ARMv8 SIMD和浮点指令编程Libyuv I420 转 ARGB 流程分析
Posted TYYJ-洪伟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARMv8 SIMD和浮点指令编程Libyuv I420 转 ARGB 流程分析相关的知识,希望对你有一定的参考价值。
Libyuv 可以说是做图形图像相关从业者绕不开的一个常用库,它使用了单指令多数据流提升性能。以 ARM 处理为主线,通过 I420 转 ARGB 流程来分析它是如何流转的。
Libyuv 是一个开源项目,包括 YUV 的缩放和转换功能。
- 使用邻近、双线性或 box 插值缩放 YUV。
- 将网络摄像头格式转化为 YUV。
- 转换为 RGB 格式的渲染或效果。
- 旋转 90、180 或 270 度。
- 针对 x86/x64 上的 SSSE3/AVX2 进行优化。
- 针对 Arm 上的 NEON 优化。
- 针对 Mips 上的 MSA 优化。
官方地址 https://chromium.googlesource.com/libyuv/libyuv。
libyuv.h 是调用 Libyuv API 的入口。I420ToARGB 这个转换函数位于 libyuv/convert_argb.h 头文件内。
libyuv.h
#ifndef INCLUDE_LIBYUV_H_
#define INCLUDE_LIBYUV_H_
#include "libyuv/basic_types.h"
#include "libyuv/compare.h"
#include "libyuv/convert.h"
#include "libyuv/convert_argb.h"
#include "libyuv/convert_from.h"
#include "libyuv/convert_from_argb.h"
#include "libyuv/cpu_id.h"
#include "libyuv/mjpeg_decoder.h"
#include "libyuv/planar_functions.h"
#include "libyuv/rotate.h"
#include "libyuv/rotate_argb.h"
#include "libyuv/row.h"
#include "libyuv/scale.h"
#include "libyuv/scale_argb.h"
#include "libyuv/scale_row.h"
#include "libyuv/scale_uv.h"
#include "libyuv/version.h"
#include "libyuv/video_common.h"
#endif // INCLUDE_LIBYUV_H_
LIBYUV_API 是导出 API 使用的修饰符,ARM 平台上无作用。I420ToARGB 函数入参共有 10 个。
src_y —— YUV Y 分量
src_stride_y —— Y 分量步幅,也就是多少个 Y 换一行
src_u —— YUV U 分量
src_stride_u —— U 分量步幅,由于 I420 上下两行附近 4 个 Y 共用一组 UV,所以每行 U 的数量应该设置为宽的一半
src_v —— YUV V 分量
src_stride_u —— V 分量步幅,同样为宽的一半
dst_argb —— ARGB 输出
dst_stride_argb —— ARGB 步幅
width —— 宽
height —— 高
libyuv/convert_argb.h
// Convert I420 to ARGB.
LIBYUV_API
int I420ToARGB(const uint8_t* src_y,
int src_stride_y,
const uint8_t* src_u,
int src_stride_u,
const uint8_t* src_v,
int src_stride_v,
uint8_t* dst_argb,
int dst_stride_argb,
int width,
int height);
I420ToARGB 函数内部仅仅调用了 I420ToARGBMatrix,而 I420ToARGBMatrix 的入参多了个 kYuvI601Constants,从名字上不难得出这使用了 BT.601 标准的公式。YUV RGB 转化具体可参见《详解 YUV,一文搞定 YUV 是什么!》。
I420ToARGBMatrix 函数核心流程:
- I422ToARGBRow 这个函数指针先指向 C 实现版本的 I422ToARGBRow_C 函数。
- 入参高度(height)为负意味着反转图像,dst_argb 指向最后一行,而 dst_stride_argb(ARGB 步幅)修改为负,把源图像的第一行写入最后一行,第二行写入倒数第二行,以此类推。
- 如果定义了 HAS_I422TOARGBROW_NEON,并且调用 TestCpuFlag 测试 CPU 是否支持 NEON,如果支持 NEON,则 I422ToARGBRow 函数指针赋值为 I422ToARGBRow_Any_NEON,当入参宽度是 8 像素对齐时,I422ToARGBRow 最终赋值为 I422ToARGBRow_NEON。我们假设使用的是 arm64-v8a 的芯片,所以此处一定是支持 NEON 的,并且假设宽度是 640,则 I422ToARGBRow 会被赋值为 I422ToARGBRow_NEON。
- 以高 for 循环开始遍历调用 I422ToARGBRow_NEON 处理每一行图像,
y & 1用来隔一行去新增 U、V 分量的步长,I420 中上下两行的 4 个 Y 会复用一组 UV。
convert_argb.cc
// Convert I420 to ARGB with matrix.
