linux三剑客(grepsedawk)
Posted 換個名字試試
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux三剑客(grepsedawk)相关的知识,希望对你有一定的参考价值。
Linux三剑客
Linux三剑客是指的grep、sed、awk三个命令,grep主打查找功能,sed主要是编辑,awk主要是分割处理。
grep
grep是global regular expressions print的缩写。grep命令能够在一个或者多个文件中搜索某一特定的字符模式,此模式可以是单一的字符、字符串、单词或句子。grep可以在文本中查找指定的字符串,是linux中最常用的文本处理工具之一。正则表达式的通配符如下:
*: 将匹配0个或者多个字符。.:将匹配任何一个字符,且只能是一个字符。[xyz]:匹配方括号中的任意一个字符。[^xyz]:匹配方括号中的任意一个字符。^: 锁定行的开头。$:锁定行的结尾。?:匹配前面的子表达式0次或者1次。+:匹配前面的子表达式1次或者多次。|: 匹配于|符号前或后的正则表达式。n,m:最少匹配n次,最多匹配m次和BRE的区别是不需要加\\。
在基本的正则表达式中,使用通配符原本的意思,需要添加\\作为转义字符。
grep命令用来在每一个文件搜索特定的模式,当使用grep时,包含指定字符模式的每一行内容,都会被打印到屏幕上,但是使用grep命令并不改变文件中的内容。
grep命令格式:grep [选项] 模式 文件名
这里的模式,要么是字符串,要么是正则表达式。常用的选项如下表。
-
-c:仅列出文件中包含模式的行数,即匹配到的总行数。 -
-i:忽略模式中的字母大小写。 -
-l:列出带有匹配行的文件名。 -
-n:在每一行的最前面列出行号。 -
-v:列出没有匹配模式的行。 -
-w:把代表式当做一个完整的单字符来搜寻,忽略哪些部分匹配的行。 -
-color=auto或者-color:表示对匹配到的文本着色显示。 -
-o:只显示符号条件的字符串,但是不整行显示,每个符号条件的字符串单独显示一行。
-
-w:匹配整个单词,如果是字符串中包含这个单词,则不做匹配。
如果是搜索多个文件,grep命令的搜索结果只显示文件中发现匹配模式的文件名,如果搜索单个文件,grep命令的结果将显示每一个包含匹配模式的行。
sed
sed原理
sed是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供一组规则来编辑数据流。sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要么存储在一个命令文本中。
sed是操作、过滤和转换文本内容的强大工具,常用功能增删改查,过滤,取行。
sed命令的格式如下:sed [options] [sed-commands] [input-file]
- options常用的有:
-n---- 抑制默认输出,-e---- 执行多条编辑命令,-i---- 直接在源文件中修改。 - sed-commands:既可以是单个sed命令,也可以是多个sed命令组合。
- input-file:可选项,sed还可以从标准输出如管道获取输入。
sed是从文件或者管道中读取一行,放在模式空间中,进行处理,处理完输出一行,在读取一行,再处理一行。模式空间是sed内部的临时缓存,用于存放读取到的内容。
sed可以对单行或多行进行处理,如果在sed命令前面不指定地址范围,那么默认会匹配所有行。
sed流程
sed的工作流程主要包括读取、执行和显示三个过程。
读取流程:sed从输入流(文件、管道、标准输入)中读取一行内容并存在到临时的缓冲区中(又称为模式空间)。
执行流程:默认情况下,所有的sed命令都在模式空间中顺利地执行,除非指定了行的地址,否则sed命令,将会在所有的行上依次执行。
显示流程:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空,在所有的文件内容都被完成处理之前,上述过程被反复执行,直至内容被处理完。
sed选项
sed命令格式:
sed -e '操作' 文件1 文件2sed -n -e '操作' 文件1 文件2sed -f 脚本文件 文件1 文件2sed -e -i '操作' 文件1 文件2
常用选项:
-e或--expression:表示用指定命令来处理输入的文本文件,只有一个操作命令时可以省略,一般在执行多个操作命令使用。-f或--file:表示用指定脚本文件来处理输入的文本文件。-h或--help:显示帮助。-n或s --quiet:禁止sed编辑器输出,但可以与p命令一起使用完成输出。-i:直接修改文本文件。-r,-E:使用扩展正则表达式-s:将多个文件视为独立文件,而不是单个连续的长文件流。
常用操作:
s:替换指定字符(替换)。d:删除指定的行(删除)。a:在指定的行上一行增加一行指定内容(增加)。i:在指定的上一行插入一行指定内容(插入)。c:将选定行内容替换为指定内容(替换)。y:字符转换,转换之后的字符长度必须相同。p:打印,如果同时指定行,表示打印指定行,如果不指定行,则表示打印所有内容;如果有非打印字符,则以Ascii码输出。通常与_n选项一起使用。=:打印行号。l:答应数据流中的文本和不可打印的ASCII字符。
sed的查找
使用sed命令查看:
方法一:sed ' ' /etc/shadow
root@chengyan-virtual-machine:~# sed ' ' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
daemon:*:17379:0:99999:7:::
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
man:*:17379:0:99999:7:::
lp:*:17379:0:99999:7:::
mail:*:17379:0:99999:7:::
方法二:sed -n 'p ' /etc/shadow
root@chengyan-virtual-machine:~# sed -n 'p ' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
daemon:*:17379:0:99999:7:::
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
man:*:17379:0:99999:7:::
lp:*:17379:0:99999:7:::
mail:*:17379:0:99999:7:::
查看指定行:
root@chengyan-virtual-machine:~# sed -n '3p' /etc/shadow
bin:*:17379:0:99999:7:::
使用正则表达式:匹配root开头的行
root@chengyan-virtual-machine:~# sed -n '/^root/p' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
查看连续的行:查看3-6行的内容
root@chengyan-virtual-machine:~# sed -n '3,6p' /etc/shadow
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
查看文件最后一行内容:
root@chengyan-virtual-machine:~# sed -n '$p' /etc/shadow
sshd:*:18964:0:99999:7:::
sed的删除
删除指定行并不是真正的删除,知识将删除了的结果显示出来,并不是真正的删除了文件中的内容,如果想要真正的删除文件中的内容需要添加选项-i。
删除文本中的空行:sed '/^$/d' test.txt
root@chengyan-virtual-machine:~# cat -n test.txt
1
2 1
3 2
4 3
5 4
6
7 6
8 7
9 8
10 9
11
root@chengyan-virtual-machine:~# sed '/^$/d' test.txt
1
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
删除指定行:
root@chengyan-virtual-machine:~# cat -n test.txt
1
2 1
3 2
4 3
5 4
6
7 6
8 7
9 8
10 9
11
root@chengyan-virtual-machine:~# sed '2d' test.txt
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
sed的替换
命令格式:sed 指定行 's/需要替换的字符串/替换后的字符串/替换标记'或者[address]s/pattern/replacement/flag
flag标记:
-
g:表示要替换所有匹配的行。 -
w:将替换后的结果保存到文档。 -
n:1-512,表示指定要替换的字符串出现第几次时才进行替换。 -
w file:将缓冲区中的内容写到指定的file文件中。 -
&:用正则表达式匹配的内容进行替换。 -
\\n:匹配第n个子串,该子串之前在pattern中用\\(\\)指定。 -
\\:转义。
将文件中的test替换为taget:
root@chengyan-virtual-machine:~# cat test1.txt
This is a test file to test replace sed command.
root@chengyan-virtual-machine:~# sed 's/test/taget/g' test1.txt
This is a taget file to taget replace sed command.
