linux系统elasticsearch的详细安装配置教程(超级详细)
Posted lunaw-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux系统elasticsearch的详细安装配置教程(超级详细)相关的知识,希望对你有一定的参考价值。
1.下载安装:
使用xftp将es的安装包上传到linux的服务器:
查看压缩包是否存在:

解压到指定目录:

2.更改文件夹所属者:
因为我之前设置过更改文件夹的所属者,没有改的可以改一下:
chown -R clay:clay /opt/module
由下图可见,我们的文件夹权限赋给了clay

查看文件目录结构:

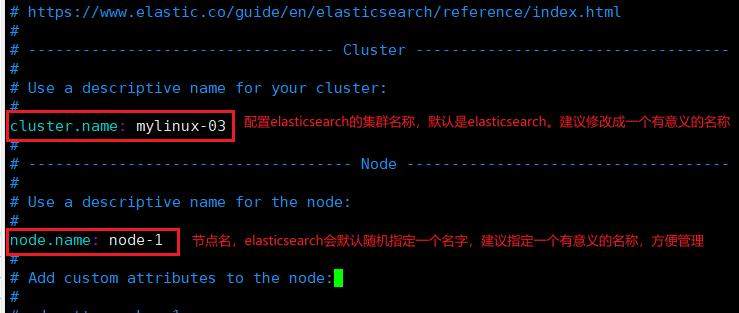
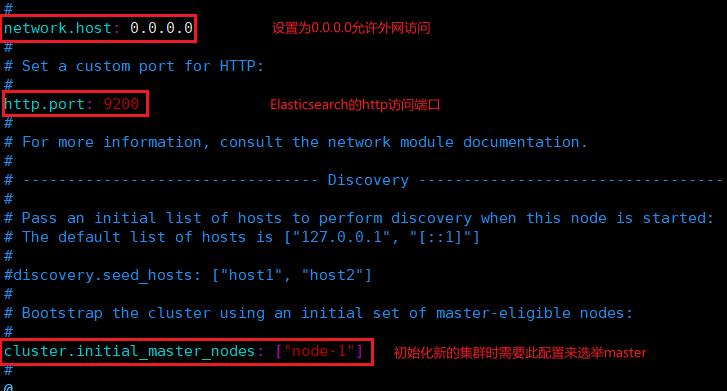
3.修改elasticsearch.yml文件,修改一些核心配置:

4.解决es与jdk依赖强的问题:
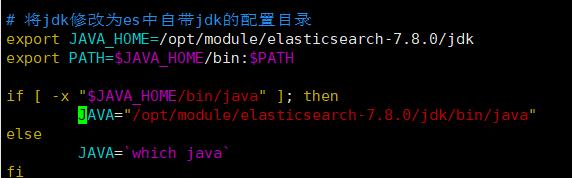
此时:如果启动es,会报错,因为ES文件夹里自己携带了 JDK ,但是如果我们的 Linux 下安装了 JDK ,ES 就不会用自己自带的 JDK ,反而会使用我们 Linux 安装的 JDK ,这个时候如果两个jdk的版本不一致,就会造成jdk不能正常运行,报错

修改bin/elastisearch文件:

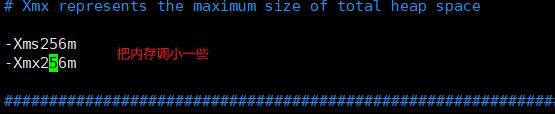
5.解决内存不足问题
由于elasticsearch 默认分配 jvm空间大小为2g,如果服务器内存不大就会报错,所以我们需要修改 jvm空间,如果Linux服务器本来配置就很高,可以不用修改。

解决:修改配置文件:

6.解决vm.max_map_count [65530] is too low问题


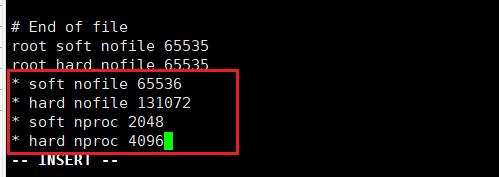
7. 可能遇到的max file descriptors [4096]问题
sudo vi /etc/security/limits.conf
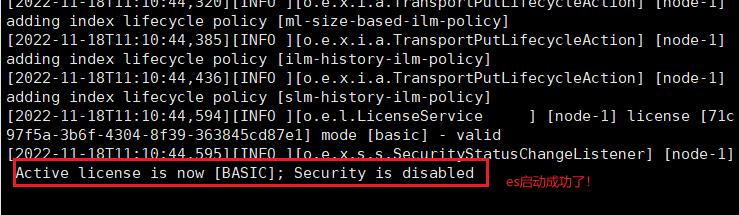
8.启动服务:(后面加上-d表示后台启动)

