TiDB一个大数据实时计算的存储利器
Posted 云台095
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB一个大数据实时计算的存储利器相关的知识,希望对你有一定的参考价值。
目录
TiDB概述
TiDB是由中国PingCAP公司开发的,是一个开源的分布式NewSQL数据库。它最初的设计目标是解决传统关系型数据库的瓶颈和限制,实现高可用、可扩展和高性能的数据存储和处理。
TiDB架构详解
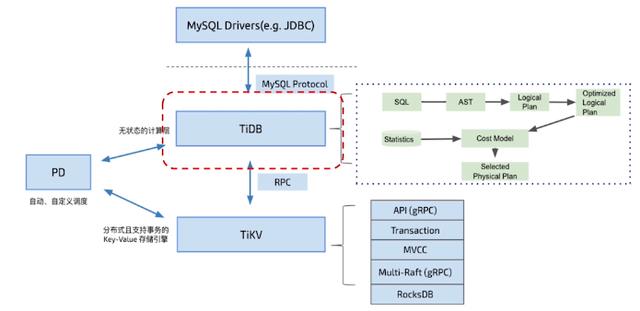
TiDB是一个分布式的NewSQL数据库,其核心架构包括三个组件:TiDB Server、TiKV和PD。
-
TiDB Server:是TiDB的SQL层,提供mysql兼容的协议和接口。它的主要功能是接收和处理客户端的SQL请求,并将这些请求转化为对下层存储引擎TiKV的操作。TiDB Server还包括查询优化器、执行引擎、事务管理等模块,以支持更高效和可靠的数据访问。
-
TiKV:是TiDB的存储引擎,采用分布式、自动分片的方式管理数据。TiKV将数据分散存储在多个节点上,每个节点负责一部分数据的存储和处理。它支持ACID事务、强一致性和高可用性,并提供灵活的配置选项以适应各种工作负载需求。
-
PD:是TiDB的元数据管理组件,负责存储TiKV集群的拓扑信息、负载均衡、故障恢复等任务。PD通过选举算法来选举集群中的Leader节点,保证系统的高可用性和容错性。
总的来说,TiDB的核心架构采用了分布式的方式来存储和管理数据,通过多个组件协同工作来实现数据的高可靠性和高可用性,支持大规模数据处理和高并发访问。
TiDB之TiKV
TiKV是一个分布式的、高可用的Key-Value存储引擎,主要用于存储和处理TiDB的数据。TiKV的原理如下:
-
分布式存储:TiKV采用分布式存储,将数据分散存储在多个节点上。每个节点负责一部分数据的存储和处理。节点之间采用Raft协议进行通信,实现数据的副本同步和容错。同时,TiKV支持水平扩展,可以通过添加新节点来扩展存储能力。
-
数据模型:TiKV采用Key-Value模型,每个Key对应一个Value。Key和Value都是二进制数据,没有固定的格式和结构。用户可以根据需要定义自己的Key和Value结构。
-
强一致性:TiKV采用Raft协议实现数据的副本同步和容错,保证数据的强一致性。在一个Raft组中,每个节点有三种角色:Leader、Follower和Candidate。Leader负责处理客户端的读写请求,并将请求转发给其他节点。Follower和Candidate负责接收Leader发送的请求,并对请求进行确认和同步。
-
事务支持:TiKV支持ACID事务,提供类似于关系数据库的事务语义。TiKV的事务分为两个阶段:预写日志(write-ahead log)和提交。预写日志阶段将事务的写操作记录到日志中,提交阶段将事务的写操作应用到实际数据中。TiKV采用MVCC(多版本并发控制)机制来实现事务的隔离性和一致性。
-
高性能:TiKV通过多种优化手段来提高性能。其中,一种重要的优化是数据的分层存储,将热点数据存储在内存中,将冷数据存储在磁盘中。另外,TiKV还支持多种读写优化策略,如批量读写、异步读写、前缀扫描等。
总的来说,TiKV通过分布式存储、强一致性、事务支持和高性能等特性,实现了一个高可用的、可扩展的Key-Value存储引擎,可以满足大规模数据存储和处理的需求。
TiDB如何部署
关于如何部署TiDB,一般可以分为以下几个步骤:
-
安装TiDB集群:可以通过官方提供的二进制包或Docker镜像来安装TiDB集群。安装过程中需要配置节点信息、端口号、集群拓扑等参数,以及设置相应的用户名和密码。
-
配置TiDB参数:安装完成后,需要对TiDB进行相应的参数配置。其中,包括数据库连接、SQL模式、存储引擎、事务隔离级别等。配置过程中需要根据具体需求进行相应的调整。
-
导入数据:TiDB支持从MySQL、CSV、TiKV等数据源中导入数据。可以使用TiDB提供的工具或第三方工具进行数据导入。
-
进行数据管理和维护:对于已经部署和运行的TiDB集群,需要进行相应的数据管理和维护工作。其中,包括备份和恢复、性能调优、故障排除等。
总的来说,TiDB的部署相对比较简单,而且官方提供了详细的文档和工具,帮助用户进行快速部署和维护。同时,TiDB还提供了丰富的API和插件接口,支持用户自定义开发和扩展。
具体安装流程
安装TiDB需要下载二进制文件或使用Docker镜像,下面分别介绍两种安装方式。
下载二进制文件
-
从官方网站 https://pingcap.com/zh/download/ 下载适用于您的操作系统和 TiDB 版本的二进制文件。
-
解压缩二进制文件,并将其复制到每个节点的 $PATH 目录下。比如:
$ tar -xzf tidb-v4.0.0-linux-amd64.tar.gz $ sudo cp -r tidb-v4.0.0-linux-amd64/bin/* /usr/local/bin/ -
