大型网站数据库系统,怎么连接那么多并发数量的?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型网站数据库系统,怎么连接那么多并发数量的?相关的知识,希望对你有一定的参考价值。
大型网站数据库系统,怎么连接那么多并发数量的?比如腾讯类的大互联网公司,或者是51一类的博客,系统怎么做到同时并发连接数量,他们使用的是什么数据库和技术呢?
。因为我刚刚学习数据库,并发连接数量只支持几百个。
在连接数据库的时候可以优化,使用连接池。主要就是不要频繁地创建,销毁连接。这是很费时的一个操作。因此,使用连接池来代替普通的建立连接操作,能提高并发度。
使用缓存技术,并不是每次都需要去数据库里面查询的,我们其实可以把前一次的查询结果放在内存里,如果下一次用户来查询相同的内容,直接内存返回即可,不需要再次查询。这样可以大大降低查询频率。
使用分布式技术,将数据库分布在多台服务器上,同时也将用户分区(如根据用户ID的哈希值分区),不同的服务器负责不同用户群,这样就能大大减少单台服务器的负载,使得整体的吞吐量提高。这几样技术可以同时使用,你的并发数量将获得非常大的提高。
大型数据库介绍:
1 SQL Server
概括地说,SQL Server具有如下特点:
A客户/服务器体系结构;
B图形化的用户界面,使系统的管理更加直观和简单。
C丰富的编程接口,为用户进行应用程序设计提拱了更大的选择余地。
D与Windows NT操作系统的有机集成,多线程体系结构设计,提供了系统对用户并发访问的速度。
E对Web技术的支持,使用户能够很容易地将数据库中的数据发布到网上。
F价格上的优势。与其他一些大型数据库系统。如Oracle、Sybase等相比,SQL Server的价格非常便宜。
G作为微软在Windows系列平台上开发的数据库,SQL Server一经推出就以其易用性和兼容性得到了很多用户的青睐,是Windows环境商业应用的首选数据库。
2 Oracle
甲骨文公司(Oracle)的产品,可以运行于很多操作系统之上(包括Windows),是大型企业级数据库。Oracle它是以高级结构化查询语言为基础的大型关系型数据库,是目前最流行的客户/服务器体系机构的数据库之一。提供对Internet全面支持的管理平台和系统集成工具,完全支持所有的工业标准,占有相当大的市场份额。因其专业性较强,操作繁杂,不易上手,价格较高,一般作为UNIX下的应用较多,适于大型网站选用。
3 DB2
IBM公司的产品,可以运行于很多操作系统上(包括Windows),是大型企业级数据库。DB2具有很好的并行性。把数据库管理扩充到了并行的、多节点的环境。其操作简单、兼容性好,广泛应用于大型企业。
DB2是内嵌于IBM的AS/400系统上的数据库管理系统,直接由硬件支持。它支持标准的SQL语言,具有与异种数据库相连的GATEWAY。因此他具有速度快、可考性好的优点。但是,只有硬件平台选择了IBM的AS/400,才能选择使用DB2数据库管理系统。
4 mysql
MySQL是当今UNIX或Linux类服务器上广泛使用的Web数据库系统。也可以运行于Windows平台。它是一个多用户、多线程、跨平台的SQL数据库系统,同时是具有客户/服务器体系结构的分布式数据库管理系统,属自由数据库系统,开放源代码数据库产品。
MySQL于1996年诞生于瑞典的TcX公司。其设计思想为快捷、高效、实用。虽然它对ANSI SQL标准的支持并不完善,但支持所有常用的内容,完全可以胜任一般Web数据库的工作。由于它不支持事务处理,MySQL的速度比一些商业数据库块2-3倍,并且MySQL还针对很多操作平台做了优化,完全支持多CPU系统的多线程方式。
在编程方面,MySQL也提供了C、C++、Java、Perl、Python和TCL等API接口,而且有MyODBC接口,任何可以使用ODBC接口的语言都可以使用它。
MySQL是中小企业网站Linux平台的首选。MySQL在Linux下应用较多,Linux+MySQL+php是基于Linux的最佳组合。由于属开放源代码自由软件,性价比较高,是中小企业网站、个人网站不错的选择。
现象
Sysbench对MySQL进行压测, 并发数过大(>5k)时, Sysbench建立连接的步骤会超时.
猜想
猜想: 直觉上这很简单, Sysbench每建立一个连接, 都要消耗一个线程, 资源消耗过大导致超时.