9.关闭服务:
查看es进程:

杀死线程:

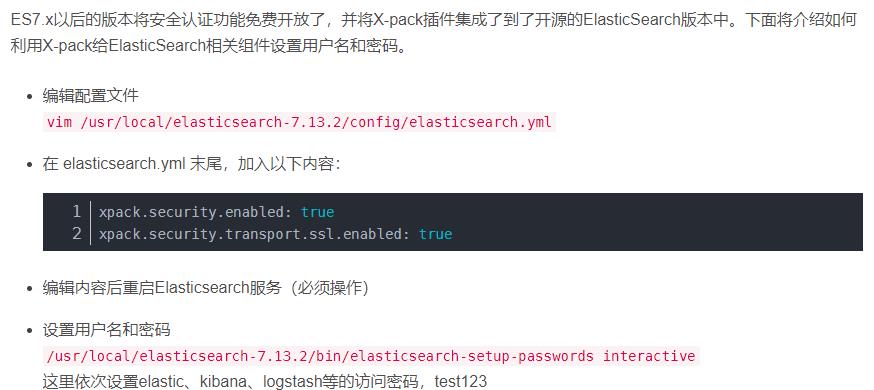
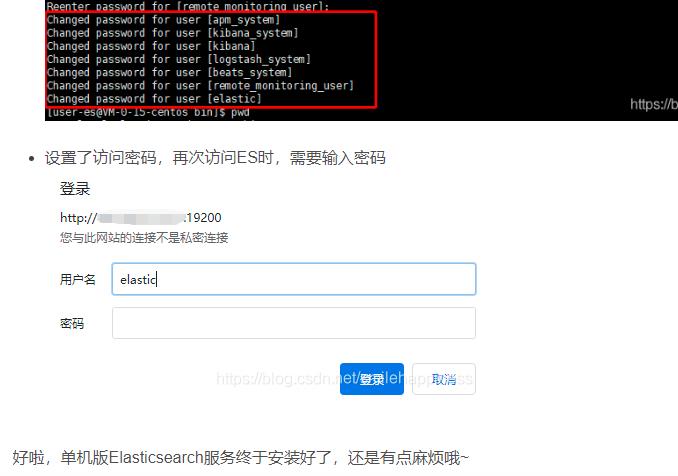
10.为Elasticsearch设置登录密码(看自己需求)
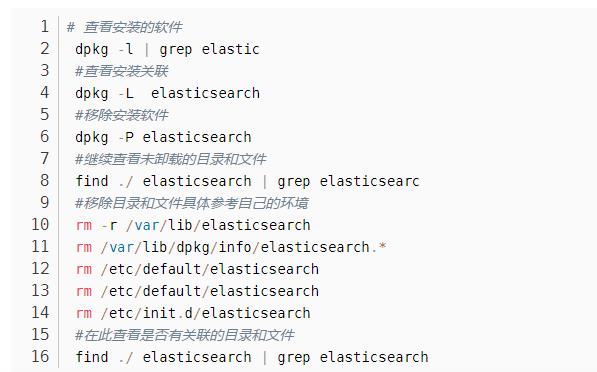
11.卸载
ELK实战,Linux版docker安装ElasticSearchES-headLogstashKiabana入门,无坑详细图解
项目需要,记录一次ELK日志分析系统无坑初始安装过程,并给大家整理出了操作elasticsearch的主要命令,elasticsearch!伙伴们都懂得哦!别的不多说,看过内容概览,直接开整!!!

一、系统调优
1-1 修改/etc/security/limits.conf
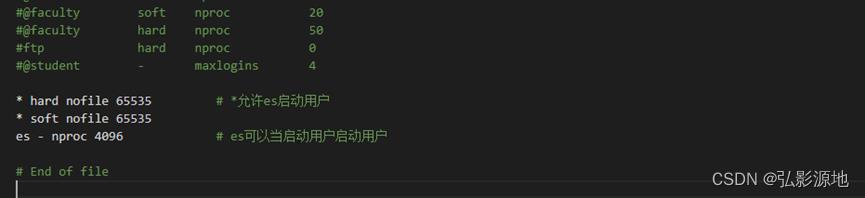
limits.conf文件限制着用户可以使用的最大文件数,最大线程,最大内存等资源使用量,在最后追加内容:
* hard nofile 65535 # *允许es启动用户
* soft nofile 65535
es - nproc 4096 # es可以当启动用户启动用户
说明:soft是一个警告值,而hard则是一个真正意义的阀值,超过就会报错
1-2 修改/etc/sysctl.conf