LIBYUV_API
int I420ToARGBMatrix(const uint8_t* src_y,
int src_stride_y,
const uint8_t* src_u,
int src_stride_u,
const uint8_t* src_v,
int src_stride_v,
uint8_t* dst_argb,
int dst_stride_argb,
const struct YuvConstants* yuvconstants,
int width,
int height)
int y;
void (*I422ToARGBRow)(const uint8_t* y_buf, const uint8_t* u_buf,
const uint8_t* v_buf, uint8_t* rgb_buf,
const struct YuvConstants* yuvconstants, int width) =
I422ToARGBRow_C;
if (!src_y || !src_u || !src_v || !dst_argb || width <= 0 || height == 0)
return -1;
// Negative height means invert the image.
if (height < 0)
height = -height;
dst_argb = dst_argb + (height - 1) * dst_stride_argb;
dst_stride_argb = -dst_stride_argb;
......
#if defined(HAS_I422TOARGBROW_NEON)
if (TestCpuFlag(kCpuHasNEON))
I422ToARGBRow = I422ToARGBRow_Any_NEON;
if (IS_ALIGNED(width, 8))
I422ToARGBRow = I422ToARGBRow_NEON;
#endif
......
for (y = 0; y < height; ++y)
I422ToARGBRow(src_y, src_u, src_v, dst_argb, yuvconstants, width);
dst_argb += dst_stride_argb;
src_y += src_stride_y;
if (y & 1)
src_u += src_stride_u;
src_v += src_stride_v;
return 0;
// Convert I420 to ARGB.
LIBYUV_API
int I420ToARGB(const uint8_t* src_y,
int src_stride_y,
const uint8_t* src_u,
int src_stride_u,
const uint8_t* src_v,
int src_stride_v,
uint8_t* dst_argb,
int dst_stride_argb,
int width,
int height)
return I420ToARGBMatrix(src_y, src_stride_y, src_u, src_stride_u, src_v,
src_stride_v, dst_argb, dst_stride_argb,
&kYuvI601Constants, width, height);
kYuvI601Constants 定义在 convert_argb.h,实现在 row_common.cc 中。kYuvI601Constants 是个 YuvConstants 结构体,这个结构体又定义在 row.h 中。
libyuv/convert_argb.h
// Conversion matrix for YUV to RGB
LIBYUV_API extern const struct YuvConstants kYuvI601Constants; // BT.601
由于假设了 CPU 的类型为 arm64-v8a,所以 __aarch64__ 宏定义是存在的,预编译的时候就会使用对应的代码。kUVCoeff 和 kRGBCoeffBias 会被相应的赋值。
libyuv/row.h
#if defined(__aarch64__) || defined(__arm__)
// This struct is for ARM color conversion.
struct YuvConstants
uvec8 kUVCoeff;
vec16 kRGBCoeffBias;
;
#else
// This struct is for Intel color conversion.
struct YuvConstants
uint8_t kUVToB[32];
uint8_t kUVToG[32];
uint8_t kUVToR[32];
int16_t kYToRgb[16];
int16_t kYBiasToRgb[16];
;
MAKEYUVCONSTANTS(I601, YG, YB, UB, UG, VG, VR) 展开宏定义,就会出现结构体 kYuvI601Constants 和 kYvuI601Constants。具体结构体赋值是使用另外一个宏 YUVCONSTANTSBODY 定义的,同样预编译会选择 __aarch64__ 这个分支。
YUV 转 RGB 使用如下公式,化简后就是注释中的公式:

row_common.cc
// Macros to create SIMD specific yuv to rgb conversion constants.