验证: 修改Sysbench源码, 调大超时时间, 仍然会发生超时.
检查环境
猜想失败, 回到常规的环境检查:
MySQL error log 未见异常.
syslog 未见异常.
tcpdump 观察网络包未见异常, 连接能完成正常的三次握手; 只观察到在出问题的连接中, 有一部分的TCP握手的第一个SYN包发生了重传, 另一部分没有发生重传.
自己写一个简单的并发发生器, 替换sysbench, 可重现场景. 排除sysbench的影响
猜想2
怀疑 MySQL 在应用层因为某种原因, 没有发送握手包, 比如卡在某一个流程上:
检查MySQL堆栈未见异常, 仿佛MySQL在应用层没有看到新连接进入.
通过strace检查MySQL, 发现 accept() 调用确实没有感知到新连接.
怀疑是OS的原因, Google之, 得到参考文档: A TCP “stuck” connection mystery【http://www.evanjones.ca/tcp-stuck-connection-mystery.html】
分析
参考文档中的现象跟目前的状况很类似, 简述如下:
正常的TCP连接流程:
Client 向 Server 发起连接请求, 发送SYN.
Server 预留连接资源, 向 Client 回复SYN-ACK.
Client 向 Server 回复ACK.
Server 收到 ACK, 连接建立.
在业务层上, Client和Server间进行通讯.
当发生类似SYN-flood的现象时, TCP连接的流程会使用SYN-cookie, 变为:
Client 向 Server 发起连接请求, 发送SYN.
Server 不预留连接资源, 向 Client 回复SYN-ACK, 包中附带有签名A.
Client 向 Server 回复ACK, 附带 f(签名A) (对签名进行运算的结果).
Server 验证签名, 分配连接资源, 连接建立.
在业务层上, Client和Server间进行通讯.
当启用SYN-cookie时, 第3步的ACK包因为 某种原因 丢失, 那么:
从Client的视角, 连接已经建立.
从Server的视角, 连接并不存在, 既没有建立, 也没有”即将建立” (若不启用SYN-cookie, Server会知道某个连接”即将建立”)
发生这种情况时:
若业务层的第一个包应是从 Client 发往 Server, 则会进行重发或抛出连接错误
若业务层的第一个包应是从 Server 发往 Client的, Server不会发出第一个包. MySQL的故障就属于这种情况.
TCP握手的第三步ACK包为什么丢失
参考文档中, 对于TCP握手的第三步ACK包的丢失原因, 描述为:
Some of these packets get lost because some buffer somewhere overflows.我们可以通过Systemtap进一步探究原因. 通过一个简单的脚本:
probe kernel.function("cookie_v4_check").return
source_port = @cast($skb->head + $skb->transport_header, "struct tcphdr")->source
printf("source=%d, return=%d\\n",readable_port(source_port), $return)
function readable_port(port)
return (port & ((1<<9)-1)) << 8 | (port >> 8)
观察结果, 可以确认cookie_v4_check (syn cookie机制进行包签名检查的函数)会返回 NULL(0). 即验证是由于syn cookie验证不通过, 导致TCP握手的第三步ACK包不被接受.
之后就是对其中不同条件进行观察, 看看是哪个条件不通过. 最终原因是accept队列满(sk_acceptq_is_full):
static inline bool sk_acceptq_is_full(const struct sock *sk) return sk->sk_ack_backlog > sk- >sk_max_ack_backlog;恢复故障与日志的正关联
在故障处理的一开始, 我们就检查了syslog, 结论是未见异常.
当整个故障分析完成, 得知了故障与syn cookie有关, 回头看syslog, 里面是有相关的信息, 只是和故障发生的时间不匹配, 没有正关联, 因此被忽略.
检查Linux源码:
if (!queue->synflood_warned &&
sysctl_tcp_syncookies != 2 &&
xchg(&queue->synflood_warned, 1) == 0)
pr_info("%s: Possible SYN flooding on port %d. %s.
Check SNMP counters.\\n",
proto, ntohs(tcp_hdr(skb)->dest), msg);
可以看到日志受到了抑制, 因此日志与故障的正关联被破坏.
粗看源码, 每个listen socket只会发送一次告警日志, 要获得日志与故障的正关联, 必须每次测试重启MySQL.
解决方案
这种故障一旦形成, 难以检测; 系统日志中只会出现一次, 在下次重启MySQL之前就不会再出现了; Client如果没有合适的超时机制, 万劫不复.