追加内容:
vm.max_map_count=262144

1-3 执行下面命令,修改内核参数马上生效,
/sbin/sysctl -p
对应的/proc/sys/vm/max_map_count会自动修改数值。
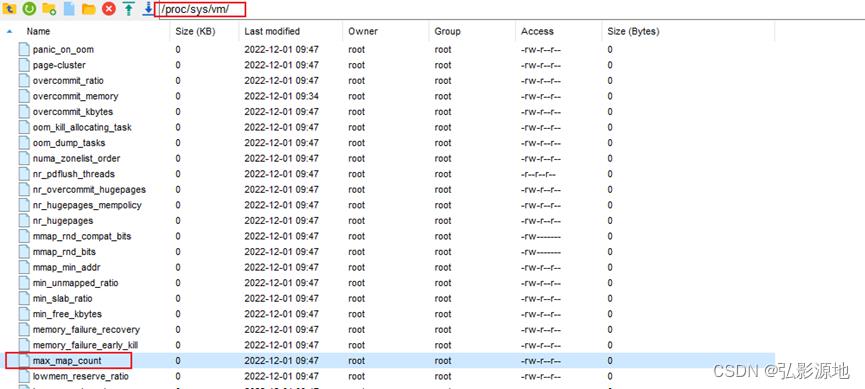
二、Elasticsearch安装
2-1 初次创建elasticsearch容器
2-1-1 下载镜像
docker pull elasticsearch:7.3.0

2-1-2 创建elasticsearch容器,映射9200,9300端口,指定环境变量discovery.type,这个很重要,否则无法启动
docker run -di --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" 镜像名字或ID

2-1-3 防火墙放行9200端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload
firewall-cmd --list-ports

2-1-4 访问IP地址:9200,测试是否启动成功

2-2 使9300端口有效
2-2-1 进入容器:
docker exec -it 容器名称或者id /bin/bash
此时,我们看到elasticsearch所在的目录为/usr/share/elasticsearch
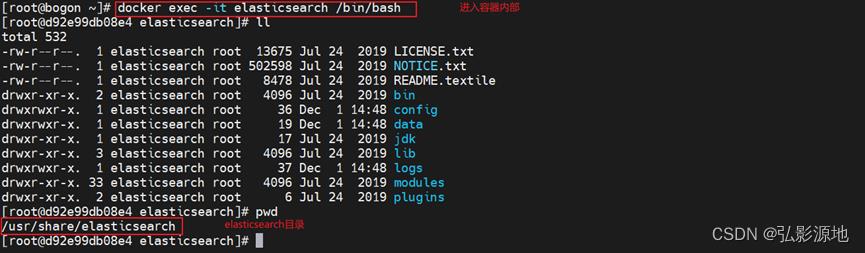
2-2-2 进入config看到了配置文件elasticsearch.yml

此处有多种方式修改elasticsearch.yml配置文件,推荐拷贝出来到宿主机上,然后进行目录挂载
2-2-3 拷贝容器内elasticsearch.yml文件到宿主机, 前提条件是:
###容器必须是运行中
###退出容器内部
exit

###宿主机的目录已经创建好

执行拷贝
docker cp 必须是容器名称:/usr/share/elasticsearch/config/elasticsearch.yml /usr/local/elasticsearch/config/elasticsearch.yml
注意:前面的路径是容器内的,后面的路径是宿主机的


2-2-4 停止和删除现在运行中的elasticsearch容器

2-2-5 修改/usr/local/elasticsearch/elasticsearch.yml
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"

2-3 二次创建elasticsearch容器
2-3-1 本地创建es挂载目录,并赋予各目录777权限
chmod 777 /usr/local/elasticsearch/plugins
chmod 777 /usr/local/elasticsearch/data
chmod 777 /usr/local/elasticsearch/config