root@chengyan-virtual-machine:~#
sed的增加
在第二行下方增加:
root@chengyan-virtual-machine:~# cat test.txt
1
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~# sed '2a ######' test.txt
1
######
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
awk
awk原理
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据进行分析并产生报告时,显得尤为强大。简单的说就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分在进行各种分析处理。
awk选项
命令格式:awk [选项] '脚本命令' 文件名
常用选项:
-F fs:指定以fs作为输入行的分隔符,awk命令默认分隔符为空格或者制表符。-f file:从脚本文件中读取awk脚本指令,以取代直接在命令行中输入指令。-v var=val:在执行处理过程之前,设置一个变量var,并给其设备的初始值为val。
awk的强大在于脚本命令,有两部分组成,分别是匹配规则和执行命令。
匹配规则执行命令
-
匹配规则用来指定脚本命令可以作用到文本内容中的具体行,可以使用字符串或者正则表达式指定。
-
整个脚本命令是用单引号括起来,而其中的执行命令部分需要用大括号括起来。
root@chengyan-virtual-machine:~# cat test.txt
1
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~# awk '/^$/print "Blank line"' test.txt
Blank line
Blank line
Blank line
root@chengyan-virtual-machine:~#
其中,/^$/是一个正则表达式,功能是匹配文本中的空白行,同时可以看到,执行命令使用的是print命令,此命令的功能是将指定的文本进行输出。
awk的主要特性之一就是处理文本文件中数据的能力,它会自动给一行中的每个数据元素分配一个变量。默认情况下,awk会将如下变量分配给它在文本行中发现的数据字段。
- $0代表整个文本行。
- $1代表文本行中的第一个数据字段。
- $2代表文本行中的第二个数据字段。
- $n代表文本行中的第n个数据字段。
awk默认的字段分割符是任意的空白字符,在文本行中,每个数据字段都是通过子弹分割符换分的。awk在读取一行文本时,会用预定的字段分隔符换分每个数据字段。
root@chengyan-virtual-machine:~# cat data.txt
One line of test txt.
Two lines of test txt.
Three lines of test text.
root@chengyan-virtual-machine:~# awk 'print $1' data.txt
One
Two
Three
root@chengyan-virtual-machine:~#
上面只用了$1字段变量来表示“仅显示每行文本的第一个数据字段”。要读取采用了其他字段分隔符的文件,可以用-F选项手动指定。
awk允许将多条命令组合称为一个正常的程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可。
root@chengyan-virtual-machine:~# echo "My name is Rich" | awk '$4="Christine";print $0'
My name is Christine
root@chengyan-virtual-machine:~# awk '
> $4="Christine";
> print $0
> '
My name is Rich
My name is Christine
His name is wanghao
His name is Christine
当用了起始的单引号后,bash shell会使用>来提示输入更多数据,可以在每行加一条命令,知道输入了结尾的单引号。因为没有在命令行中指定文件名,awk程序需要用户输入获得数据,因此当运行这个程序的时候,会一直等待用户输入文本,此时如果要退出程序,只需要输入CTRL+D即可。