解决方案:
1. 修改MySQL的协议, 让Client先发握手包. 显然不现实.
2. 关闭syn_cookie. 有安全的人又要跳出来了.
3. 或者调高syn_cookie的触发条件 (syn backlog长度). 降低系统对syn flood的敏感度, 使之可以容忍业务的syn波动.
有多个系统参数混合影响syn backlog长度, 参看【http://blog.dubbelboer.com/2012/04/09/syn-cookies.html】
下图为精华总结
请点击输入图片描述
大型网站技术架构演化
一、大型网站软件系统的特点
1.高并发、大流量
a.什么是高并发?
高并发是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理多个请求。
b.高并发的衡量指标有哪些?
(1)响应时间:系统对请求做出响应。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
(2)吞吐量:单位时间内处理的请求数量。
(3)QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的不那么明显。
(4)并发用户数:同时承载正常使用系统功能的用户数量。例如一个通讯系统,在线量一定程度上代表系统的并发用户数,比如腾讯QQ。
c.什么是大流量
大流量这个词,顾名思义表示很多流量,这个很多可以用一千万,一亿或者百亿等来衡量。
以流量来说,这个词有比较多的含义,如:
(1)它可以表示手机无线网数据;
(2)网店或网站的访问量;
(3)流体通过量,如水流量等;
在这里主要指网站的流量(包含网站访问量)。
d.那么网站流量指标有哪些呢
主要指标包括:
(1)独立访问者数量;
(2)重复访问者数量;
(3)页面浏览数;
(4)每个访问者的页面浏览数;
(5)用户在网站的停留时间;
(6)用户来源网站(又叫”引导网站”);
(7)用户所使用的搜索引擎及其关键字;
2.高可用:系统需要不间断提供服务
a.什么是高可用
高可用是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供正常服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,系统的年停机时间为8.76个小时。
b.如何保障系统的高可用
我们都知道,单点是系统高可用的大敌,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点挂了服务会受影响,如果有冗余备份,挂了还有其它backup能够顶上。
那么什么是单点呢?
你可以理解为所有的服务都在一个服务器上。
为什么要避免单点?
假定所有的服务在一个服务器上,如果该服务器因为某种原因挂掉了,那么所有的服务都会收到影响,从而会增长系统不能提供正常服务的时间。