2-3-2 二次创建elasticsearch容器
docker run -di \\
--name elasticsearch \\
-p 9200:9200 \\
-p 9300:9300 \\
-e "discovery.type=single-node" \\
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \\
-v /usr/local/elasticsearch/data:/usr/share/elasticsearch/data \\
-v /usr/local/elasticsearch/plugins:/usr/share/elasticsearch/plugins \\
-v /usr/local/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \\
镜像名字或ID
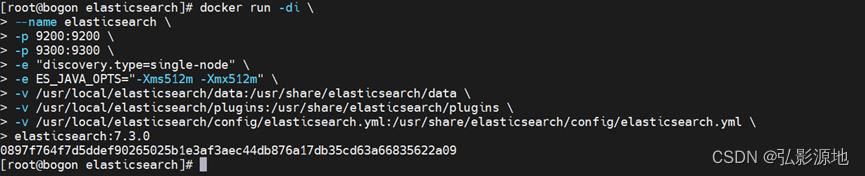
2-3-3 再次访问:IP+9200
2-4 向容器中添加ik分词器
此处要注意版本,要和elasticsearch版本一致,此处为7.3.0
2-4-1 ik分词器下载地址
和本例elasticsearch版本配套,已设置好
百度网盘链接:https://pan.baidu.com/s/1K2mWiiH_JxyXsJVaAoWcvQ
提取码:7zge
2-4-2 将ik文件夹上传至宿主机elasticsearch挂载目录

2-4-3 进入容器查看:
docker exec -it 容器名或者id /bin/bash
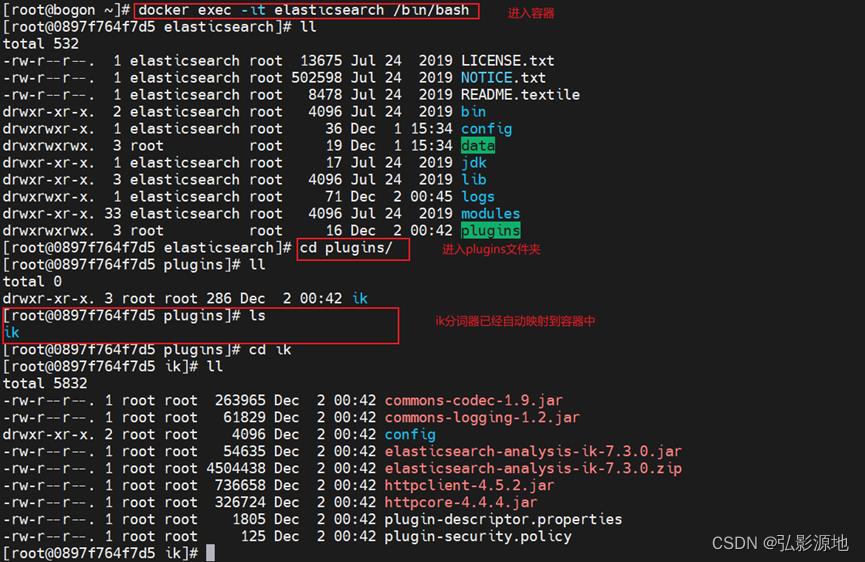
2-4-4 设置自定义词库:此步骤可以根据自己的需要设定词库,如果设置的话在上传ik文件夹之前完成设置
2-4-5 从新启动容器
三、elasticsearch-header安装
3-1 下载镜像
docker pull wallbase/elasticsearch-head:6-alpine

3-2 修改/usr/local/elasticsearch/elasticsearch.yml文件,添加跨域支持,本例前面已经添加过,没有添加的可以在此处补上
#开启cors跨域访问支持,默认为false
http.cors.enabled: true
#跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: /.*/
3-3 创建elasticsearch-head容器
docker run -di --name=elasticsearch-head -p 9100:9100 容器名称或ID
3-4 访问IP+9100

四、Logstash安装
4-1 拉取镜像
docker pull logstash:7.3.0
4-2 创建容器并启动logstash
docker run -di -p 5044:5044 -p 9600:9600 --name logstash 容器名称或ID

4-3 拷贝容器内的config文件夹到到宿主机,以便将来在宿主机中直接修改logstash配置
语法:docker cp 容器名称或ID:容器内路径 宿主机路径
docker cp logstash:/usr/share/logstash/config/ /usr/local/logstash/


本例侧重先把logstash部署起来,故先只修改一个配置文件logstash.yml,其它配置文件的修改,在以后的logstash具体配置时详述
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://自己的elasticsearch的ip:9200" ]
4-4 删除容器

4-5 再次创建带宿主机配置文件的容器
docker run \\
-di \\
--name logstash \\
-p 5044:5044 \\
-p 9600:9600 \\
-v /usr/local/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \\
-v /usr/local/logstash/config/jvm.options:/usr/share/logstash/config/jvm.options \\
-v /usr/local/logstash/config/logstash-sample.conf:/usr/share/logstash/config/logstash-sample.conf \\
-v /usr/local/logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml \\
容器名称或id
4-6 查看logstash启动成功信息
docker logs -f logstash

