
一开始
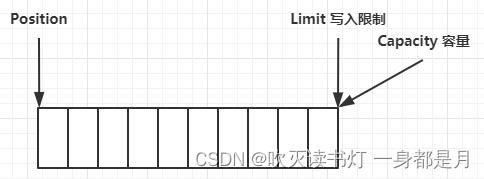
写模式下,position 是写入位置,limit 等于容量,下图表示写入了 4 个字节后的状态
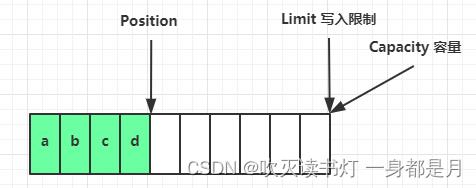
flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
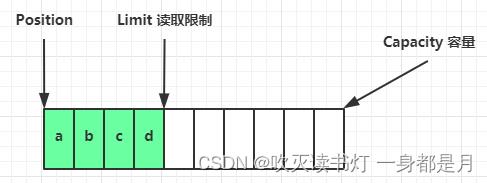
读取 4 个字节后,状态
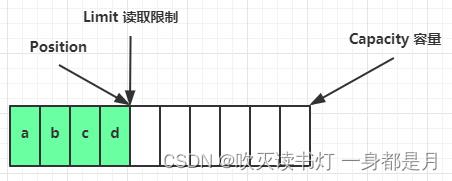
clear 动作发生后,状态
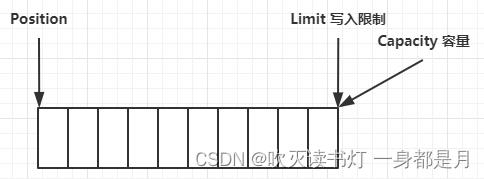
compact 方法,是把未读完的部分向前压缩,然后切换至写模式。d后面可以写
核心方法
rewind()方法
- 该方法只能在读模式下使用
- rewind()方法后,会恢复position、limit和capacity的值,变为进行get()前的值
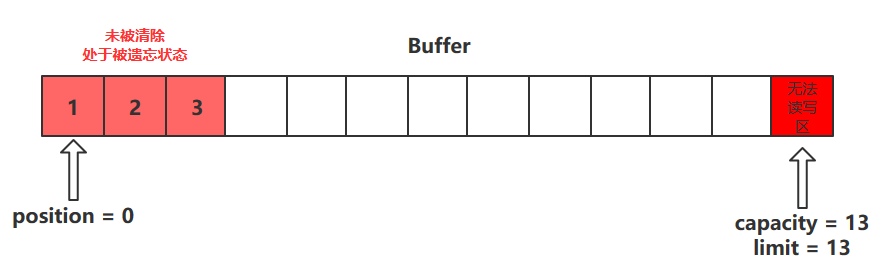
clean()方法
- clean()方法会将缓冲区中的各个属性恢复为最初的状态,position = 0, capacity = limit
- 此时缓冲区的数据依然存在,处于“被遗忘”状态,下次进行写操作时会覆盖这些数据
mark()和reset()方法
mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置
注意:rewind 和 flip 都会清除 mark 位置
compact()方法
- compact会把未读完的数据向前压缩,然后切换到写模式
- 数据前移后,原位置的值并未清零,写时会覆盖之前的值
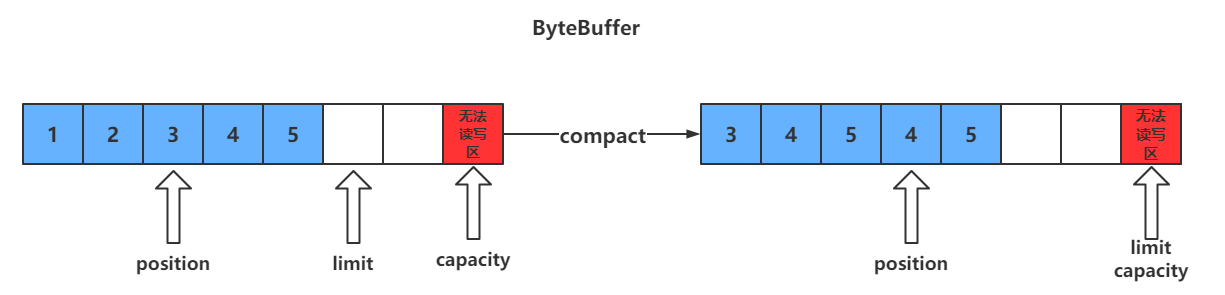
clear() VS compact()
clear只是对position、limit、mark进行重置,而compact在对position进行设置,以及limit、mark进行重置的同时,还涉及到数据在内存中拷贝(会调用array)。**所以compact比clear更耗性能。**但compact能保存你未读取的数据,将新数据追加到为读取的数据之后;而clear则不行,若你调用了clear,则未读取的数据就无法再读取到了
所以需要根据情况来判断使用哪种方法进行模式切换
方法调用及演示
调用ByteBuffer的方法
public class TestByteBuffer
public static void main(String[] args)
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向buffer中写入1个字节的数据
buffer.put((byte)97);
// 使用工具类,查看buffer状态
ByteBufferUtil.debugAll(buffer);
// 向buffer中写入4个字节的数据
buffer.put(new byte[]98, 99, 100, 101);
ByteBufferUtil.debugAll(buffer);
// 获取数据
buffer.flip();
ByteBufferUtil.debugAll(buffer);
System.out.println(buffer.get());
System.out.println(buffer.get());
ByteBufferUtil.debugAll(buffer);
// 使用compact切换模式
buffer.compact();
ByteBufferUtil.debugAll(buffer);
// 再次写入
buffer.put((byte)102);
buffer.put((byte)103);
ByteBufferUtil.debugAll(buffer);
运行结果
// 向缓冲区写入了一个字节的数据,此时postition为1
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 00 00 00 00 00 00 00 00 00 |a......... |
+--------+-------------------------------------------------+----------------+
// 向缓冲区写入四个字节的数据,此时position为5
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用flip切换模式,此时position为0,表示从第0个数据开始读取
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 读取两个字节的数据
97
98
// position变为2
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用compact切换模式,此时position及其后面的数据被压缩到ByteBuffer前面去了
// 此时position为3,会覆盖之前的数据
+--------+-------------------- all ------------------------+----------------+
position: [3], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 63 64 65 64 65 00 00 00 00 00 |cdede..... |
+--------+-------------------------------------------------+----------------+
// 再次写入两个字节的数据,之前的 0x64 0x65 被覆盖
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 以上是关于CTF学习之0基础入门笔记的主要内容,如果未能解决你的问题,请参考以下文章