3.海量数据(又称“大数据”)
什么是是海量数据?海量数据又称大数据。对于大数据,研究机构给出了这样的定义:大数据是需要新处理模式才能具有更强的决策力、洞察力和流程化能力的海量、高增长率和多样化的信息资产。
从技术上看,大数据与云计算的关系就像一昧硬币的正反面。大数据必然无法用单台计算机进行处理,必须采用分布式架构。其特色在于可对海量数据进行分布式数据挖掘,但必须依托云计算的分布式处理、分布式数据库以及云存储、虚拟化技术。
大数据的特点
(1)数据体量大,从TB级跃升到PB级别。
(2)数据类型繁多,比如网络日志、视频、图片、地理位置等。
(3)处理速度快。
(4)数据价值大。
4.用户分布广泛,网络情况复杂
许多大型互联网都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别。在国内,还有各个运营商网络互通难的问题。
以在我老家的时候,联通的网络不好,移动的网络好,导致使用联通的用户使用软件受制于网络信号差而无法使用。
5.安全环境恶劣
由于互联网的开放性,使得互联网站更容易受到攻击,大型网站几乎每天都会被黑客攻击。以GitHub为例,无时无刻不在遭受到攻击。
6.需求快速变更,发布频繁
和传统软件的版本发布频率不一样,互联网产品为了快速适应市场,满足用户需求,其产品发布频率是极高的。
7.渐进式发展:几乎所有的大网站都是从一个小网站开始的
以最早期的淘宝来说,也是从单体应用来的。据说早期的架构是Linux+Apache+MySQL+PHP(LAMP)。
FaceBook是伯克扎克同学在哈佛大学的宿舍里开发的;Google的第一台服务器部署在斯坦福大学的实验室;阿里巴巴则是在马云家的客厅里诞生。
好的互联网产品都是慢慢运营出来的,不是一开始就开发好的,这也正好与网站架构的发展演化过程对应。
二、大型网站架构演化发展历程
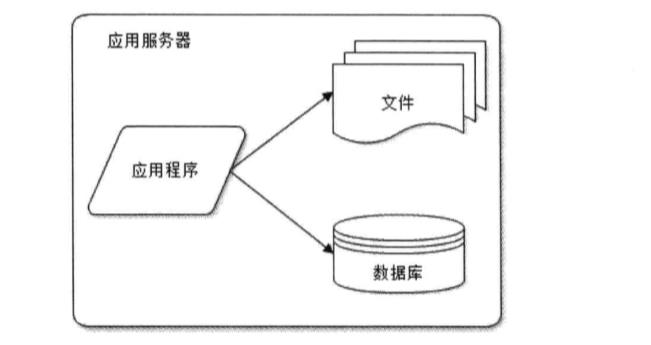
1.初始阶段的网络架构:应用程序、数据库、文件等所有资源都在一台服务器上(单体应用)
2.应用服务和数据库分离:网站使用三台服务器:应用服务器、文件服务器、数据库服务器
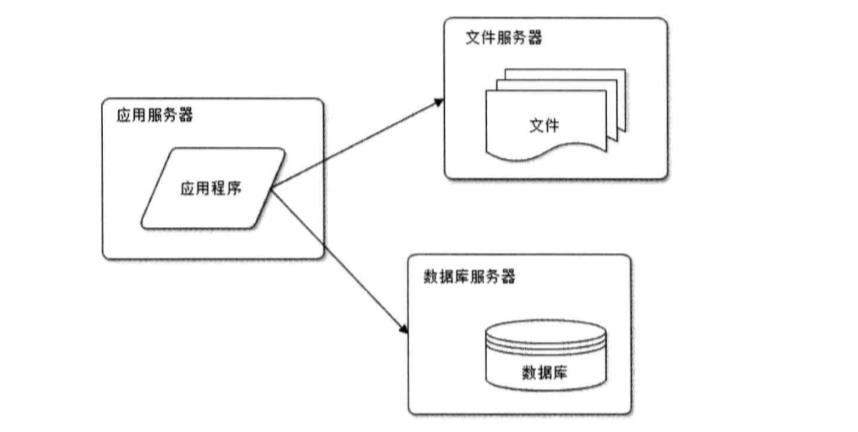
一般情况下有这么几种形式?
(1)nginx+tomcat+ftp+mysql/oracle;
(2)nginx+tomcat+vsftp+mysql/oracle;
(3)apache+tomcat+ftp+mysql/oracle;
(4)nginx+tomcat;
(5)docker容器实践思路(又称容器化);
当然了,上述列出的仅仅是冰山一角,有部分公司拥有自己研发的DB或者应用服务器。
3.使用缓存改善网站性能:使用缓存后数据库访问压力得到有效缓解
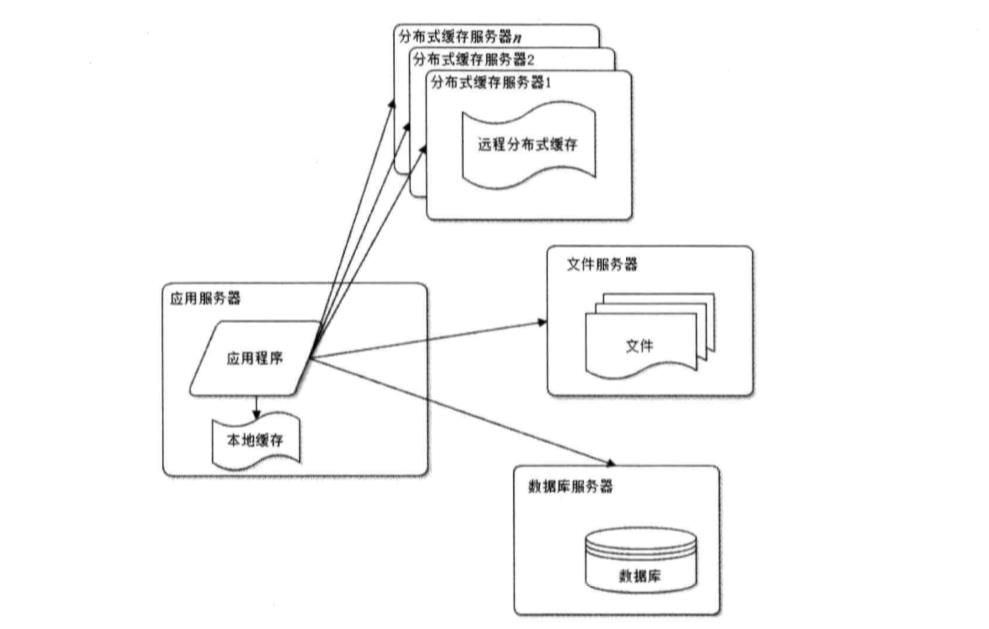
a.那么在什么样的情况应该使用缓存?
