开源词袋模型DBow3原理&源码
Posted tszs_song
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源词袋模型DBow3原理&源码相关的知识,希望对你有一定的参考价值。
前人摘树,后人乘凉。
源码在github有CMakeLists,代码下下来可以直接编译。
泡泡机器人有个很详细的分析,结合浅谈回环检测中的词袋模型,配合高翔的回环检测应用,基本上就可以串起来了。
tf-idf的概念,表达方式不唯一,这里的定义是这样:
tf表示词频,这个单词在图像中出现的次数/图像单词总量
idf表示单词在整个训练语料库中的常见程度:idf=log(N/Ni),N是训练语料库中的图片总数,Ni是训练语料库中包含这个单词的图像数
由于Ni<=N,idf>=0,当Ni=N时,idf取最小值0(如果一个单词在每个语料库里都出现了,这个单词太过常见可以忽略)
视觉字典生成以后idf就固定了,检索数据库时的权重用tf*idf计算。
个人理解DBow3里单词(word Id)对应的权值就是idf,检索入口(Entry Id)处的权值是tf*idf。
demo的使用:./demo_gernal orb image1 image2 image3 image4
会在执行目录下生成用输入的4张图提特征的voc字典,并以这四张图为检索入口,生成db检索库,db文件里包含字典,所以有了db就不用voc了。
字典长这样:
1 vocabulary: 2 k: 9 //聚类中心数 3 L: 3 //层数 4 scoringType: 0 5 weightingType: 0 6 nodes: 7 - { nodeId:19, parentId:10, weight:2.8768207245178085e-01, 8 descriptor:dbw3 0 32 124 169 185 96 221 205 85 157 235 189 172 8 159 181 72 50 137 222 236 88 26 107 250 49 251 221 21 127 210 106 198 42 } 9 - { nodeId:20, parentId:10, weight:1.3862943611198906e+00, 10 descriptor:dbw3 0 32 120 164 24 104 249 61 80 95 115 27 172 24 31 147 64 248 145 152 76 56 26 111 82 23 219 223 17 125 226 200 202 42 } 11 - { nodeId:21, parentId:10, weight:0., 12 descriptor:dbw3 0 32 124 165 248 102 209 109 83 25 99 173 173 8 115 241 72 50 16 222 68 56 26 114 248 2 255 205 37 121 226 234 198 34 } 13 - { nodeId:22, parentId:10, weight:0., 14 descriptor:dbw3 0 32 36 161 252 81 224 233 97 139 235 53 108 40 151 199 204 26 3 158 110 24 18 248 234 65 205 152 53 117 194 200 198 162 } 15 - { nodeId:23, parentId:10, weight:1.3862943611198906e+00, 16 descriptor:dbw3 0 32 76 140 56 218 221 253 113 218 95 53 44 24 24 211 106 116 81 154 18 24 18 26 122 245 95 29 17 109 146 137 212 106 } 17 words: 18 - { wordId:0, nodeId:19 } 19 - { wordId:1, nodeId:20 } 20 - { wordId:2, nodeId:21 } 21 - { wordId:3, nodeId:22 } 22 - { wordId:4, nodeId:23 } 23 - { wordId:5, nodeId:24 }
是对聚类生成的树的描述,树上的每一个点都是node,只有叶子结点才是word,每张图进来提取特征,利用descriptor算特征距离,最终落到叶子上(单词),所有特征的单词构成该图片的词向量。
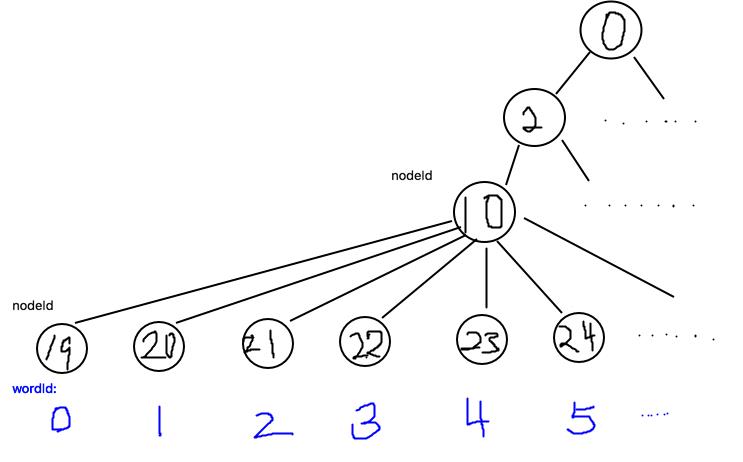
检索入口描述:
1 database: 2 nEntries: 4 3 usingDI: 0 4 diLevels: 0 5 invertedIndex: 6 - //(wordId:0) 7 - { imageId:1, weight:1.6807896319101980e-03 } 8 - { imageId:2, weight:3.2497152852064880e-03 } 9 - { imageId:3, weight:3.6665308718065778e-03 } 10 - //(wordId:1) 11 - { imageId:1, weight:4.0497295661974788e-03 } 12 - //(wordId:2) 13 [] 14 - 15 [] 16 - 17 - { imageId:2, weight:3.9149658655580431e-03 } 18 - 19 - { imageId:3, weight:4.4171079458813099e-03 } 20 - 21 - { imageId:1, weight:2.0248647830987394e-03 } 22 - { imageId:3, weight:4.4171079458813099e-03 }
检索入口:

根据voc字典里的描述,word id 2对应node id 21, 而node id 21对应的权值为0,也就是说word 2太普通了,在用来生成视觉词汇表的4张图里都出现了(参考中文文章里的“的”、“在”、“和”等常见词),不具有代表性, 于是根本就没有对应入口id,这是合理的。
开源出来的代码不是对相同word的入口进行加1投票,而是直接计算单词对应的所有EntryId分数,最后排序取前n个。分数可以有L1 L2 KL等几种计算方式
queryL1,C++不熟看了半天,用到map函数,注释:
1 void Database::queryL1(const BowVector &vec, QueryResults &ret, int max_results, int max_id) const 3 { 4 BowVector::const_iterator vit; 5 6 std::map<EntryId, double> pairs; 7 std::map<EntryId, double>::iterator pit; 8 9 for(vit = vec.begin(); vit != vec.end(); ++vit) 10 { 11 const WordId word_id = vit->first; 12 const WordValue& qvalue = vit->second; 13 14 const IFRow& row = m_ifile[word_id]; 15 16 // IFRows are sorted in ascending entry_id order 18 for(auto rit = row.begin(); rit != row.end(); ++rit) 19 { 20 const EntryId entry_id = rit->entry_id; 21 const WordValue& dvalue = rit->word_weight; 22 23 if((int)entry_id < max_id || max_id == -1) 24 { 25 double value = fabs(qvalue - dvalue) - fabs(qvalue) - fabs(dvalue); 26 //pairs是一个map,low_bound返回首个不小于entry_id的迭代器,因此如果map里有这个entry_id, pit指向它,否则指向pairs.end() 27 pit = pairs.lower_bound(entry_id); //因为在db库里entry_id是按顺序存的,所以可以这样查找 28 if(pit != pairs.end() && !(pairs.key_comp()(entry_id, pit->first))) 29 { 30 pit->second += value; //如果已经有entry_id,累加和 31 } 32 else 33 { //如果没有,插入此id 34 pairs.insert(pit, std::map<EntryId, double>::value_type(entry_id, value)); 35 } 36 } 38 } // for each inverted row 39 } // for each query word 40 41 // move to vector 42 ret.reserve(pairs.size()); 43 for(pit = pairs.begin(); pit != pairs.end(); ++pit) 44 { 45 ret.push_back(Result(pit->first, pit->second)); 46 } 47 48 // resulting "scores" are now in [-2 best .. 0 worst] 50 // sort vector in ascending order of score 51 std::sort(ret.begin(), ret.end()); 52 // (ret is inverted now --the lower the better--) 54 // cut vector 55 if(max_results > 0 && (int)ret.size() > max_results) 56 ret.resize(max_results); 57 58 // complete and scale score to [0 worst .. 1 best] 59 // ||v - w||_{L1} = 2 + Sum(|v_i - w_i| - |v_i| - |w_i|) 60 // for all i | v_i != 0 and w_i != 062 // scaled_||v - w||_{L1} = 1 - 0.5 * ||v - w||_{L1} 63 QueryResults::iterator qit; 64 for(qit = ret.begin(); qit != ret.end(); qit++) 65 qit->Score = -qit->Score/2.0; 66 }
-------------------2018.02.23 打印生成的orb特征----------------
输入2张图,提orb特征,描述子保存在features[0]、features[1]里,一张图500个特征点,每个点256维描述子(分成8bit*32),显示描述子竟然写了半天,我这弱渣的代码能力...
1 cout<<"features size:"<<features.size()<<endl; //feature定义:vector<cv::Mat> 2 cout<<"feautres[0] size:"<<features[0].size()<<endl; 3 for(int i=0;i<features[0].rows;i++) 4 { 5 for(int j=0;j<features[0].cols;j++) 6 { //十六进制显示 7 cout<<hex<<setfill(\'0\')<<setw(2)<<int( features[0].at<unsigned char>(i,j) )<<\' \'; 8 } 9 cout<<endl; 10 }

扩展:
dbow3支持4种描述类型:orb brisk akaze(opencv3) surf(编译选项USE_CONTRIB)
描述子orb: 32CV_8U(256bit) brisk 64CV_8U(512bit) akaze 61CV_8U(默认DESCRIPTOR_MLDB也是二进制描述子,根据a-kaze论文,描述子长度为486bit(61*8bit) )
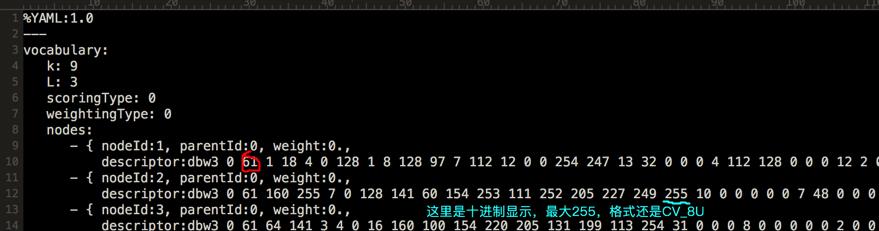
选择akaze描述子,生成的字典中描述子长度变为61:
-----------2019.04.04-----------
回顾了下去年这个项目:
1. 没有用到正序索引:

以上是关于开源词袋模型DBow3原理&源码的主要内容,如果未能解决你的问题,请参考以下文章