mysql小白系列_04 datablock
Posted 不懂ABAP的python不是好basis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql小白系列_04 datablock相关的知识,希望对你有一定的参考价值。
1.为什么创建一个InnoDB表只分配了96K而不是1M?
2.解析第2行记录格式?(用下面的表定义和数据做测试)


mysql> create table gyj_t3 (id int,name1 varchar(10),name2 varchar(10),name3 varchar(10),name4 varchar(10),name5 varchar(10)); Query OK, 0 rows affected (0.11 sec) mysql> insert into gyj_t3 (id,name1,name2,name3,name4) values(1,\'A\',\'BB\',\'CCC\',\'DDDD\'); Query OK, 1 row affected (0.03 sec) mysql> insert into gyj_t3 values(3,\'aaaaaaaaaa\',\'bbbbbbbbbb\',\'ccccc\',\'dddddd\',\'e\'); Query OK, 1 row affected (0.06 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> insert into gyj_t3 values(4,\'aaaaaaaaaa\',\'bbbbbbbbbb\',null,\'dddddd\',\'e\'); Query OK, 1 row affected (0.05 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM gyj_t3; +------+------------+------------+-------+--------+-------+ | id | name1 | name2 | name3 | name4 | name5 | +------+------------+------------+-------+--------+-------+ | 1 | A | BB | CCC | DDDD | NULL | | 1 | aaaaaaaaaa | bbbbbbbbbb | ccccc | | NULL | | 3 | aaaaaaaaaa | bbbbbbbbbb | ccccc | dddddd | e | | 4 | aaaaaaaaaa | bbbbbbbbbb | NULL | dddddd | e | +------+------------+------------+-------+--------+-------+
3.详细描述commit命令发出后,binlog日志从内存写到磁盘的过程序?
1.为什么创建一个InnoDB表只分配了96K而不是1M?
- innodb在给数据分配存储空间时,首先给32个的不连续的page
一个extent区是1M
- 如果32个page不够用,再分配一段连续的64个page,也就是16384*64=1M,此后每次分配空间都是1M的整数倍
- 目的:
- 节省空间
- 小的undo 32个 page就够了
问题:linux下查看一个ibd文件,大小是96K,也就是6个页,那么32个页不是一次性给完而是用多少给多少?
-rw-rw----. 1 mysql mysql 8.6K Feb 12 08:38 t3.frm -rw-rw----. 1 mysql mysql 96K Feb 12 08:38 t3.ibd
32个page是524288字节,差不多是512KB,插入数据使文件达到500多kb时,下一次增长为1M的整数倍
2.解析第2行记录格式?(用下面的表定义和数据做测试)
+------+------------+------------+-------+--------+-------+ | id | name1 | name2 | name3 | name4 | name5 | +------+------------+------------+-------+--------+-------+ | 1 | A | BB | CCC | DDDD | NULL | | 1 | aaaaaaaaaa | bbbbbbbbbb | ccccc | | NULL | | 4 | aaaaaaaaaa | bbbbbbbbbb | ccccc | dddddd | e | | 4 | aaaaaaaaaa | bbbbbbbbbb | NULL | dddddd | e | +------+------------+------------+-------+--------+-------+ create table t3 (id int,name1 varchar(10),name2 varchar(10),name3 varchar(10),name4 varchar(10),name5 varchar(10)); insert into t3 (id,name1,name2,name3,name4) values(1,\'A\',\'BB\',\'CCC\',\'DDDD\'); insert into t3 (id,name1,name2,name3,name4) values(1,\'aaaaaaaaaa\',\'bbbbbbbbbb\',\'ccccc\',\'\'); insert into t3 (id,name1,name2,name3,name4,name5) values(4,\'aaaaaaaaaa\',\'bbbbbbbbbb\',\'ccccc\',\'dddddd\',\'e\'); insert into t3 (id,name1,name2,name4,name5) values(4,\'aaaaaaaaaa\',\'bbbbbbbbbb\',\'dddddd\',\'e\');
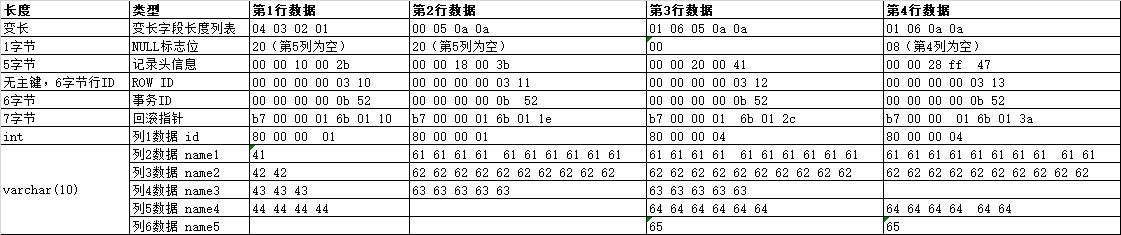
- NULL不占空间
- \'\'也不占空间
问题:NULL如何标志哪些列是NULL的?