(1)经常变化的数据,但是不需要立刻进行持久化的;
(2)经常被大量读取,很少进行更新操作;
(3)大量的数据库IO操作;
(4)通用的页面,如JS、CSS、图片等;
(5) 统计和计算需要暂存的信息,需要加快计算的;
b.Java常用的缓存框架有哪些呢?
一般情况下,用Redis或者Memcache,当然了,有的时候也会用ehcache,关于Java常用的缓存框架代码示例和介绍可参考该篇文章:https://www.cnblogs.com/chinway/p/5534636.html
4.使用服务器集群改善网站的并发处理能力:通过负载均衡调度器将请求分配到集群中的服务器上
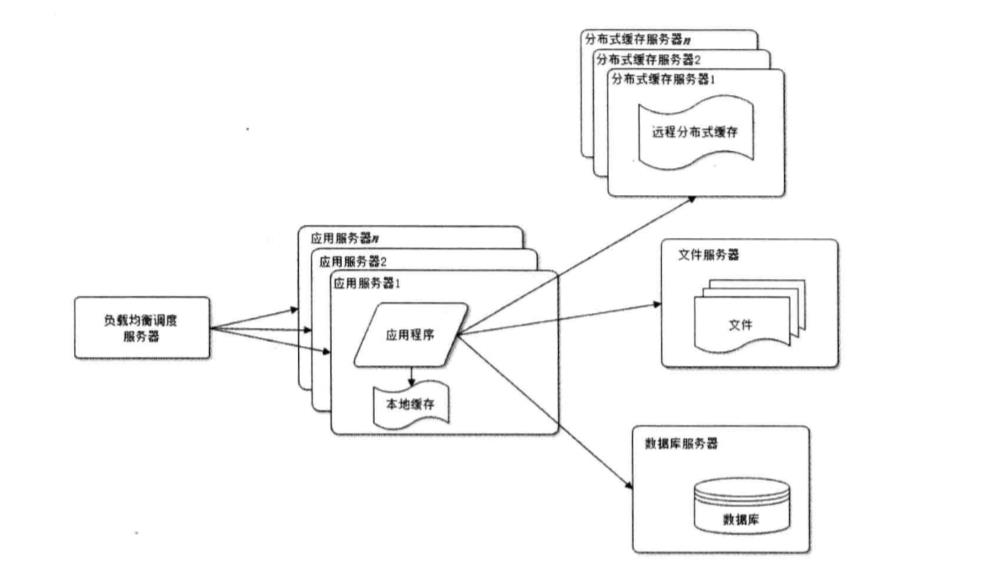