root@chengyan-virtual-machine:~# cat awk.sh
print $1"'s home directory is " $6
root@chengyan-virtual-machine:~# awk -F : -f awk.sh /etc/passwd
root's home directory is /root
daemon's home directory is /usr/sbin
bin's home directory is /bin
sys's home directory is /dev
sync's home directory is /bin
games's home directory is /usr/games
man's home directory is /var/cache/man
在脚本文件中,可以指定多条命令,只要一条命令放在一行就行.
关键字
BEGIN
awk中还可以指定脚本命令运行的时机,默认情况下,awk会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前运行一些脚本命令,这就需要使用BEGIN关键字。
BEGIN关键字会强制awk在读取数据前执行该关键字后指定的脚本命令。
root@chengyan-virtual-machine:~# awk 'BEGINprint "The data file contents:"
> print $0' data.txt
The data file contents:
One line of test txt.
Two lines of test txt.
Three lines of test text.
root@chengyan-virtual-machine:~#
这个脚本命令分为两部分,BEGIN部分的脚本指令会在awk命令处理函数前运行,而真正用来处理数据的是第二段脚本命令。
END
END关键字允许指定一些脚本命令,awk会在读取完数据后执行。
root@chengyan-virtual-machine:~# awk 'BEGINprint "The data file contents:"
print $0
ENDprint "End of file"' data.txt
The data file contents:
One line of test txt.
Two lines of test txt.
Three lines of test text.
End of file
root@chengyan-virtual-machine:~#
变量
在awk脚本程序中,支持使用变量来存取值,awk支持两种不同类型的变量,即内建变量和自定义变量。
内建变量是awk本身就创建好的,用户可以直接使用的变量,这些变量用来存放处理数据文件中的某些字段和记录的信息。自定义变量是awk支持用户自己创建的变量。
常见的内建变量包括数据字段变量($0,$1,$2,....)和其他变量。
字符和记录分隔符变量:
FIELDWIDTHS:由空格分割的一列数字,定义了每个数据字段的确切宽度。FNR:当前输入文档的记录编号,常在有多个输入文档时使用。NR:输入流的当前记录编号。FS:输入字段分隔符。RS:输入记录分隔符,默认为换行符\\n。OFS:输出字段分隔符,默认为空格。ORS:输出字段分隔符,默认为换行符\\n。
环境信息变量:
ARGC:命令行参数个数。ARGIND:当前文件在ARGC中的位置。ARGV:包含命令行参数的数组。CONVFMT:数字的转换格式,默认值为%.6g。ENVIRON:当前shell环境变量及其值组成的关联数组。ERRNO:当前读取或关闭输入文件发生错误时的系统错误号。FILENAME:当前输入文档的名称。FNR:当前数据文件中的数据行数。IGNORECASE:设成非0值时,忽略awk命令中出现的字符串的字符串大小。NF:数据文件中的字段总数。OFMT:数字的输出格式,默认值为%.6g。RLENGTH:由match函数所匹配的子字符串的长度。TSTART:由match函数所匹配的子字符串的起始位置。
FS/OFS
变量FS和OFS定义了awk如何处理数据流中的数据字段。
root@chengyan-virtual-machine:~# cat data.txt
data11,data12,data13,data14,data15