// clang-format off
#if defined(__aarch64__) || defined(__arm__)
// Bias values include subtract 128 from U and V, bias from Y and rounding.
// For B and R bias is negative. For G bias is positive.
#define YUVCONSTANTSBODY(YG, YB, UB, UG, VG, VR) \\
UB, VR, UG, VG, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, \\
YG, (UB * 128 - YB), (UG * 128 + VG * 128 + YB), (VR * 128 - YB), YB, 0, \\
0, 0
#else
......
#endif
// clang-format on
#define MAKEYUVCONSTANTS(name, YG, YB, UB, UG, VG, VR) \\
const struct YuvConstants SIMD_ALIGNED(kYuv##name##Constants) = \\
YUVCONSTANTSBODY(YG, YB, UB, UG, VG, VR); \\
const struct YuvConstants SIMD_ALIGNED(kYvu##name##Constants) = \\
YUVCONSTANTSBODY(YG, YB, VR, VG, UG, UB);
// TODO(fbarchard): Generate SIMD structures from float matrix.
// BT.601 limited range YUV to RGB reference
// R = (Y - 16) * 1.164 + V * 1.596
// G = (Y - 16) * 1.164 - U * 0.391 - V * 0.813
// B = (Y - 16) * 1.164 + U * 2.018
// KR = 0.299; KB = 0.114
// U and V contributions to R,G,B.
#if defined(LIBYUV_UNLIMITED_DATA) || defined(LIBYUV_UNLIMITED_BT601)
#define UB 129 /* round(2.018 * 64) */
#else
#define UB 128 /* max(128, round(2.018 * 64)) */
#endif
#define UG 25 /* round(0.391 * 64) */
#define VG 52 /* round(0.813 * 64) */
#define VR 102 /* round(1.596 * 64) */
// Y contribution to R,G,B. Scale and bias.
#define YG 18997 /* round(1.164 * 64 * 256 * 256 / 257) */
#define YB -1160 /* 1.164 * 64 * -16 + 64 / 2 */
MAKEYUVCONSTANTS(I601, YG, YB, UB, UG, VG, VR)
现在来分析 HAS_I422TOARGBROW_NEON 这个宏和 TestCpuFlag(kCpuHasNEON)。
HAS_I422TOARGBROW_NEON 宏定义在 row.h 中,由于 Libyuv 没有禁用 NEON,并且 __aarch64__ 被定义,所以 HAS_I422TOARGBROW_NEON 宏编译开关就会打开。
libyuv/row.h
// The following are available on Neon platforms:
#if !defined(LIBYUV_DISABLE_NEON) && \\
(defined(__aarch64__) || defined(__ARM_NEON__) || defined(LIBYUV_NEON))
......
#define HAS_I422TOARGBROW_NEON
......
#endif
TestCpuFlag 这个函数定义在 cpu_id.h 这个头文件。
- __ATOMIC_RELAXED(意味着没有线程间的排序约束) 和 __atomic_load_n 用作原子地加载 cpu_info_ 给 cpu_info 变量赋值,否则就直接把 cpu_info_ 的值赋给 cpu_info。
- 如果 cpu_info 为 0,则调用 InitCpuFlags() 获取值并与入参 test_flag 取与返回,否则直接使用 cpu_info 的值与 test_flag 取与。
SetCpuFlags 将 cpu_info_ 设置为 cpu_flags。 cpu_flags 应该是 kCpuHas 常数的有效组合,其中包括 kCpuInitialized。
libyuv/cpu_id.h
// Detect CPU has SSE2 etc.
// Test_flag parameter should be one of kCpuHas constants above.
