开源词袋模型DBow3原理&源码ORB特征的保存和读取
Posted tszs_song
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源词袋模型DBow3原理&源码ORB特征的保存和读取相关的知识,希望对你有一定的参考价值。
util里提供了create_voc_step0用于批量生成features并保存,create_voc_step1读入features再生成聚类中心,比较适合大量语料库聚类中心的生成。
提取一张图的特征如下:
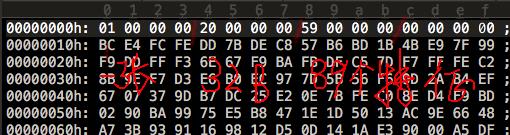
第一行是文件头,分别用32bit表示特征来自几张图(1)、特征描述子长度(128bit,=32B), 特征长度(89), 特征类型(cv8u)
./utils/create_voc_step0 orb fea0 zs00.jpg Extracting features... reading image: zs00.jpg extracting features [ INFO:0] Initialize OpenCL runtime... done detecting features f.size = 1 f.cols = 32 f.rows = 89 f.type = 0
那么一个特征就是89行*32列的cv::Mat, 这样的特征在调voc.transform生成词向量之前需要先拉长成(32列*1行)的89维vector,像这样:
std::vector<cv::Mat> vf(features.rows); //改成这种格式才能用voc.transform
打印结果:
feature size: rows = 89 ; cols = 32 the 0th of vf: [32 x 1] the 1th of vf: [32 x 1] the 2th of vf: [32 x 1] the 3th of vf: [32 x 1] the 4th of vf: [32 x 1] the 5th of vf: [32 x 1] the 6th of vf: [32 x 1] the 7th of vf: [32 x 1] the 8th of vf: [32 x 1]
queryL1:
对每个entryId, 从word的权值和entryId权值中找里原点最近的,累加程序里的实现是
累加|qvalue-dvalue|-|qvalue|-|dvalue|,最后加负号/2即可
以上是关于开源词袋模型DBow3原理&源码ORB特征的保存和读取的主要内容,如果未能解决你的问题,请参考以下文章