data21,data22,data23,data24,data25
data31,data32,data33,data34,data35
root@chengyan-virtual-machine:~# awk 'BEGINFS=",";OFS="-"print $1,$2,$3' data.txt
data11-data12-data13
data21-data22-data23
data31-data32-data33
root@chengyan-virtual-machine:~# awk 'BEGINFS=",";OFS="--"print $1,$2,$3' data.txt
data11--data12--data13
data21--data22--data23
data31--data32--data33
root@chengyan-virtual-machine:~#
FIELDWIDTHS
FIELDWIDTHS变量允许用户不依靠字段分隔符来读取记录,数据如果没有设置分隔符,而是放在特定列中,这种情况下,必须设定FIELDWIDTHS变量来匹配数据在记录中的位置。一旦设置了FIELDWIDTH变量,awk就会忽略FS变量,并根据提供的字段宽度来计算字段。
root@chengyan-virtual-machine:~# cat data1.txt
1005.3247596.37
115-2.349194.00
05810.1298100.1
root@chengyan-virtual-machine:~# awk 'BEGINFIELDWIDTHS="3 5 2 5"print $1,$2,$3,$4' data1.txt
1005.3247596.37
115-2.349194.00
05810.1298100.1
root@chengyan-virtual-machine:~#
一旦设置了FIELWIDTHS变量的值,就不能在改变了,所以并不适用于变长的字段。
RS/ORS
变量RS和ORS定义了awk程序如何处理数据流中的字段,默认情况下,awk将RS和ORS设为换行符。默认的RS值标明,输入数据流中的每行新文本都是一条新纪录。
root@chengyan-virtual-machine:~# cat data2.txt
Riley Mullen
123 Main Street
Chicago,IL 60601
(312)555-1234
Frank Wiliams
456 Oak Street
Indianapolis,IN 46201
(317)555-9876
Haley Snell
4231 Elm Street
Detroit,MI 48201
(313)555-4938
root@chengyan-virtual-machine:~# awk 'BEGINFS="\\n";RS=""print $1,$4' data2.txt
Riley Mullen (312)555-1234
Frank Wiliams (317)555-9876
Haley Snell (313)555-4938
root@chengyan-virtual-machine:~#
FNR/NR
FNR变量含有当前数据文件中已处理过的记录数,NR变量则含有已处理过的记录总数。
root@chengyan-virtual-machine:~# cat data.txt
data11,data12,data13,data14,data15
data21,data22,data23,data24,data25
data31,data32,data33,data34,data35
root@chengyan-virtual-machine:~# awk '
> BEGINFS=","
> print $1, "FNR="FNR, "NR="NR
> ENDprint "There were",NR,"records processed"' data.txt data.txt
data11 FNR=1 NR=1
data21 FNR=2 NR=2
data31 FNR=3 NR=3
data11 FNR=1 NR=4
data21 FNR=2 NR=5
data31 FNR=3 NR=6
There were 6 records processed
root@chengyan-virtual-machine:~#