这种方式又可以称作“中心化”,所有的请求全部经过Nginx,由Nginx分发请求到不同的应用服务器上面(根据权重进行分配)。
5.数据库读写分离:应用服务器在写数据的时候访问主数据库,主数据通过主从复制机制将数据更新同步到从数据库,这样当服务器读数据的时候就可以通过从数据库了
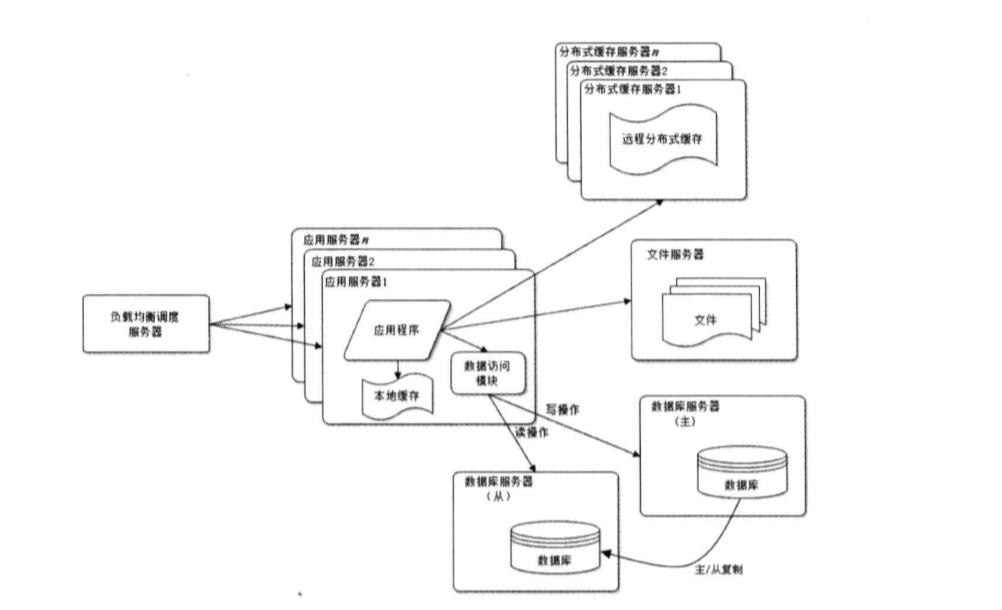
6.使用反向代理和CDN加速网络响应
关于CDN可以参考我的这篇文章:谈谈CDN
不过觉得还是要贴一下图,这样会有一个感性的认识。
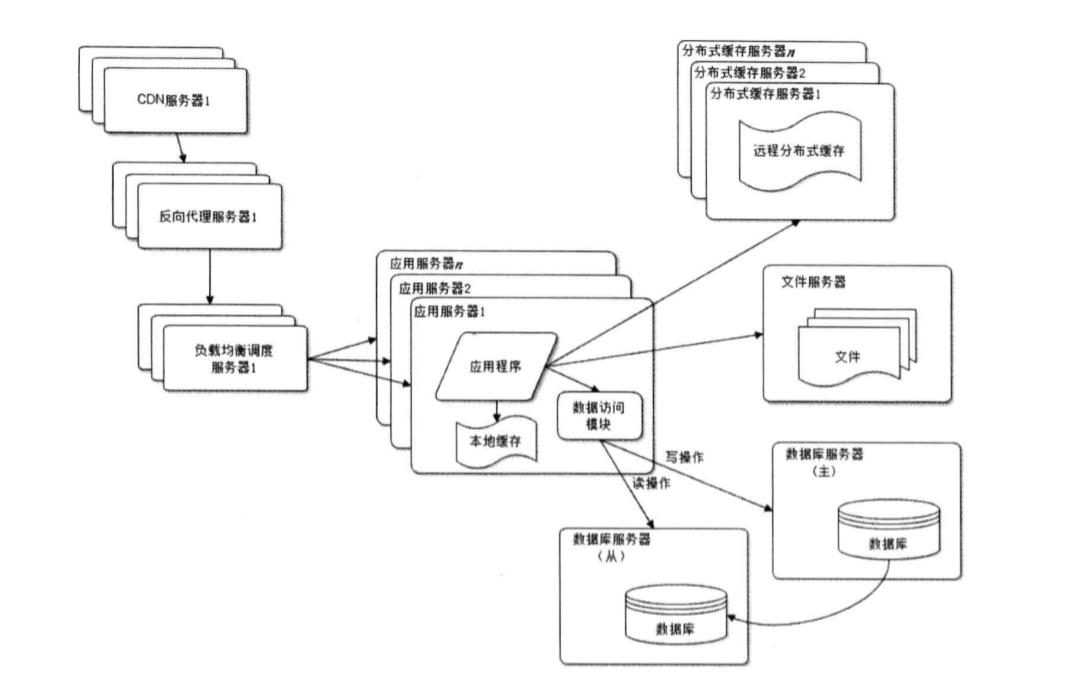
什么是反向代理呢?