// Returns non-zero if instruction set is detected
static __inline int TestCpuFlag(int test_flag)
LIBYUV_API extern int cpu_info_;
#ifdef __ATOMIC_RELAXED
int cpu_info = __atomic_load_n(&cpu_info_, __ATOMIC_RELAXED);
#else
int cpu_info = cpu_info_;
#endif
return (!cpu_info ? InitCpuFlags() : cpu_info) & test_flag;
......
static __inline void SetCpuFlags(int cpu_flags)
LIBYUV_API extern int cpu_info_;
#ifdef __ATOMIC_RELAXED
__atomic_store_n(&cpu_info_, cpu_flags, __ATOMIC_RELAXED);
#else
cpu_info_ = cpu_flags;
#endif
InitCpuFlags 内部实际调用了 MaskCpuFlags(-1)。这里传递 -1 是因为 -1 的二进制形式(补码形式存放)为每个位都为 1(0xFFFFFFFF)。
MaskCpuFlags 内部调用了 GetCpuFlags() 获取 CPU Flag,接着调用 SetCpuFlags(…) 给 cpu_info_ 全局变量赋值。
GetCpuFlags() 内部根据预编译会走 defined(__arm__) || defined(__aarch64__) 这个条件下的代码块,结合注释不难知道对于 aarch64(arm64), /proc/cpuinfo 的功能是不完整的,例如,它没有 NEON 标志。因此对于 aarch64,这里硬编码了 NEON 启用。如果是其他 ARM 版本(例如 armv7a),则调用 ArmCpuCaps 解析 /proc/cpuinfo 内的文本查找是否支持 NEON。
ArmCpuCaps 首先打开 /proc/cpuinfo 文件,如果文件不存在,则假定支持 NEON,这将发生在 Chrome 沙盒 Pepper 或渲染进程。否则按照行去搜索 neon 或 asimd 字段,只要存在就认为 CPU 启用了 NEON 特性。
cpu_id.cc
// cpu_info_ variable for SIMD instruction sets detected.
LIBYUV_API int cpu_info_ = 0;
// Based on libvpx arm_cpudetect.c
// For Arm, but public to allow testing on any CPU
LIBYUV_API SAFEBUFFERS int ArmCpuCaps(const char* cpuinfo_name)
char cpuinfo_line[512];
FILE* f = fopen(cpuinfo_name, "r");
if (!f)
// Assume Neon if /proc/cpuinfo is unavailable.
// This will occur for Chrome sandbox for Pepper or Render process.
return kCpuHasNEON;
while (fgets(cpuinfo_line, sizeof(cpuinfo_line) - 1, f))
if (memcmp(cpuinfo_line, "Features", 8) == 0)
char* p = strstr(cpuinfo_line, " neon");
if (p && (p[5] == ' ' || p[5] == '\\n'))
fclose(f);
return kCpuHasNEON;
// aarch64 uses asimd for Neon.
p = strstr(cpuinfo_line, " asimd");
if (p)
fclose(f);
return kCpuHasNEON;
fclose(f);
return 0;
static SAFEBUFFERS int GetCpuFlags(void)
int cpu_info = 0;
......
#if defined(__arm__) || defined(__aarch64__)
// gcc -mfpu=neon defines __ARM_NEON__
// __ARM_NEON__ generates code that requires Neon. NaCL also requires Neon.
// For Linux, /proc/cpuinfo can be tested but without that assume Neon.
#if defined(__ARM_NEON__) || defined(__native_client__) || !defined(__linux__)
cpu_info = kCpuHasNEON;
// For aarch64(arm64), /proc/cpuinfo's feature is not complete, e.g. no neon
// flag in it.
// So for aarch64, neon enabling is hard coded here.
#endif
#if defined(__aarch64__)
cpu_info = kCpuHasNEON;
#else
// Linux arm parse text file for neon detect.
cpu_info = ArmCpuCaps("/proc/cpuinfo");
#endif
cpu_info |= kCpuHasARM;
#endif // __arm__
cpu_info |= kCpuInitialized;
return cpu_info;
// Note that use of this function is not thread safe.