可以发现,当使用一个数据文件作为输入时,FNR和NR的值相同的,如果多个文件同时作为输入时,FNR的值会在处理每个数据文件时被重置,而NR的值则会继续计数知道处理完所有的数据文件。
Linux文本处理三剑客grepsedawk用法详解
Linux文本处理工具grep、sed、awk用法详解
文章目录
1、grep
1)grep简介
grep命令是一个Linux文本处理工具,它与egrep命令属于同一系列,这些命令都是用于对文件和文本执行重复搜索任务的工具。我们可以通过grep命令指定特定搜索条件来搜索文件及其内容以获取有用的信息。grep是全局搜索正则表达式并打印出匹配的行,其抓取数据是贪婪模式,即不会漏掉过滤内容,但准确性会相对降低。
2)grep命令格式
grep 匹配条件 处理文件名称
grep root passwd ##过滤root关键字所在的行
grep -i root passwd ##忽略大小写过滤root关键字所在的行
grep -E "\\<root" passwd ##过滤root字符之前没有字符的行
grep -E "root\\>" passwd ##过滤root字符之后没有字符的行
grep -数字 ##显示过滤行以及上面几行和下面几行
grep -n ##显示匹配的行所在行号
grep -A数字 ##显示过滤行以及下面几行
grep -B数字 ##显示过滤行以及上面几行
grep -v ##反向过滤
实验步骤:
1)切换到一个空目录/mnt中,cp /etc/passwd .复制/etc/passwd文件到该目录(. 表示当前目录)中,避免文件内容过长删除一部分内容,使用grep命令在截取以某个字符串结尾的数据时,如果需要判断的结尾字符串有多个,需要用 | 连接多个正则表达式,但执行命令后抓取数据失败,这是因为 | 是扩展表达式,我们需要使用egrep命令才能用 | 连接多个判断字符串进行数据抓取,为了便于记忆,我们可以使用统一命令grep -E
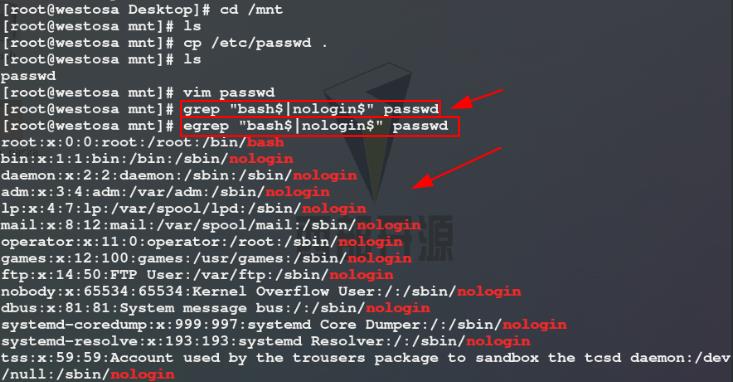
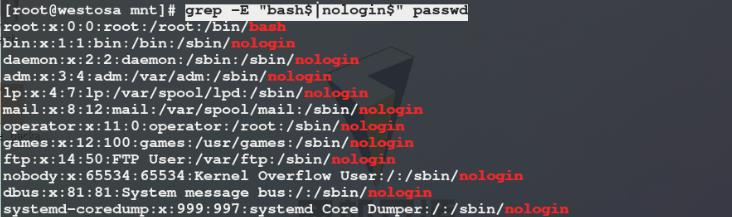
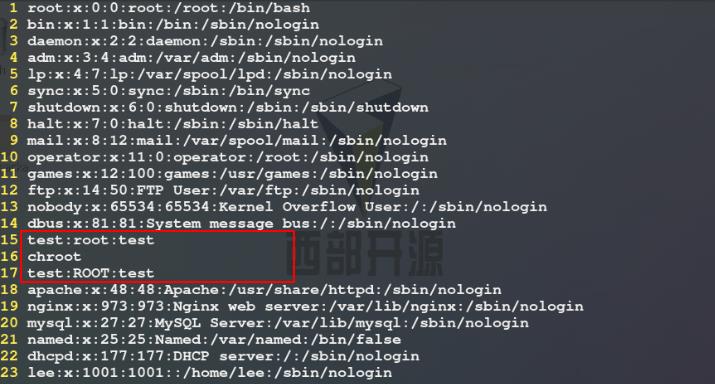
2)编辑/mnt/passwd文件,在其中加入几行数据用来进行命令测试
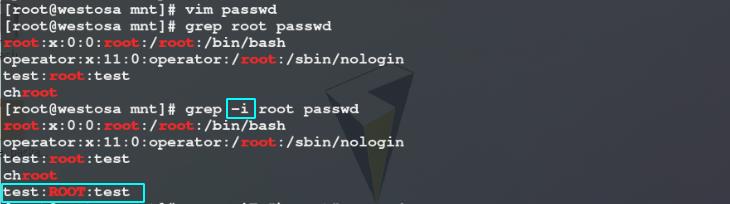
3)使用grep命令过滤passwd文件中root关键字所在的行、使用-i 参数忽略大小写过滤passwd文件中root关键字所在的行,可以看到过滤结果中多了一条含有ROOT字符串的行
4)使用grep -E命令过滤passwd文件中root字符前没有字符的行、root字符后没有字符的行
注意: grep使用"<“或”>"只能抓取匹配字符串之前或之后不能有字符串的数据,像/root也会被查找出来,这是因为/为单个字符,而不是字符串
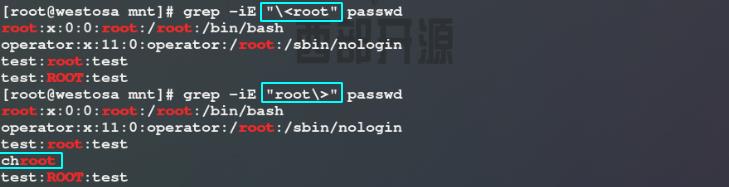
5)使用grep命令过滤passwd文件中ROOT关键字所在行及其上、下5行;使用grep命令过滤passwd文件中ROOT关键字所在行并显示行号;使用grep命令过滤显示passwd文件中ROOT关键字所在行及下面3行;使用grep命令过滤显示passwd文件中ROOT关键字所在行及上面3行
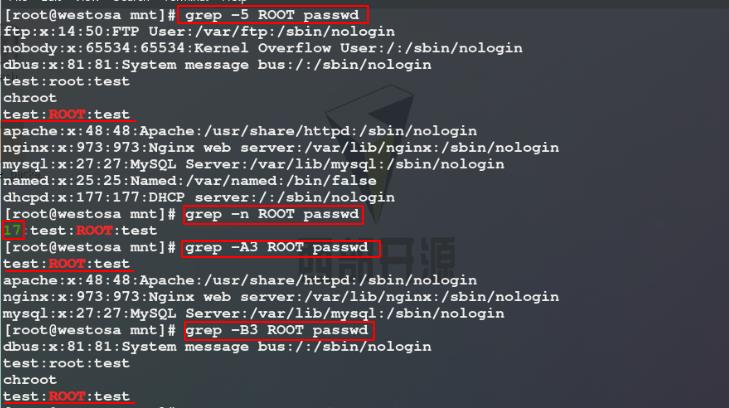
6)使用-v参数反向过滤passwd文件中不含有root关键字的行
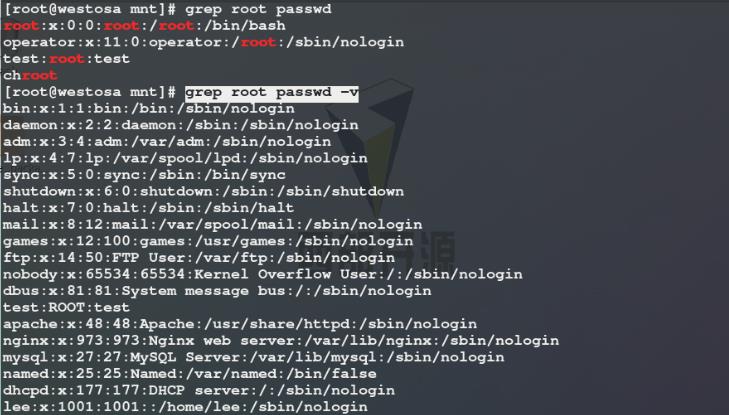
7)命令练习:过滤passwd文件中行首、行尾不以root开头、结尾,行中有root关键字的行并显示

3)grep命令字符数量匹配规则
| 正则表达式 | 含义 |
|---|---|
| ^westos | 以westos关键字开头 |
| westos$ | 以westos结尾 |
| w…s | w开头s结尾中间含有3个任意字符 |
| …s | s结尾前面有3个任意字符 |
| * | 字符出现次数任意(即0次到任意次) |
| ? | 字符出现0到1次 |
| + | 字符出现1次到任意次 |
| {n} | 字符出现n次 |
| {m,n} | 字符出现m到n次 |
| {,n} | 字符出现0到n次 |
| {m,} | 字符最少出现m次 |
实验步骤:
1)切换到一个空目录/mnt中,新建并编辑文件westos如下

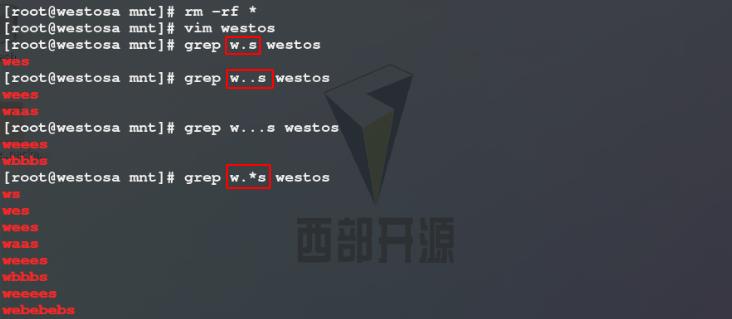
2)使用grep命令分别过滤westos文件中,以w开头s结尾中间含有1 / 2 / 3 / 任意个任意字符的关键字所在的行( * 表示任意字符 . 的个数任意)
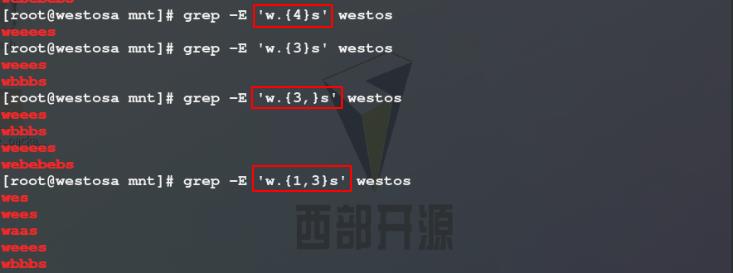
3)使用grep -E命令过滤westos文件中,以w开头s结尾中间含有4个 / 含有3个 / 最少含有3个 / 含有1到3个任意字符的关键字所在的行
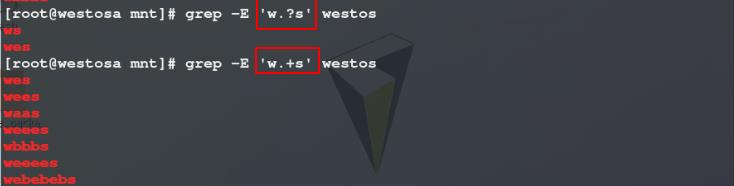
4)使用grep -E命令过滤westos文件中,以w开头s结尾中间含有0到1个 / 含有1到任意个任意字符的关键字所在的行
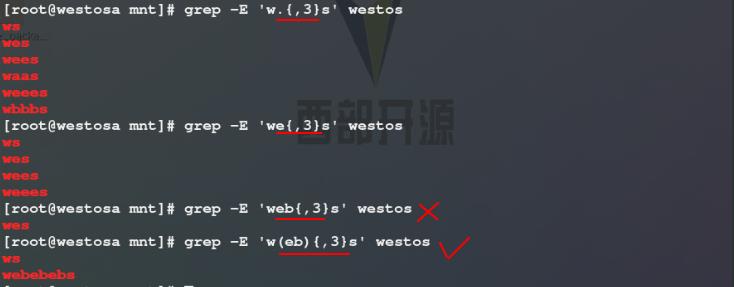
5)使用grep -E命令过滤westos文件中,以w开头s结尾中间最多含有3个任意字符 / 字符e / 字符串eb的关键字所在的行
注意: 关键字的中间匹配项为字符串时,必须给字符串外加上(),这样grep命令执行时才会将其作为一个整体来处理
6)命令练习:编写脚本显示系统中能被su命令切换的用户名称
思路:/etc/passwd文件中以bash、sh结尾的行所对应的用户就是系统中能被su命令切换的用户(即有交互的shell),我们可以使用grep -E命令过滤显示/etc/passwd文件中以bash、sh结尾的行后,通过管道使用cut命令以:为分隔符截取第一列(用户名称所在列)


2、sed
1)sed简介
sed 全名叫 stream editor即流编辑器,与 vim 的交互式编辑方式截然不同,作为一种非交互式编辑器,sed使用预先设定好的编辑指令对输入的文本进行编辑,完成之后输出编辑结果。其功能十分强大,加上正则表达式的支持,可以进行大量的复杂文本的编辑操作。
2)sed命令格式
a)p :显示
sed 参数 命令 处理对象
sed -n 5p westos ##显示第5行
sed -n 3,5p westos ##显示第3行到第5行
sed -n "3p;5p" westos ##显示第3行和第5行
sed -n 1,5p westos ##显示1-5行
sed -n '5,$p' westos ##显示第5行到最后一行
sed -n '/^#/p' fstab ##显示以#开头的行
b)d :删除
sed 5d westos ##删除第5行
sed '/^#/d' fstab ##把以#开头的行删除
sed '/^UUID/!d' fstab ##删除不是以UUID开头的所有行
sed '5,$d' westos ##删除第5行到最后一行
c)a :添加
sed '$a hello world' fstab ##在最后一行后添加字符串
sed '$a hello\\nworld' fstab ##在最后一行后添加字符串,使用换行符隔开
sed '/^#/a hello world' fstab ##在以#开头的行后添加字符串
d)c :替换
sed '/^#/c hello world' fstab ##将所有以#开头的行替换为指定字符串
sed '5chello world' westos ##将第5行替换为指定字符串
e)w :把符合的行写入到指定文件中
sed '/^UUID/w westofile' westos :把westos中UUID开头的行写入westosfile中
f)i :插入
sed '5ihello westos' westos:在westos文件的第5行前插入指定字符串
g)r :整合文件
sed '5r westofile' westos:将westofile文件中的内容整合到westos文件的第5行后
实验步骤:
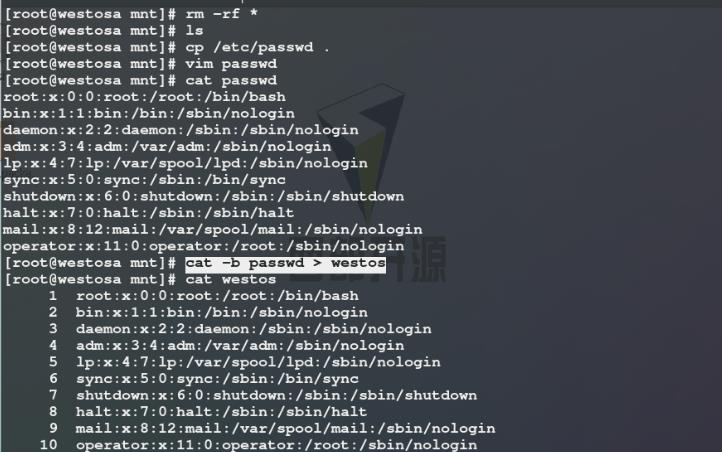
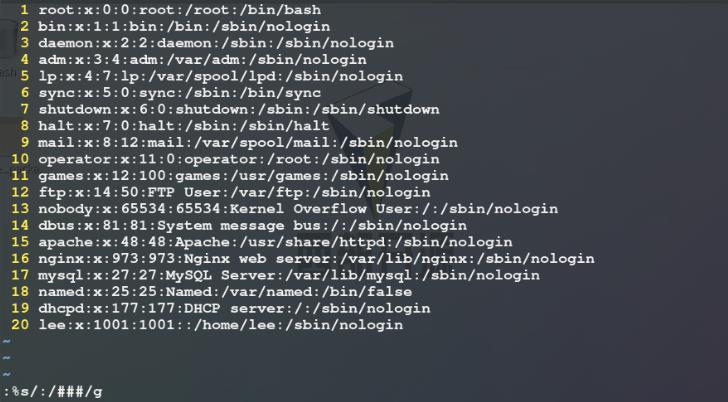
1)切换到一个空目录/mnt中,复制/etc/passwd文件到该目录(.表示当前目录)中,避免文件内容过长删除一部分内容,再cat -b westos将文件内容带行号显示并将显示结果导入到/mnt下的另一新建文件westos中(加行号是为了便于后续观察命令的执行效果)
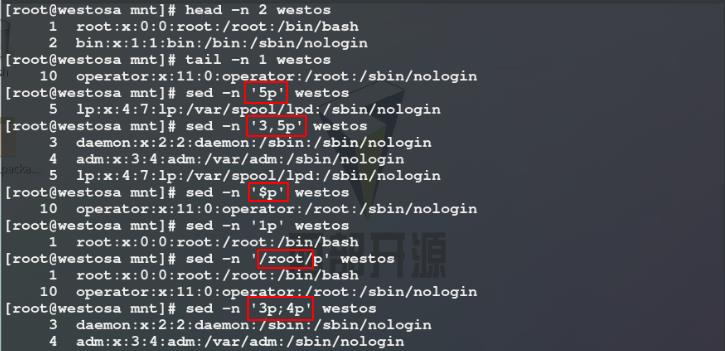