反向代理是指以代理服务器来接收internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
7.使用分布式文件系统和分布式数据库系统
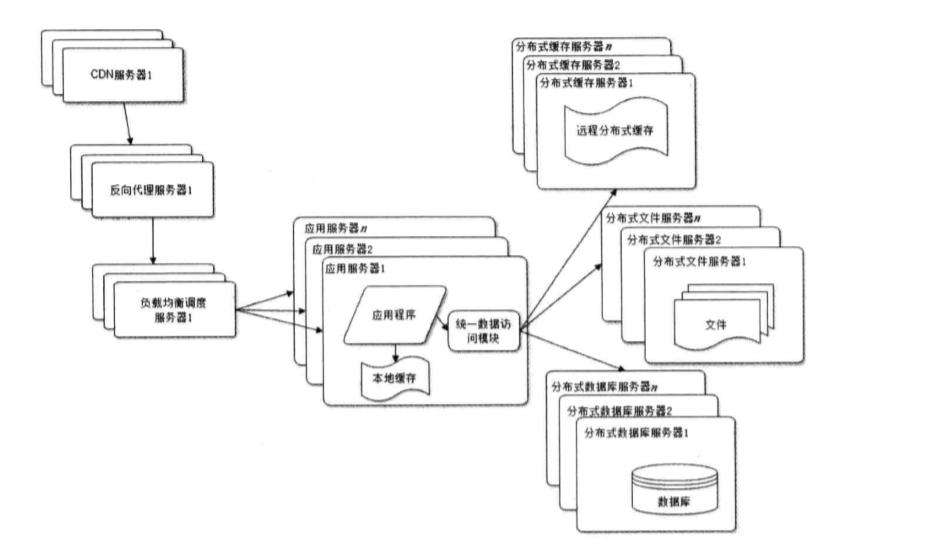
分布式文件系统有哪些?
主要有MFS、Ceph、GlusterFS、Lustre等
关于它们的区别可参考:
分布式文件系统MFS、Ceph、GlusterFS、Lustre的对比
8.使用NOSQL和搜索引擎
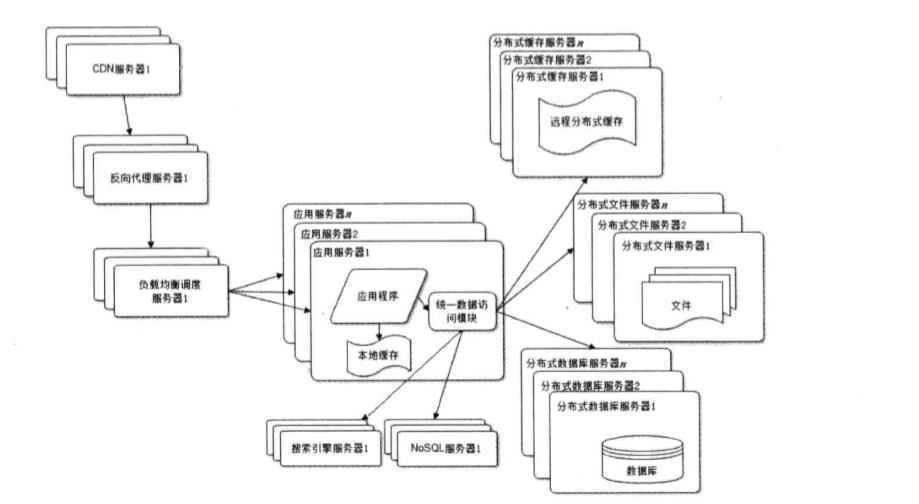
应用比较多的NoSQL,比如Memcache、Redis、MongoDB等。
搜索引擎,以solr和elasticsearch比较多。
9.业务拆分
关于业务拆分可参考我的这篇博文业务拆分的思考
10.分布式服务
可以去看看分布式服务架构这本书或是去看看国外相关专业人士的论文或文章。
分布式服务架构:原理、设计与实战电子书下载地址为:https://pan.baidu.com/s/1hK3vlIHX0SgbD4NNKx_zTg
三、大型网站演化的价值观
(1)大型网站架构核心价值是随网站所需灵活应付;
(2)驱动网站技术发展的主要力量是网站发展业务;
大型网站的核心价值不是从无到有二搭建一个大型网站,而是能够伴随小型网站业务逐步发展,慢慢演化成一个大型网站,网站的架构选择尽量满足网站用户增加需求。
四、网站架构设计误区
误区如下所示:
(1)一昧追随大公司方案;
(2)为了技术而技术;
(3)企图用技术解决所有问题;
参考资料如下:
什么是高并发:https://blog.csdn.net/DreamWeaver_zhou/article/details/78587580
什么是高可用:http://www.cnblogs.com/shizhiyi/p/7750530.html
什么是海量数据?它具有哪些特征?:http://www.znjj.tv/news/3322.html
在什么情况使用Java缓存:https://flychao88.iteye.com/blog/1532335
《大型网站技术架构:核心原理与案例分析》第一章概述第一节大型网站架构演化
以上是关于大型网站数据库系统,怎么连接那么多并发数量的?的主要内容,如果未能解决你的问题,请参考以下文章