LIBYUV_API
int MaskCpuFlags(int enable_flags)
int cpu_info = GetCpuFlags() & enable_flags;
SetCpuFlags(cpu_info);
return cpu_info;
LIBYUV_API
int InitCpuFlags(void)
return MaskCpuFlags(-1);
现在是时候转到 I422ToARGBRow_NEON 具体实现了。只搜索代码的话会发现 I422ToARGBRow_NEON 在 row_neon.cc 和 row_neon64.cc 中均有实现。看代码就会发现,它们的使用是被条件编译约束着的,所以按照前面假设 CPU 类型为 arm64-v8a 则一定会调用到 row_neon64.cc 中的实现,row_neon.cc 中的实现预编译条件不满足,代码自然就不会加入。
1. YUVTORGB_SETUP
使用了两条 ld4r 指令加载 kUVCoeff 和 kRGBCoeffBias 中的数据,LD4R 指令表示加载单个四元素结构并复制到四个寄存器的所有通道,也就是 V28 寄存器每个通道的值都是 UB,V29:VR,V30:UG,V31:VG,V24:YG,V25:BB,V26:BG,V27:BR。
2. movi v19.8b, #255
将立即数 255(0xFF)移动到 V19 寄存器的每个 8 位通道。
3. READYUV422
从 YUV 422 数据中读取 8 个 Y、4 个 U 和 4 个 V(每一行上 2 个 Y 共用一组 UV)。
ldr d0, [%[src_y]], #8 加载 8 个 Y 到 d0 寄存器(64 位),并将偏移量加 8(%[src_y] + 8 写入 %[src_y])
ld1 v1.s[0], [%[src_u]], #4 加载 4 个 U 到 V1 寄存器第一个 S 通道,并将偏移量加 4
ld1 v1.s[1], [%[src_v]], #4 加载 4 个 V 到 V1 寄存器第二个 S 通道,并将偏移量加 4
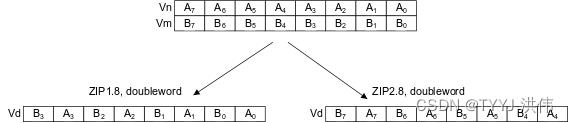
zip1 v0.16b, v0.16b, v0.16b 执行完后 V0 寄存器数据排布变为: Y7 Y7 Y6 Y6 Y5 Y5 Y4 Y4 Y3 Y3 Y2 Y2 Y1 Y1 Y0 Y0
ZIP1 这条指令从两个源 SIMD&FP 寄存器的下半部分读取相邻的向量元素,并将其成对,然后将这两个向量交叉放置到一个向量中,最后将向量写入目标 SIMD&FP 寄存器。
prfm pldl1keep, [%[src_y], 448] 指示内存系统预加载 448 字节 Y 数据到 L1 缓存行上,448 立即数代表字节偏移量(8 的倍数)
PRFM 指令向内存系统发出信号,表明在不久的将来可能会从指定地址访问数据内存。当内存访问发生时,内存系统可以通过采取预期的操作来加速内存访问,例如将包含指定地址的缓存行预加载到一个或多个缓存中。
PLD —— 预取加载
L1 —— 一级缓存
KEEP —— 保留预取或临时预取,在缓存中正常分配
zip1 v1.16b, v1.16b, v1.16b 执行完后 V1 寄存器数据排布变为: V3 V3 V2 V2 V1 V1 V0 V0 U3 U3 U2 U2 U1 U1 U0 U0
prfm pldl1keep, [%[src_u], 128] 指示内存系统预加载 128 字节 U 数据到 L1 缓存行上
prfm pldl1keep, [%[src_v], 128] 指示内存系统预加载 128 字节 V 数据到 L1 缓存行上
4. YUVTORGB
umull2 v3.4s, v0.8h, v24.8h Y(上半部分) * YG -> V3
umull v6.8h, v1.8b, v30.8b U * UG -> V6
umull v0.4s, v0.4h, v24.4h Y(下半部分) * YG -> V0