2)我们可以使用head命令 / tail命令查看文件的前几行 / 后几行,但无法查看指定行 ,使用sed命令可以解决这一问题,如下图所示:使用sed -n命令查看显示westos文件的第5行 / 第3行到第5行 / 最后一行 / 含有root关键词的行 / 第3行和第4行
注意: sed 5p 不加-n参数时不仅显示文件的指定行,还会显示其他所有的行,-n参数只显示文件的指定行
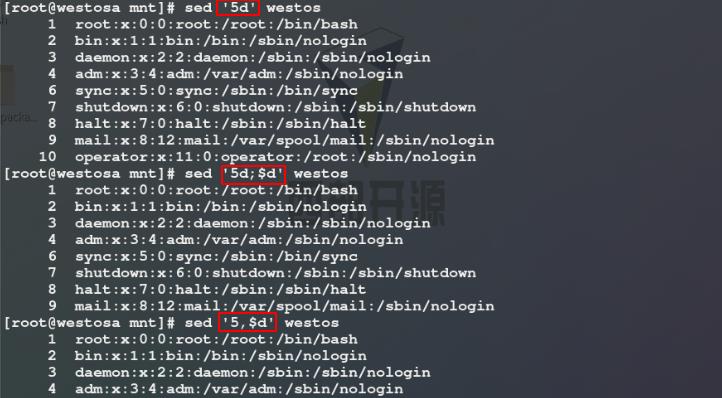
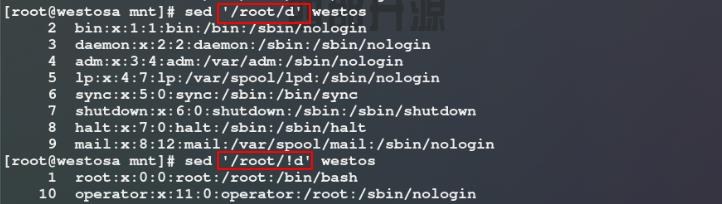
3)使用sed命令删除westos文件的第5行 / 第5行和最后一行 / 第5行到最后一行 / 含有root关键词的行 / 不含有root关键词的行
注意: 使用d参数进行删除时不需要加-n,因为指定行已删除,所以无输出显示
4)使用sed命令在第1行 / 最后一行后添加内容,这里可以使用换行符隔开添加内容中的字符串
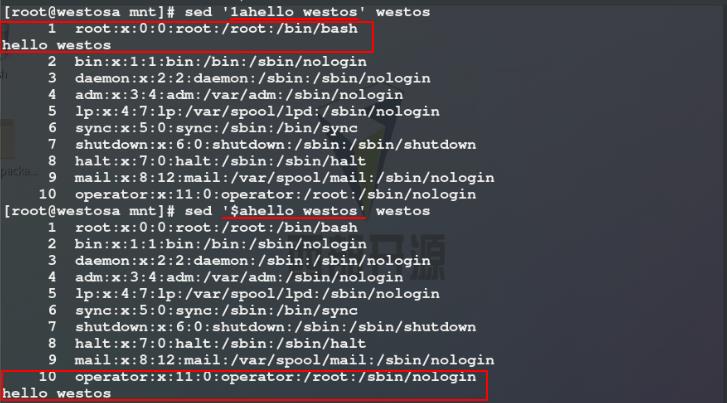
5)使用a参数进行添加时默认添加在指定行之后,我们可以使用i参数将字符串插入到指定行之前
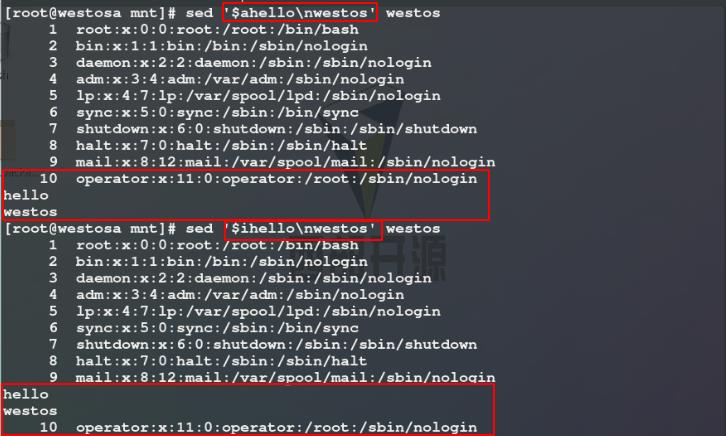
6)使用c参数将westos文件的第1行 / 含有root关键词的行替换为指定字符串
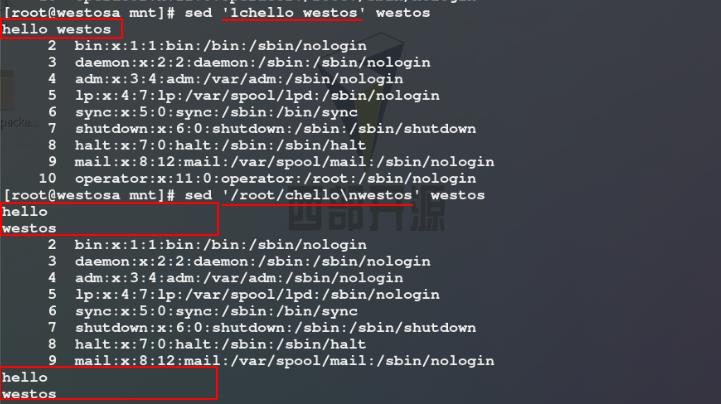
7)使用w参数将westos文件中含有root关键词的行写入文件file中,相当于在显示含有root关键词的行后进行了输出重定向操作
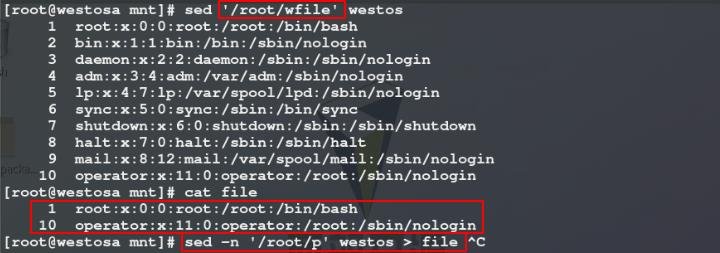
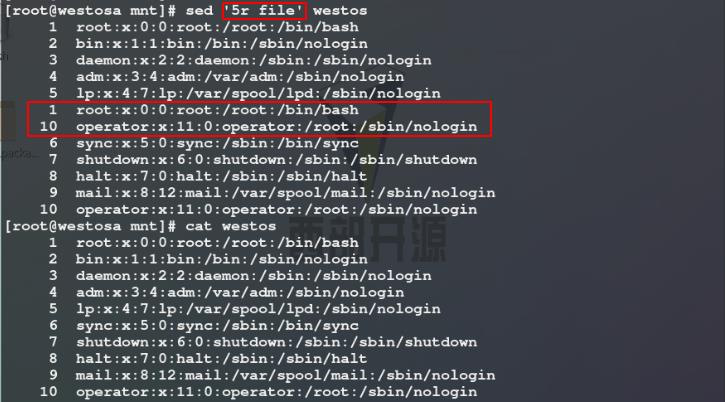
8)使用r参数将file文件中的内容整合到westos文件的第5行后,但此时查看westos文件内容无变化,这是因为整合文件时需要加入-i参数才把sed处理的内容保存到westos文件中
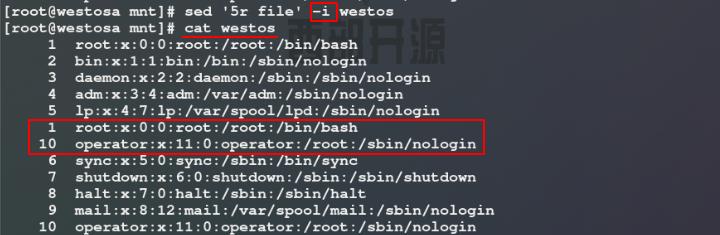
3)sed字符替换
实验步骤:
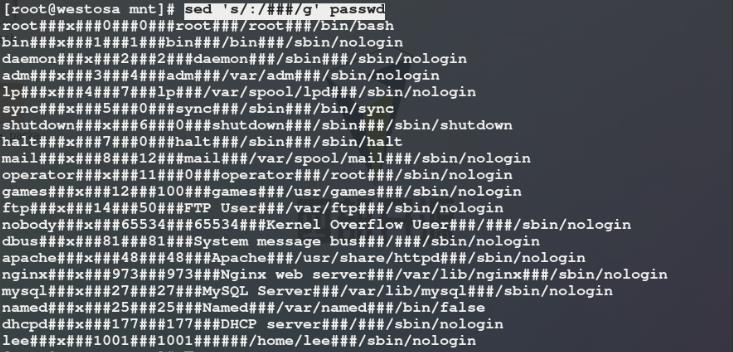
1)切换到一个空目录/mnt中,复制/etc/passwd文件到该目录中,避免文件内容过长删除一部分内容,文件中的内容是以:分隔的,我们可以使用vim编辑passwd文件进行字符替换,也可以使用sed进行字符替换,字符替换时要用 ‘ ’ 将替换策略引起来
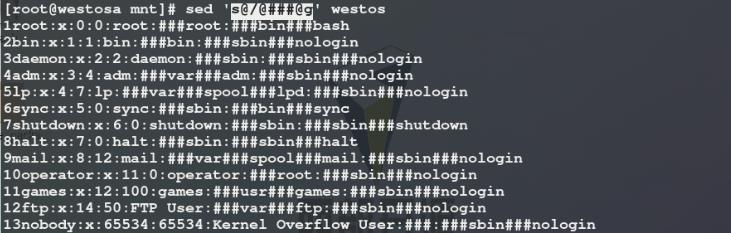
使用sed命令将passwd文件中每一行每一列中的:替换为###
2)=表示给文件中的每一行前加行号,但是默认加在每一行的前一行,如果想要将行号加在每一行前,我们需要通过管道将行号后的换行符\\n替换为空(N表示提前加载sed处理行的下一行)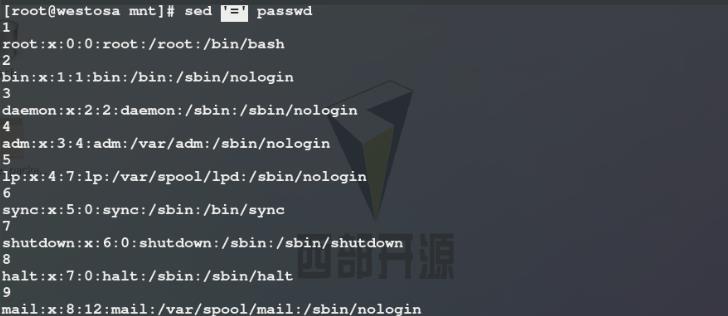
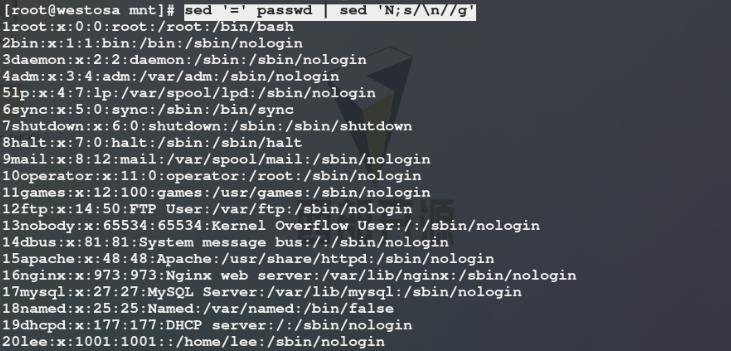
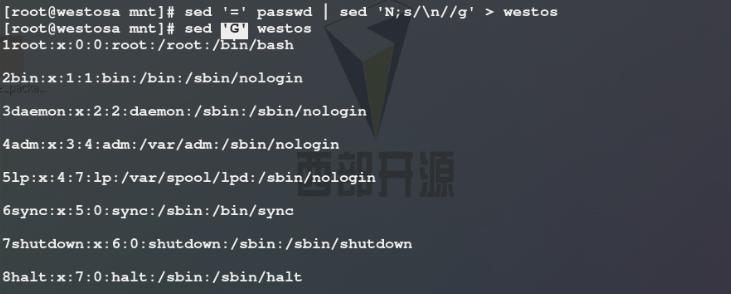
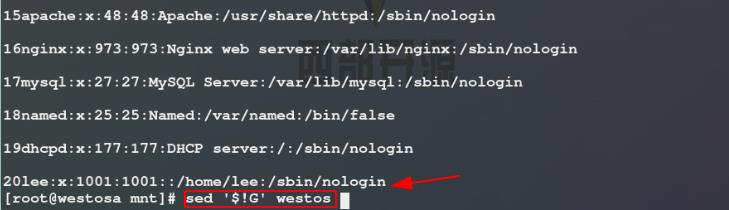
3)给passwd文件中每一行前添加行号后将显示结果输出重定向生成另一文件westos,G表示给westos文件的每一行后添加空行,$!G表示除最后一行外给westos文件的每一行后添加空行
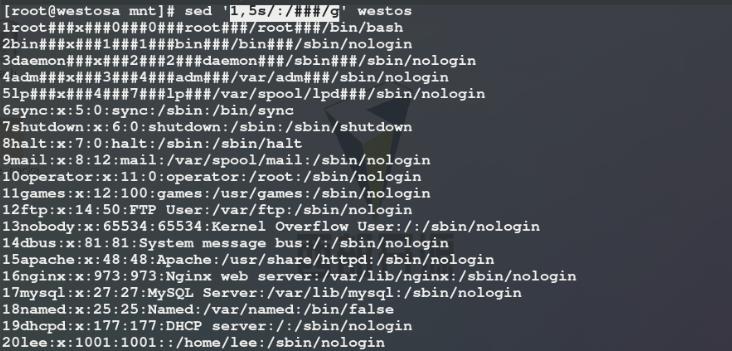
4)使用sed命令将westos文件中第1行到第5行每一列中的:替换为###
使用sed命令将westos文件中sync关键字所在行到halt关键字所在行每一列中的:替换为###
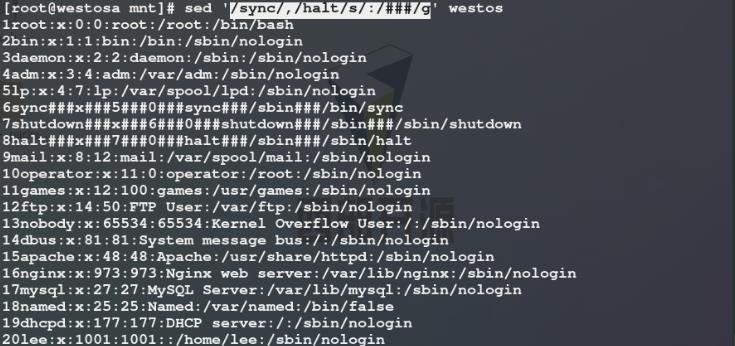
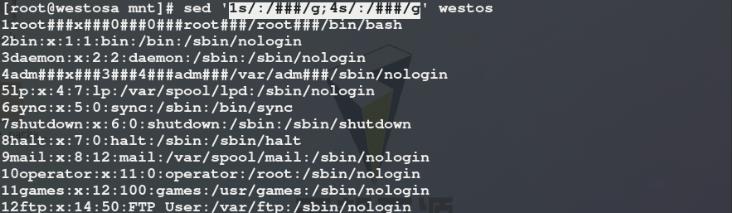
5)使用sed命令将westos文件中第1行和第4行每一列中的:替换为###,有以下两种方式:
方法一: 在一个替换策略中写两个表达式用;隔开
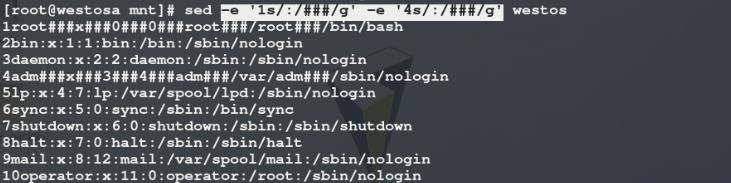
方法二: 用两个-e连接两个替换策略
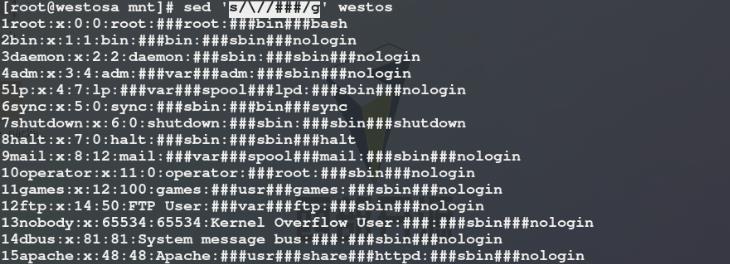