《MySQL技术内幕InnoDB存储引擎》106页及网上大部分都是提了一下,参考http://blog.csdn.net/linux_ever/article/details/64124868
第三行有NULL值,因为NULL标志位不再是00而是06,转换成二进制00000110,为1的值表示第2列和第3列的数据为NULL。其后存储列数据的部分,没有存储NULL列,而只存储了第1列和第4列的非NULL的值
*************************** 3. row ***************************
t1: d
t2: NULL
t3: NULL
t4: fff
3 rows in set (0.00 sec)
这里的第2和第3列为NULL,NULL标志位为06,二进制是00000110,是怎么算出来2、3列的?
本次作业的第1、2行数据第5列为NULL,标志位是20,二进制是00100000
第4行数据第4列为NULL,标志位是08,二进制是00001000

int长度是4字节,其他可变长name长度是10字节,用多少长多少
https://www.cnblogs.com/wade-luffy/p/6289183.html
http://blog.csdn.net/beiigang/article/details/42175995
ibd文件格式如下
| 内容 | 16进制地址 |
|---|---|
| File Space Header | 0x0008 |
| Insert Buffer Bitmap | 0x0005 |
| File Segment Inode | 0x0003 |
| Used Page | 0x45BF |
| …… | 第N-4个块 |
| Used Page | 第N-3个块 |
| Free Page | 第N-2个块 |
| …… | 第N-2个块 |
| Free Page | 第N-2个块 |
https://dev.mysql.com/doc/internals/en/innodb-page-overview.html
https://www.cnblogs.com/crossapply/p/5455620.html
行记录格式
- compressed 压缩页,默认16K,可以压缩成8K、4: alter table tabname row_format=compressed,key_block_size=8;
- Dynamic 存储LOB/TEXT字段,由20字节+偏移量组成,本身不存储数据,偏移量指向数据
- Compact 默认行记录格式,超出行记录长度时,由前缀768字节+偏移量组成,本身存储部分数据,偏移量指向数据
- Redundant 废弃
获取ibd十六进制文本
hexdump -C -v t3.ibd > /tmp/t3.ibd.txt [root@docker01 tmp]# cat t3.ibd.txt |head -n 2 00000000 24 0a 12 cf 00 00 00 00 00 00 00 00 00 00 00 00 |$...............| 00000010 00 00 00 00 00 1a 25 e3 00 08 00 00 00 00 00 00 |......%.........| [root@docker01 tmp]# cat t3.ibd.txt |head -n 2048| tail -n 1024 |head -n 2 00004000 99 5f 47 61 00 00 00 01 00 00 00 00 00 00 00 00 |._Ga............| 00004010 00 00 00 00 00 1a 16 27 00 05 00 00 00 00 00 00 |.......\'........| [root@docker01 tmp]# cat t3.ibd.txt |head -n 3072| tail -n 1024 |head -n 2 00008000 c2 25 6e 67 00 00 00 02 00 00 00 00 00 00 00 00 |.%ng............| 00008010 00 00 00 00 00 1a 25 e3 00 03 00 00 00 00 00 00 |......%.........| [root@docker01 tmp]# cat t3.ibd.txt |head -n 4096| tail -n 1024 |head -n 2 0000c000 48 81 1b 2c 00 00 00 03 ff ff ff ff ff ff ff ff |H..,............| 0000c010 00 00 00 00 00 1a 3e 2e 45 bf 00 00 00 00 00 00 |......>.E.......| 截取第4页 0000c000 48 81 1b 2c 00 00 00 03 ff ff ff ff ff ff ff ff |H..,............| 0000c010 00 00 00 00 00 1a 3e 2e 45 bf 00 00 00 00 00 00 |......>.E.......| 0000c020 00 00 00 00 00 0d 00 02 01 5b 80 06 00 00 00 00 |.........[......| 0000c030 01 29 00 02 00 03 00 04 00 00 00 00 00 00 00 00 |.)..............| 0000c040 00 00 00 00 00 00 00 00 00 1b 00 00 00 0d 00 00 |................| 0000c050 00 02 00 f2 00 00 00 0d 00 00 00 02 00 32 01 00 |.............2..| 0000c060 02 00 1f 69 6e 66 69 6d 75 6d 00 05 00 0b 00 00 |...infimum......| 0000c070 73 75 70 72 65 6d 75 6d 04 03 02 01 20 00 00 10 |supremum.... ...