UMULL、UMULL2 将第一个源 SIMD&FP 寄存器的下半部分或上半部分的每个向量元素与第二个源 SIMD&FP 寄存器的指定向量元素相乘,将结果放入一个向量中,并将该向量写入目标 SIMD&FP 寄存器。目标向量元素的长度是相乘元素长度的两倍。
UMULL 指令从第一个源寄存器的下半部分提取向量元素,而 UMULL2 指令从第一个源寄存器的上半部分提取向量元素。
umlal2 v6.8h, v1.16b, v31.16b U * UG + V * VG -> V6
UMLAL,UMLAL2 该指令将第一个源 SIMD&FP 寄存器的下半部或上半部的向量元素与第二个源 SIMD&FP 寄存器对应的向量元素相乘,并将结果与目标 SIMD&FP 寄存器的向量元素累加。目标向量元素的长度是相乘元素长度的两倍。
UMLAL 指令从第一个源寄存器的下半部分提取向量元素,而 UMLAL2 指令从第一个源寄存器的上半部分提取向量元素。
uqshrn v0.4h, v0.4s, #16 V0 中的 S 通道元素右移 16 位,并将结果饱和为 H 大小,最终写入 V0.4H(V0 下半部分 H 通道)
uqshrn2 v0.8h, v3.4s, #16 V3 中的 S 通道元素右移 16 位,并将结果饱和为 H 大小,最终写入 V0 上半部分 H 通道
UQSHRN,UQSHRN2 读取源 SIMD&FP 寄存器中的每个向量元素,将每个结果右移一个立即数,将每个移位后的结果饱和为原始宽度的一半,将最终结果放入一个向量,并将该向量写入目标 SIMD&FP 寄存器的下半部分或上半部分。这两条指令中的所有值都是无符号整数值,结果被截断了。要获得四舍五入的结果,请使用 UQRSHRN。
UQSHRN 指令将向量写入目标寄存器的下半部分并清除上半部分,而 UQSHRN2 指令将向量写入目标寄存器的上半部分而不影响寄存器的其他位。
umull v4.8h, v1.8b, v28.8b U * UB -> V4
umull2 v5.8h, v1.16b, v29.16b V * VR -> V5
add v17.8h, v0.8h, v26.8h Y * YG + BG -> V17
add v16.8h, v0.8h, v4.8h Y * YG + U * UB -> V16
add v18.8h, v0.8h, v5.8h Y * YG + V * VR -> V18
uqsub v17.8h, v17.8h, v6.8h G: Y * YG + BG - U * UG + V * VG
UQSUB 从第一个源 SIMD&FP 寄存器对应的元素值中减去第二个源 SIMD&FP 寄存器的元素值,将结果放入一个向量中,并将该向量写入目标 SIMD&FP 寄存器。
uqsub v16.8h, v16.8h, v25.8h B: Y * YG + U * UB - BB
uqsub v18.8h, v18.8h, v27.8h R: Y * YG + V * VR - BR
5. RGBTORGB8
uqshrn v17.8b, v17.8h, #6 G 右移 6 位(2^6 = 64),并将结果饱和为 B 大小,最终结果放入 V17 寄存器的下半部分
uqshrn v16.8b, v16.8h, #6 B 右移 6 位,并将结果饱和为 B 大小,最终结果放入 V16 寄存器的下半部分
uqshrn v18.8b, v18.8h, #6 R 右移 6 位,并将结果饱和为 B 大小,最终结果放入 V18 寄存器的下半部分
6. subs %w[width], %w[width], #8
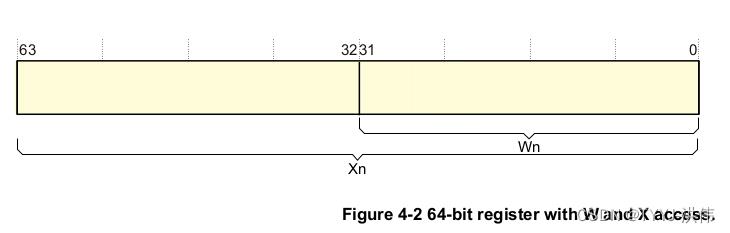
SUBS 指令从一个寄存器值减去一个立即值,并将结果写入目标寄存器。它会根据结果更新条件标志。%w[width] 分配的 W 寄存器(使用 %w[name] 来操作 W 寄存器,也可以对 X 寄存器使用%x[name],但这是默认值)减去 8 并赋值回去。