配置TiDB参数。TiDB参数配置文件的位置默认为/etc/tidb/tidb.toml。可以从默认的配置文件/etc/tidb/tidb.toml.example复制并修改成自己需要的配置文件。比如:
$ sudo cp /etc/tidb/tidb.toml.example /etc/tidb/tidb.toml $ sudo vim /etc/tidb/tidb.toml -
启动TiDB。可以使用systemd启动TiDB。比如:
$ sudo systemctl enable tidb.service $ sudo systemctl start tidb.service
使用Docker镜像
-
安装Docker。Docker的安装可以参考官方文档 https://docs.docker.com/engine/install/。
-
下载TiDB镜像。可以在Docker Hub上搜索TiDB并下载。
$ docker pull pingcap/tidb:latest -
启动TiDB容器。比如:
$ docker run -d --name tidb-server -p 4000:4000 pingcap/tidb:latest -
配置TiDB参数。可以将TiDB配置文件挂载到容器中。比如:
$ docker run -d --name tidb-server -p 4000:4000 -v /path/to/tidb.toml:/etc/tidb/tidb.toml pingcap/tidb:latest
更加详细的安装和配置文档可以参考TiDB官方文档 https://docs.pingcap.com/zh/tidb/stable/quick-start-with-tidb#step-1-下载-tidb。
同时,官方文档也提供了更加详细的参数配置、运维、备份等方面的文档,方便用户使用和维护TiDB。
一些配置解析
当您安装 TiDB 后,需要对 TiDB 进行一些基本的配置,其中最重要的是 tidb.toml 配置文件。tidb.toml 配置文件包含了 TiDB 集群的大多数配置参数。以下是 tidb.toml 文件的一些重要配置项。
Server 配置
[server] 配置项定义了 TiDB 服务器的网络、调度和统计信息等参数。
port: TiDB 的监听端口,默认值为 4000。status-port: TiDB 的状态监控端口,默认值为 10080。advertise-address: TiDB 服务器所在主机的 IP 地址,默认为空字符串。当多个 TiDB 实例运行在同一主机上时,需要设置该值以确保它们使用正确的 IP 地址进行通信。socket: TiDB 监听的 Unix 套接字文件路径,如果设置该参数,则会忽略port参数。默认值为空字符串。log-level: TiDB 日志输出的级别,默认值为 info。log-file: TiDB 日志输出到的文件名,默认值为标准输出。slow-query-file: 记录 TiDB 慢查询日志的文件名,默认值为 tidb-slow.log。max-index-length: TiDB 索引键的最大长度,默认为 3072 字节。
Performance 配置
[performance] 配置项定义了 TiDB 在处理大量请求时的行为和策略。
max-procs: TiDB 使用的最大 CPU 数量,默认值为 0,表示使用所有可用的 CPU。max-memory: TiDB 使用的最大内存数量,默认值为 0,表示使用所有可用的内存。如果设置了该值,当 TiDB 的内存使用超过了该阈值时,将会触发 Out-Of-Memory (OOM) 错误。stats-lease: TiDB 统计信息的租约时长,单位为秒,默认值为 3。stmt-count-limit: TiDB 限制在内存中缓存的语句数,默认值为 5000。当 TiDB 的内存使用超过了该阈值时,将会删除较早的查询计划缓存。
Log 配置
[log] 配置项定义了 TiDB 日志记录的相关参数。
level: TiDB 日志输出的级别,默认值为 info。format: TiDB 日志输出的格式,默认值为 text。disable-timestamp: 是否禁用 TiDB 日志输出的时间戳,默认值为 false。file: TiDB 日志输出到的文件名,默认为空字符串。如果设置该值,则会忽略level、format和disable-timestamp参数。rotation-time: TiDB 日志轮换的时间间隔,默认值为 86400 秒(1 天)。rotation-size: TiDB 日志轮换的文件大小,默认值为 100 MiB。
PD 配置
[pd] 配置项定义了 TiDB 集群
Storm实战_构建大数据实时计算
Storm实战 构建大数据实时计算
ZeroMQ
sudo yum install maven
1简介
使用场景
- 实时分析
- 在线机器学习
- 持续计算
- 分布式RPC
- ETL
保证每个消息都得到处理,速度快每个节点每秒百万次消息.