6)使用sed命令将westos文件中每一行每一列中的特殊字符/(表达式中需要用/隔开)替换为###,有以下两种方式:
方法一: 在 / 前加 \\ 转译特殊字符
方法二: 使用 @ 符替换表达式中用来隔开的 / 符
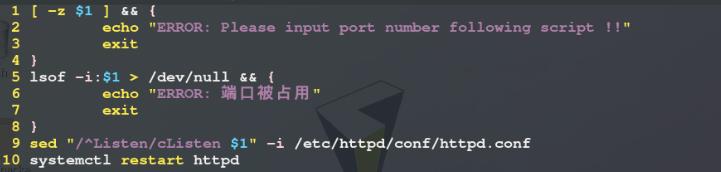
7)命令练习:假设selinux为关闭状态,编写脚本Apache_port.sh修改http端口号
思路:首先对执行脚本时脚本后用户输入的字符串进行是否为空的判断,如果为空则退出运行并提示用户输入端口号,如果不为空则对用户输入的端口号使用lsof -i:命令检测该端口是否被占用,如果被占用则退出运行并报错,如果未被占用则使用sed命令将httpd服务主配置文件/etc/httpd/conf/httpd.conf中的端口设定语句替换为用户输入端口号对应的端口设定语句,接着重启httpd服务

3、awk
1)awk简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
2)awk命令格式
awk -F 分隔符 BEGIN{}{}END{} FILENAME:这里FILENAME指的是文件名称本身
表达式 #含义
westos #westos变量值
“westos” #westos字符串
/条件1|条件2/ #条件1或者条件2
/条件1/||/条件2/ #条件1或者条件2
/条件1/&&/条件2/ #条件1且条件2
$0 #所有的列
$1 #第一列
$2 #第二列
$3 #第三列
实验步骤:
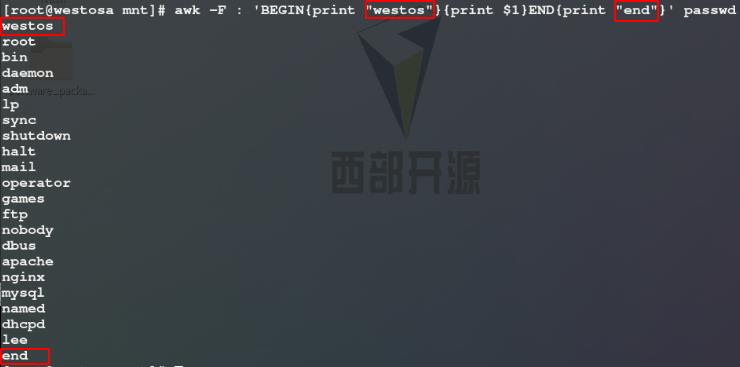
1)使用awk命令,首先输出显示westos,接着-F指定以:为分隔符截取显示passwd文件的第一列,最后输出显示end
注意: ‘ ’引起来的截取策略中的字符串需要用“ ”引起来,否则awk命令会将其当作变量处理(即不会输出显示指定字符串本身)

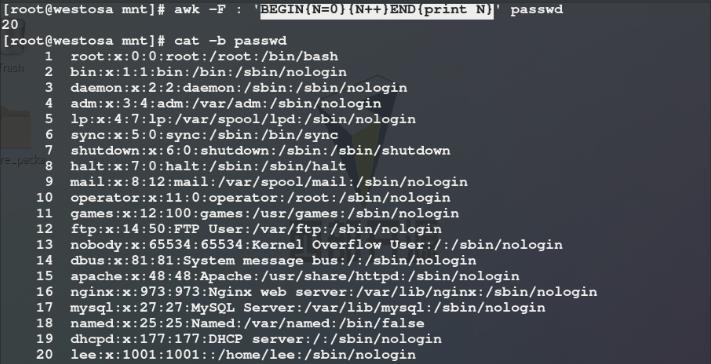
2)使用awk命令统计passwd文件行数:给变量N赋初值为0,awk每读取一行文件内容变量N就进行一次自加操作,最后输出变量N的值即为passwd文件的行数
3)使用awk命令-F指定以:为分隔符截取显示passwd文件的第一列

使用awk命令以:为分隔符截取显示passwd文件中以bash结尾的行的第一列;使用awk命令以:为分隔符截取显示passwd文件中以bash结尾且含有root关键字的行的第一列;使用awk命令以:为分隔符截取显示passwd文件中以bash结尾且不含有root关键字(!表示不含有)的行的第一列;使用awk命令以:为分隔符截取显示passwd文件中以bash结尾或含有root关键字的行的第一列
注意: |表示或时是一个截取条件中的两个元素,||表示或时是两个截取条件中各自的一个元素
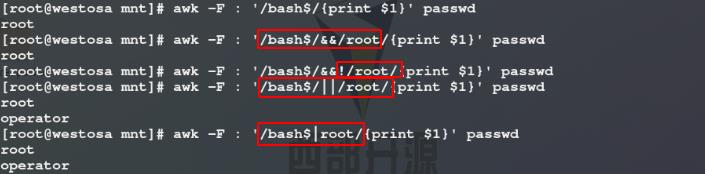
4)使用awk命令以:为分隔符截取第七列以bash结尾的行的第一列($7~表示指定第七列);使用awk命令以:为分隔符截取第七列不以bash结尾的行的第一列
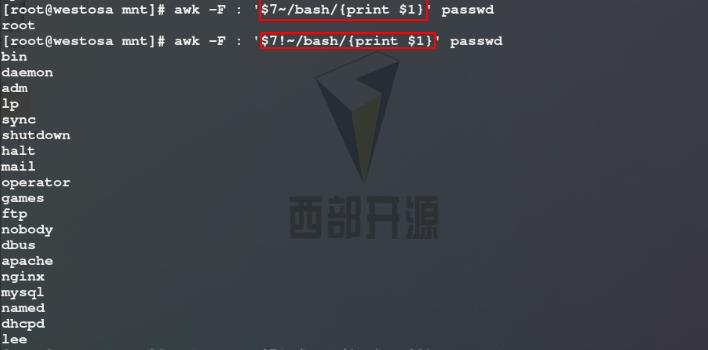
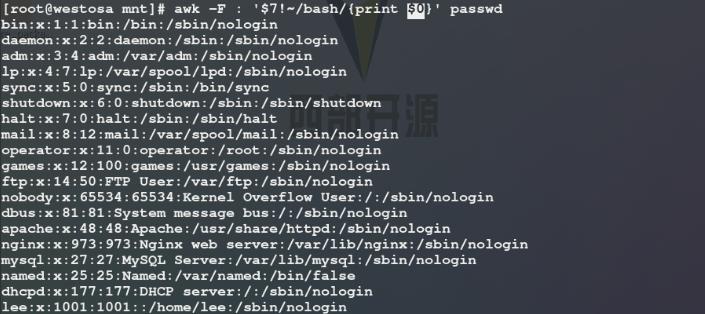
使用awk命令以:为分隔符截取第七列不以bash结尾的行的全部列($0 表示所有的列)
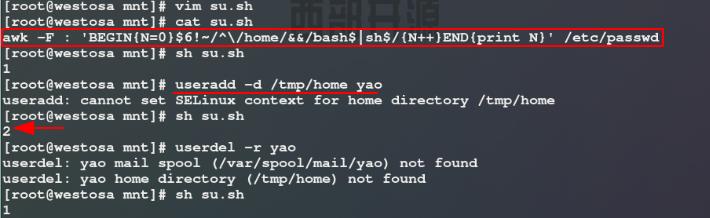
5)命令练习:统计在系统中能su切换的且用户家目录不在/home下的用户数量
思路:使用awk命令以:为分隔符截取/etc/passwd文件中第六列不以/home开头的(/需要转译;不能直接写不含有home关键字,存在类似用户家目录为/tmp/home这种情况)、并且以bash或sh结尾的行,对截取结果进行计数,这里我们可以创建用户对脚本进行测试
6)命令练习:统计系统内存使用总量
思路:使用ps ax -o %mem可以查看所有进程占用内存量,将查看结果通过管道,使用awk命令去掉字符串或内存占用为0.0所在的行后将所有值($1表示读取每一行的第一个字符串)循环+=,得到所有进程占用内存总量(字符串不去掉不影响计算结果,但会降低脚本执行效率)


以上是关于linux三剑客(grepsedawk)的主要内容,如果未能解决你的问题,请参考以下文章