AArch64 执行状态提供了 31 × 64 位通用寄存器,在任何时候和所有异常级别都可以访问。每个寄存器是 64 位宽的,它们通常被称为寄存器 X0~X30。每个 AArch64 64 位通用寄存器(X0~X30)也有 32 位(W0~W30)形式。
7. st4 v16.8b,v17.8b,v18.8b,v19.8b, [%[dst_argb]], #32
ST4 指令从 4 个寄存器存储多个 4 元素结构。该指令通过交错的方式,将多个四元素结构从四个 SIMD&FP 寄存器存储到内存中。存储每个寄存器的每个元素。
不难知道这里的内存排布为:BGRA BGRA BGRA…BGRA(一共 8 组 BGRA),另外偏移量需要加 32(8 * 4)。
注意:V19 里面的位全都为 1,所以 BGRA 中的 A 都为 0xFF。
++最后由于题目谈及的函数实际为 I420 转 ARGB,因此这里需要按照小端去理解。这是 Libyuv 和其它库的一些区别,其它库通常而言所有转换的格式和内存排列是一致的!++
8. b.gt 1b
B.
如果 subs %w[width], %w[width], #8 减法这条指令更新了零标志位,B 分支指令就不满足大于 0 的条件,就会退出这段内联汇编代码。否则,继续跳到标签 1 处继续处理一行中剩余的像素。
9. YUVTORGB_REGS
这个宏定义列出了 SIMD 需要使用的寄存器。ARMv8 有 32 个 128 位浮点寄存器,标记为 V0-V31。 32 个寄存器用于保存标量浮点指令的浮点操作数以及 NEON 操作的标量和向量操作数。
10. 内联汇编语法
GCC提供了 asm 帮助我们内联汇编,语法如下:
asm [ volatile ] ( code-strings [ : output-list [ : input-list [ : overwrite-list ] ] ] );
volatile 用于指示当添加此关键字时,不允许 GCC 编译器对 assmbly code 进行代码优化。
code-strings:书写我们的汇编指令,用 “” 括起来(就像字符串)。如果要内联多条汇编语句,则需要为每一条指令后添加 \\n\\t 保证格式。
outputlist , inputlist , overwritelist 要用“:”分隔,如果 outputlist、inputlist、overwritelist 有多个值,则用“,”分隔。
output-list:类似于返回值,即我们想在汇编代码里修改的值。
input-list:类似于参数,即我们要在汇编代码里使用的值。
overwrite-list:这是我们要使用的寄存器用“”括起来。
- “cc” 表示内联汇编代码运算过程中,会产生符号变化、数据溢出等问题,这些操作最终会修改标志寄存器
- “memory” 表示汇编代码对输入和输出操作数涉及内存操作
row_neon64.cc
// This module is for GCC Neon armv8 64 bit.
#if !defined(LIBYUV_DISABLE_NEON) && defined(__aarch64__)
......
// v0.8h: Y
// v1.16b: 8U, 8V
// Read 8 Y, 4 U and 4 V from 422
#define READYUV422 \\
"ldr d0, [%[src_y]], #8 \\n" \\
"ld1 v1.s[0], [%[src_u]], #4 \\n" \\
"ld1 v1.s[1], [%[src_v]], #4 \\n" \\
"zip1 v0.16b, v0.16b, v0.16b \\n" \\
"prfm pldl1keep, [%[src_y], 448] \\n" \\
"zip1 v1.16b, v1.16b, v1.16b \\n" \\
"prfm pldl1keep, [%[src_u], 128] \\n" \\
"prfm pldl1keep, [%[src_v], 128] \\n"
......
