Mysql优化聚簇索引与非聚簇索引概念
Posted Qiao_Zhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql优化聚簇索引与非聚簇索引概念相关的知识,希望对你有一定的参考价值。
必须为主键字段创建一个索引,这个索引就是所谓的"主索引"。主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是PRIMARY而不是UNIQUE。
首先明白两句话:
innodb的次索引指向对主键的引用 (聚簇索引)
myisam的次索引和主索引 都指向物理行 (非聚簇索引)
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引(理由:数据一旦存储,顺序只能有一种)。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
INNODB和MYISAM的主键索引与二级索引的对比:
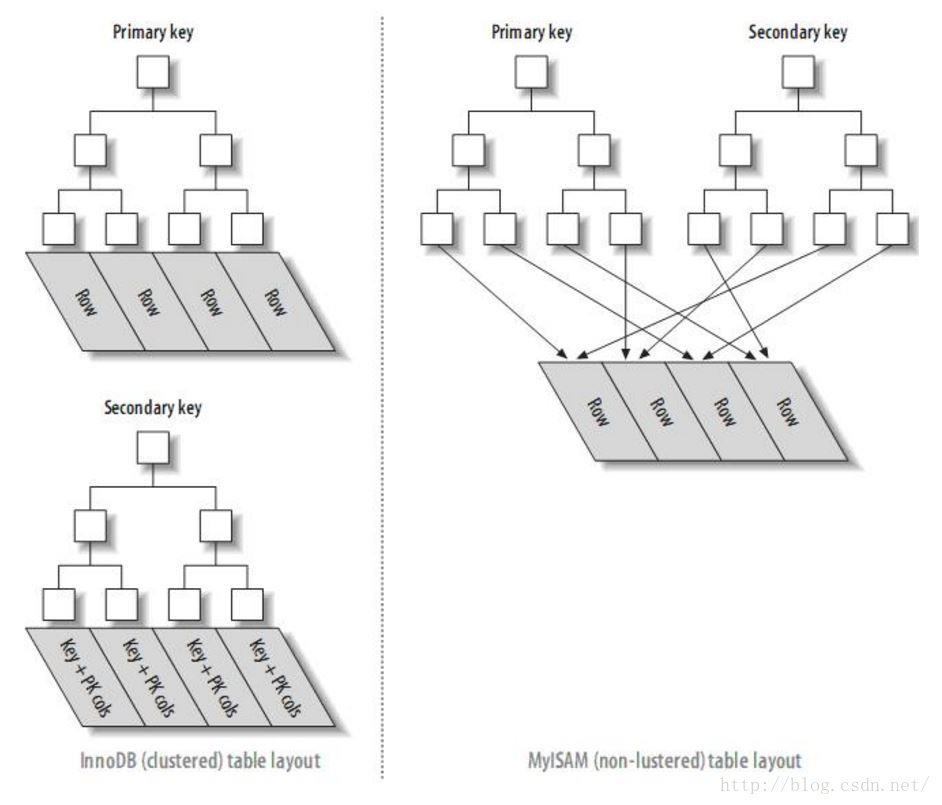
也就是InnoDB的主索引的节点与数据放在一起,次索引的节点存放的是主键的位置。
myisam的主索引和次索引都指向该数据在磁盘的位置。
InnoDB的的二级索引的叶子节点存放的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。
而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键
也可以用下面这幅图理解:
首先是myisam的索引主次索引都指向物理行:
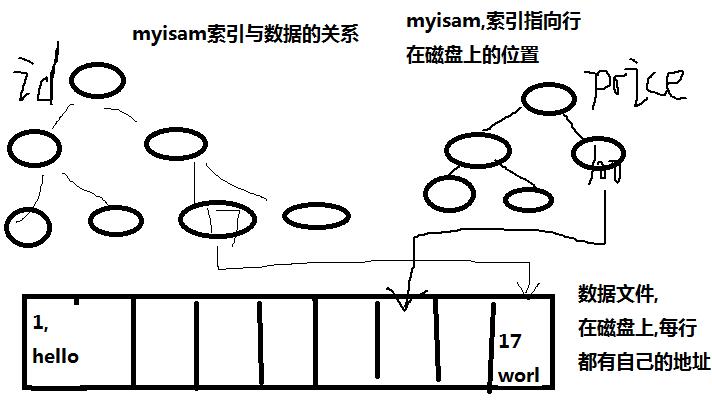
InnoDB的主索引叶子节点是主键和数据,次索引指向主键

innodb的主索引文件上 直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中, 主索引和次索引,都指向物理行(磁盘位置).
注意: innodb来说,
1: 主键索引 既存储索引值,又在叶子中存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
1、聚簇索引
a) 一个索引项直接对应实际数据记录的存储页,可谓“直达”
b) 主键缺省使用它
c) 索引项的排序和数据行的存储排序完全一致,利用这一点,想修改数据的存储顺序,可以通过改变主键的方法(撤销原有主键,另找也能满足主键要求的一个字段或一组字段,重建主键)
d) 一个表只能有一个聚簇索引(理由:数据一旦存储,顺序只能有一种)
2、非聚簇索引
a) 不能“直达”,可能链式地访问多级页表后,才能定位到数据页
b) 一个表可以有多个非聚簇索引
-------------------------------------聚簇索引优势劣势;-----------------------------------
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂.
聚簇索引的页分裂过程
理解: 原来索引如下
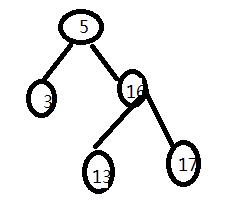
此时插入一个8,需要将13,16,17移动之后插入8

对于myisam引擎:只需要存储数据之后移动索引节点,
对于innoDb的聚簇索引:插入数据之后需要移动13,16,17.但是因为这三个节点上面有数据,也就造成了额外的开销。相当于三个节点搬家的同时带着数据搬家。
也可以用下图理解:

总结:
1: innodb的buffer_page 很强大.
2: 聚簇索引的主键值,应尽量是连续增长的值,而不是要是随机值,
(不要用随机字符串或UUID)
否则会造成大量的页分裂与页移动.
为了看出效果可以用Java向数据库中按顺序插入1000条数据与乱序插入一千条数据。看执行的时间即可看出效果。
如下图:Innodb_pages_written代表已经写入的页数,可以按顺序插入1000条数据与乱序插入一千条数据观察增长的变化量。
mysql> show status like \'%page_%\'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | Innodb_buffer_pool_pages_data | 256 | | Innodb_buffer_pool_pages_dirty | 0 | | Innodb_buffer_pool_pages_flushed | 749 | | Innodb_buffer_pool_pages_free | 243 | | Innodb_buffer_pool_pages_misc | 13 | | Innodb_buffer_pool_pages_total | 512 | | Innodb_dblwr_pages_written | 628 | | Innodb_page_size | 16384 | | Innodb_pages_created | 67 | | Innodb_pages_read | 736 | | Innodb_pages_written | 749 | | Tc_log_max_pages_used | 0 | | Tc_log_page_size | 0 | | Tc_log_page_waits | 0 | +----------------------------------+-------+ 14 rows in set (0.00 sec)
聚簇索引与非聚簇索引的区别参考:http://www.cnblogs.com/qlqwjy/p/7770580.html
以上是关于Mysql优化聚簇索引与非聚簇索引概念的主要内容,如果未能解决你的问题,请参考以下文章