实体
- 工作进程:每台机器上多个
- exector:每个进程多个
- 任务:每个exector多个任务
spot bolt
storm 0.7版本引入事物拓扑解决,严格要求每个事物仅处理一次.
- 多语言协议,每个tuple处理时需要进行JSON编解码.吞吐量有影响
- ZeroMQ作为底层消息对列,消息快速处理.
ZeroMQ是一个为可伸缩的分布式或并发应用程序设计的高性能异步消息库。但是与面向消息的中间件不同,ZeroMQ的运行不需要专门的消息代理(message broker)。该库设计成常见的套接字风格的API。ZeroMQ是由iMatix公司和大量贡献者组成的社区共同开发的。ZeroQ通过许多第三方软件支持大部分流行的编程语言,从Java和Python到Erlang和Haskell。
- 支持动态增加节点,但是现有的任务不会自动负载均衡.
- 图形化监控
中间状态查询与存储
- 处理流的结果,无法直接取得.导入MySQL或HBase中.
- 计算逻辑类的快照,便于错误恢复.
但是有些业务需要保存中间状态,利用MySQL实时存储中间状态.崩溃从最近状态恢复.将数据源存储到HBase中,恢复后取出未处理的结果.利用HBase支持前后定位.
2Storm初体验
节点类型
- 主控节点master
Nimbus的后台程序,分发代码,分配任务,监控状态. - 工作节点 worker
运行一个Supervisoer后台程序,监听Nimbus分配的任务.启动或停止进程.
一个Topology由分布在不同工作节点上的多个工作进程组成.
Nimbus和Supervisoer间协调通过zookeeper
Nimbus和Supervisoer是快速失败和无状态.结束后,要么在zookeeper要么在硬盘上,拥有不可思议的稳定性.
- 主控节点master
3构建Topology
- Topology
Topology不会结束,MR会结束.
Topology时Thrift(跨语言框架). - 流
一个消息流就是一个没有边界的tuple抽象. sqout
- 方法
nextTuple()发射一个tuple到topology中.nextTuple()不能被阻塞,UI个exector调用所有消息源的spout方法. ack()tuple成功处理fail()tubples处理失败.
只对可靠的spout调用ack和fail
- 方法
Bolts
所有的消息处理逻辑.- 过滤
- 聚合
查询数据库
OutputFieldsDeclarer.declareStream()定义stream.OutputCollector.emit()选择发射的Stream- execute处理tuple.
- OutputCollector发射tuple.为每个处理的tuple调用ack方法.通知storm该tuple处理完毕.
Stream Grouping
Stream Grouping 定义一个stream如何分配bolts上面的多个task.
7种类型的Stream Grouping
- shuffle 随机,每个bolt数目大致相同
- fields 字段分组
- all 广播发送,每个tuple所有的bolts收到
- global 全局分组,tupe分配到id值最低的task
- non 随机,放到bolt的同一个exector执行.
- direct 直接,特备.指定接受者的task
local or shuffle bolt有1个或多个task在同一个进程中,随机分.否则和shuffle grouping 行为一致.
可靠性
tasks
workers
一个topology有多个worker(进程)
- 每个worker是一个物理JVM
- 并行度300的topology 50个进程的话.每个进程处理6个tasks.均分.
4Topology并行度
一台机器为多个topology运行多个进程.
一个进程属于一个特定的topology
一个进程为topology启动多个exector.
每个exector会为**特定**spout/bolt 运行一个或多个任务.
默认每个exector执行一个任务.
设置每个spout/bolt启动几个executor.默认启动1个exector.
配置任务数,每个bolt/spout执行多少个任务.
- 动态增加或减少exector数或进程数.不需要重启集群或者topology
5消息的可靠处理
确保spout发出的每个消息都被完整处理.
tuple tree超时值默认30s.
读取消息,消息设置为 “pending”状态.只有得到客户端的应答后,ack fail调用后才会从队列中真正删除.
锚定:指定的节点增加了一个新节点.
多重锚定 ???
P79-81
高效实现tupletree
- acker跟踪DAG中每个消息,可以设置并行度.通过参数设置,大量消息时应提高并行度
- acker可以有多个.使用哈希算法,确定spout id 对于的acker.
- 20字节跟踪一棵树.
6一致性任务
保证tuple只被处理一次.
一致性事物组件
- 简单设计1:强顺序流
简单设计2”强顺序batch流
使用CoordinateBolt7DRPC
8Trident
以上是关于TiDB一个大数据实时计算的存储利器的主要内容,如果未能解决你的问题,请参考以下文章