| 0000c080 00 2b 00 00 00 00 03 10 00 00 00 00 0b 52 b7 00 |.+...........R..| 0000c090 00 01 6b 01 10 80 00 00 01 41 42 42 43 43 43 44 |..k......ABBCCCD| 0000c0a0 44 44 44 00 05 0a 0a 20 00 00 18 00 3b 00 00 00 |DDD.... ....;...| 0000c0b0 00 03 11 00 00 00 00 0b 52 b7 00 00 01 6b 01 1e |........R....k..| 0000c0c0 80 00 00 01 61 61 61 61 61 61 61 61 61 61 62 62 |....aaaaaaaaaabb| 0000c0d0 62 62 62 62 62 62 62 62 63 63 63 63 63 01 06 05 |bbbbbbbbccccc...| 0000c0e0 0a 0a 00 00 00 20 00 41 00 00 00 00 03 12 00 00 |..... .A........| 0000c0f0 00 00 0b 52 b7 00 00 01 6b 01 2c 80 00 00 04 61 |...R....k.,....a| 0000c100 61 61 61 61 61 61 61 61 61 62 62 62 62 62 62 62 |aaaaaaaaabbbbbbb| 0000c110 62 62 62 63 63 63 63 63 64 64 64 64 64 64 65 01 |bbbcccccdddddde.| 0000c120 06 0a 0a 08 00 00 28 ff 47 00 00 00 00 03 13 00 |......(.G.......| 0000c130 00 00 00 0b 52 b7 00 00 01 6b 01 3a 80 00 00 04 |....R....k.:....| 0000c140 61 61 61 61 61 61 61 61 61 61 62 62 62 62 62 62 |aaaaaaaaaabbbbbb| 0000c150 62 62 62 62 64 64 64 64 64 64 65 00 00 00 00 00 |bbbbdddddde.....| ..... 0000fff0 00 00 00 00 00 70 00 63 8b 8a 26 91 00 1a 3e 2e |.....p.c..&...>.|
3.详细描述commit命令发出后,binlog日志从内存写到磁盘的过程序?
- 先做write操作
- 日志会被write到每个线程对应的文件句柄的缓存中,也就是标准的IO缓存中
- 每个线程会缓存到自己的IO缓存中,每个线程产生的日志其他线程是不可见的
此时发生宕机,日志丢失,脏块丢失
- 再做flush操作
- 将私有缓存中的日志写到公共可见的操作系统文件缓存,此时不同线程都可以看到其他线程的日志内容
此时宕机,依然丢失数据
- 最后做sync持久化
- 将日志从内存中写到硬盘
sync_binlog 1 多少次事务一起写binlog
innodb_flush_log_at_trx_commit 1 写redolog
索引:
- 主键索引
- 非空唯一索引
- 都没有的话走6字节的rowid,但是不能作为where过滤条件
index organized table索引组织表:数据就在叶子节点上,检索数据不需要回行
回行,先找到索引所在位置,根据索引再一次找到数据 二级索引、辅助索引,叶子节点只存储索引信息,叶子上带着的信息指向数据所在的主键索引的位置
innodb逻辑存储结构: tablespace - segement - extent - page - row
表空间是否独立 innodb_file_per_table,默认为ON
如果是独立表空间,一张表一个表空间
如果是off,就全部放在ibdata1里面了
查看表ID ,0 代表的是系统表空间 select * from innodb_sys_tables
-
tablespace指的是共享表空间ibdata1,存储的是undo、插入缓冲索引页、系统事务、double write buffer,因为写undo原因,大小随时变化
-
ib_logfile,每个表自己的空间:数据(跟主键索引一起存放)、辅助索引、插入缓存bitmap
-
插入缓冲
- 主键索引和数据放在一起,其他索引放在索引页
- 往辅助索引页写东西时,每个被写入的页先放在buffer存着
- 一旦有需要被写入的索引页读入了内存,这是把buffer里存着的东西一起写进去
-
segement 段
- 段等于表,段是数据的物理存储形式,表是数据的逻辑定义
- 数据段,聚簇索引,数据段在B-tree的叶子结点
- 索引段,非叶子结点就是索引
-
extent 区
- 一个extent是1M,是分配空间的最小单位
- 1M由64个连续的page组成,一个page是16K
- innodb为保证extent连续,一次申请多个
- 一个extent由多个page组成
-
page 页,类似存储块大小
- 最小的IO单位
- page默认大小是16K innodb_page_size = 16384
- ROW 行
- 事务ID、回滚指针、数据、索引
innodb文件结构
表的组成:
- tabname.ibd 表数据
- File Space Header
- tabname.frm 表结构
hexdump -C -v tabname.ibd 一个page 16K,16进制一行有16个字节,那么一个page就有1024行 查看第一个块
hexdump -C -v tabname.ibd |head -n 1024 | head -n 2
2块
hexdump -C -v tabname.ibd |head -n 2048 |tail -n 1024
3块
hexdump -C -v tabname.ibd |head -n 3072 |tail -n 1024
以上是关于mysql小白系列_04 datablock的主要内容,如果未能解决你的问题,请参考以下文章