// UB VR UG VG
// YG BB BG BR
#define YUVTORGB_SETUP \\
"ld4r v28.16b, v29.16b, v30.16b, v31.16b, [%[kUVCoeff]] \\n" \\
"ld4r v24.8h, v25.8h, v26.8h, v27.8h, [%[kRGBCoeffBias]] \\n"
// v16.8h: B
// v17.8h: G
// v18.8h: R
// Convert from YUV to 2.14 fixed point RGB
#define YUVTORGB \\
"umull2 v3.4s, v0.8h, v24.8h \\n" \\
"umull v6.8h, v1.8b, v30.8b \\n" \\
"umull v0.4s, v0.4h, v24.4h \\n" \\
"umlal2 v6.8h, v1.16b, v31.16b \\n" /* DG */ \\
"uqshrn v0.4h, v0.4s, #16 \\n" \\
"uqshrn2 v0.8h, v3.4s, #16 \\n" /* Y */ \\
"umull v4.8h, v1.8b, v28.8b \\n" /* DB */ \\
"umull2 v5.8h, v1.16b, v29.16b \\n" /* DR */ \\
"add v17.8h, v0.8h, v26.8h \\n" /* G */ \\
"add v16.8h, v0.8h, v4.8h \\n" /* B */ \\
"add v18.8h, v0.8h, v5.8h \\n" /* R */ \\
"uqsub v17.8h, v17.8h, v6.8h \\n" /* G */ \\
"uqsub v16.8h, v16.8h, v25.8h \\n" /* B */ \\
"uqsub v18.8h, v18.8h, v27.8h \\n" /* R */
// Convert from 2.14 fixed point RGB To 8 bit RGB
#define RGBTORGB8 \\
"uqshrn v17.8b, v17.8h, #6 \\n" \\
"uqshrn v16.8b, v16.8h, #6 \\n" \\
"uqshrn v18.8b, v18.8h, #6 \\n"
#define YUVTORGB_REGS \\
"v0", "v1", "v3", "v4", "v5", "v6", "v7", "v16", "v17", "v18", "v24", "v25", \\
"v26", "v27", "v28", "v29", "v30", "v31"
......
void I422ToARGBRow_NEON(const uint8_t* src_y,
const uint8_t* src_u,
const uint8_t* src_v,
uint8_t* dst_argb,
const struct YuvConstants* yuvconstants
SIMD指令集总结
SIMD指令集发展历程
1.1 MMX
英特尔在1996年引入了MMX(Multi Media Extensions)多媒体扩展指令集,包括有57条多媒体指令,开创了SIMD(Single Instruction Multiple Data,单指令多数据)指令集之先河,即在一个周期内一个指令可以完成多个数据操作。
MMX寄存器实际上用的就是浮点寄存器(就是原来的ST0、……、ST7)的低64Bit,分别被命名为MM0、MM1、……、MM7,每个寄存器都可以被看作是8个BYTE,4个WORD、2个DWORD或1个QWORD,具体以什么为单位取决于所用的指令。MMX指令可以把这几个数据在一条指令里同时操作,而且相互间各不相干。这对数据密集型的计算(比如图像处理)是个相当大的喜讯,但是因为它实际使用的是浮点寄存器,所以不能和浮点运算同时执行,要执行浮点指令前必须执行一条EMMS指令,通知CPU“我的租期到了,现在该把房子还给你了”。这么一条指令也是要花时钟周期的(可能还绝对不止一个时钟周期),要是频繁的切换MMX状态和浮点状态,会极大降低效率。所以在使用MMX指令集的时候要注意,务必使MMX指令的运算和浮点运算分开来。
如图1,MMX指令可处理8Bit字符型、16bit整型和32bit整型,无法处理浮点型。