五、kibana安装
5-1 拉取镜像
docker pull kibana:7.3.0

5-2 创建容器
docker run -di --name kibana -e ELASTICSEARCH_URL=http://192.168.0.142:9200 -p 5601:5601 kibana:7.3.0
本例没有进行配置文件挂载,采取的创建容器添加环境变量-e的方式直接指定elasticsearch的ip

5-3 修改配置文件
进入容器config目录下进行kibana.yml文件修改,把elasticsearch的地址修改成部署的elasticsearch地址
docker exec -it --user root kibana bash
vi kibana.yml
5-4 退出并重启kibana容器
5-5 访问地址
http://192.168.0.142:5601/
至此,完成elasticsearch、logstash、kibana基础安装,后续将会对ELK进行深入配置。
六、操作elasticsearch主要命令
6-1 操作-索引及映射
| 注释 | # | |
| 创建索引 | PUT /索引名称 | 空索引,没有设置和映射 |
| PUT /索引名称 "settings": 设置内容 , "mappings": "properties": 字段设定
| 不推荐:带设置和映射的索引 | |
| PUT /索引名称 "settings": 设置内容 , "mappings": "properties": "字段名": "type": "数据类型", "analyzer": "分词器类型"
| 推荐:设置+映射+字段指定分词器的索引 分词器类型---内置 standard:英文按照单词切分,并小写处理 whitespace:按照空格切分,不转小写 keyword:不分词,直接将输入作为分词 分词器类型---插件---ik分词器 ik_smart:粗颗粒度分词 ik_max_word:细颗粒度分词 | |
| 查看索引 | GET /索引名称 | |
| 查看索引映射 | GET /索引名称/_mapping | |
| 查看所有索引 | GET /_cat/indices | ?v:以表格形式查看 |
| 删除索引 | DELETE /索引名称 | DELETE /* 删除所有索引,慎用,会导致kibana不能用,重启后才可用 |
6-2 操作-文档
| 注释 | # | |
| 插入一条文档 | PUT /索引名称/_doc/文档id 数据定义 | 指定id方式 |
| POST /索引名称/_doc/ 数据定义 | 自动生成id方式,数据定义中不要写id字段 | |
| 根据id查看文档 | GET /索引名称/_doc/文档id | |
| 根据id删除文档 | DELETE /索引名称/_doc/文档id | |
| 更新文档 | PUT /索引名称/_doc/文档id 要更新的数据 | 不保留原始数据,先删除原始数据,然后再插入一条新数据 |
| POST /索引名称/_doc/文档id/_update "doc": 要更新的数据
| 保留原始数据进行更新 | |
| 批量操作 | POST /索引名称/_doc/_bulk "index":id的生成方式 定义json格式数据 "index":id的生成方式 定义json格式数据 后面多条批量操作依次类推...... | 批量添加文档数据 |
6-3 操作-分词器
| 查看分词器效果 | POST /_analyze "analyzer": "分词器类型", "text": "测试文字内容" | 分词器类型---内置 standard:英文按照单词切分,并小写处理 whitespace:按照空格切分,不转小写 keyword:不分词,直接将输入作为分词 分词器类型---插件---ik分词器 ik_smart:粗颗粒度分词 ik_max_word:细颗粒度分词 |
6-4 操作-查询
| 注释 | # | |
| 查询所有文档 | GET /索引名称/_search "query": "match_all": | 返回值说明: took:查询时间,单位毫秒 _shards:分片情况 Hits:结果集数组 |
| 关键字查询 | GET /索引名称/_search "query": "term": "字段名称": "value": "关键字"
| 没有使用ik分词器情况下,默认分词的关键字分词说明: 1、text类型:中文单个字进行分词,英文单个单词分词 2、不分词类型:除text类型外的其它类型都不分词,查询的话要把不同类型的关键字都写全才可以 |
| 过滤查询 | GET /索引名称/_search "query": "bool": "must": [
查询方式:全部/关键字查询...等
], "filter": [
过滤方式:单条件/多条件…等
]
| 执行流程: 先过滤之后,在进行查询,适用数据量大的场景下 查询方式: 过滤方式: |
以上是关于linux系统elasticsearch的详细安装配置教程(超级详细)的主要内容,如果未能解决你的问题,请参考以下文章
Linux环境CentOS6.9安装配置Elasticsearch6.2.2最全详细教程
ELK实战,Linux版docker安装ElasticSearchES-headLogstashKiabana入门,无坑详细图解
Linux 安装 Elasticsearch6.4.x 详细步骤以及问题解决方案
Linux ELK日志分析系统 | logstash日志收集 | elasticsearch 搜索引擎 | kibana 可视化平台 | 架构搭建 | 超详细