Unity离线文档使用技巧(打开慢,查找慢的问题)
Posted .木木啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unity离线文档使用技巧(打开慢,查找慢的问题)相关的知识,希望对你有一定的参考价值。
使用技巧
下载地址
英文版和中文版的下载网址路径不一样。
英文版:https://storage.googleapis.com/docscloudstorage/unity版本/UnityDocumentation.zip
例如: https://storage.googleapis.com/docscloudstorage/2021.3/UnityDocumentation.zip
中文版:https://storage.googleapis.com/localized_docs 网址里带有zh-cn的Key
例如: https://storage.googleapis.com/localized_docs/zh-cn/2021.3/UnityDocumentation.zip
离线文档打开慢的问题
我在网上查阅了一些相关回答,大部分的解答都是说,即使是离线文档,html网页也会去访问国外的域名(比如google域名之类的),有些域名被国内屏蔽,导致请求响应时间长(表现出来就是打开慢)。
推荐的方法有 修改hosts文件,翻墙加快访问,断网不访问,等等这些修改环境的方法解决。
但是我不想改环境,所以把所有html文件里的被屏蔽网址改掉最好,用Python代码删掉html中的一些:
fonts.googleapis.com
www.googletagmanager.com
cdn.cookielaw.org/scripttemplates/otSDKStub.js
代码如下:
#!/usr/bin/env python3
import os
fileNum = 0
for (dirpath, dirs, files) in os.walk(os.path.curdir):
for file in files:
if file.endswith(".html"):
filePath = os.path.join(dirpath,file)
with open(filePath,'r',encoding='utf-8') as f:
s = f.read().replace("fonts.googleapis.com",'').replace("www.googletagmanager.com",'').replace("cdn.cookielaw.org/scripttemplates/otSDKStub.js",'')
with open(filePath,'w',encoding='utf-8') as f:
f.write(s)
fileNum = fileNum + 1
message = ">>>修改完成 第" + str(fileNum) + "个文件,路径: " + filePath
print(message)
print("共修改",fileNum,"个文件")
python文件位置:
python文件应该在文档路径里运行

离线文档快速查找技巧
把文档放在Unity安装路径下,方便在使用Unity时快速查找使用
离线文档解压后,在对应版本的Unity安装路径下,打开Editor->Data->Documentation(没有创建一个)在这文件夹里面在建一个文件夹en,把其他的文件夹都放在en里面。最后的文件路径:Unityx.x.x/Editor/Data/Documentation/en/
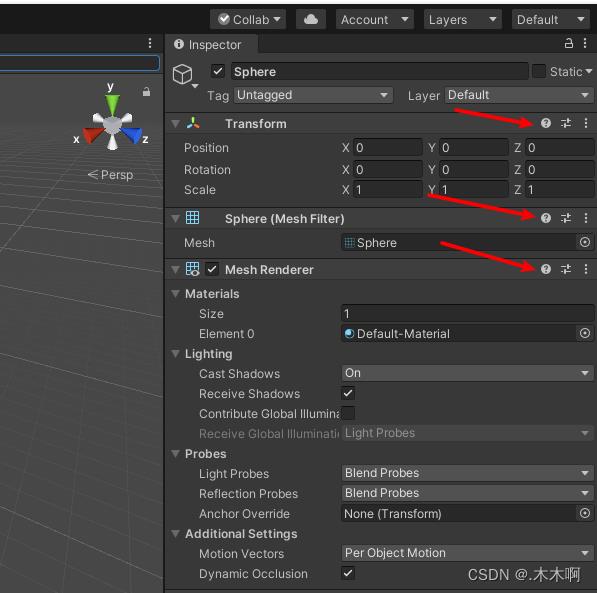
在Unity内通过?打开对应的说明
Selenium打开浏览器加载慢的原因
在自动化元素定位操作中经常使用智能等待来加强定位的强壮性,主要就是因为WebDriver没有提供页面加载场景的方法;在使用JavaScript知识的突然心生灵感,可以使用JavaScript来配合验证页面加载,结果发现我真是井底之蛙。
一、domcument.readyState
首先定位从Document对象出发,而Document对象是在html文档加载完成便可操作使用,所以判断文件装载完成即可;Document对象的readyState属性返回当前文档装载状态:
uninitialized 表示未开始载入
loading 载入中,下载了html并且开始加载
interactive 已加载完html内容
complete 已加载完html内容和下载解析了子资源(js、css、image),不包含ajax异步。
public static void pageDOMLoadComplete(){
JavaScriptExecutor js=(JavaScriptExecutor) SeleniumMethod.ThreadDriver.get();
try {
while(!"complete".equals(js.executeScript("return document.readyState"))){
Thread.sleep(2000);
}
logger.info("页面元素加载完成");
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
logger.info("判断页面元素加载异常");
}
}
如上代码,如果结果返回的complete表示加载完成,这时候就可以开始元素定位操作。返回不是complete则使用线程循环等待,直到加载完成才跳出循环。
详细了解的建议去脑补一下浏览器对页面加载的过程。通过浏览器发送请求到服务器响应先得到html形成Document对象,浏览器解析html形成dom树开始加载,当加载dom树遇到外部资源时去请求外部资源,但加载dom树并不会等待会继续加载,当资源如JavaScript、css、图片等等加载完成这时候document.readyState的值变成complete。
二、Selenium加载策略
因为Selenium从头到位都没有任何判断页面加载完成的关键字;而结合document.readyState的返回来确定页面加载成功,然后再去执行定位操作,这样来说是个合理的思想。根据想法编写下面的代码:
WebDriver driver = new ChromeDriver();
driver.get("https://www.sina.com.cn/");
try {
while(!"complete".equals(((JavaScriptExecutor) driver).executeScript("return document.readyState"))) {
Thread.sleep(1000);
}
} catch(Exception e) {
// TODO: handle exception
e.printStackTrace();
}
driver.findElement(By.name("SerchKey")).sendKeys("软件测试");
driver.findElement(By.name("SearchSubButton")).click();
driver.quit();
上面代码利用JavaScript执行一段脚本document.readyState的值返回不是complete则一直循环并线程等待1S,直到返回的值是complete退出循环。
但是在代码运行后发现,从来都没有进入过循环。于是猜测,是get()方法在打开浏览器并访问URL时,是不是就已经判断过页面加载完成了?验证方法很简单,把循环去掉,代码直接打印document.readyState返回的值
System.out.print(((JavaScriptExecutor)driver).executeScript("return document.readyState"));
得到的结果每次都是complete,验证确实get()方法后就已经页面加载成功了。在使用WebDriver时,每次打开浏览器都知道它并不会带有任何缓存数据,而是一个全新初始化的浏览器,这点只要用过Selenium的同学,并做过登录功能都应该知道,每次使用都需要重新登录,浏览器并不会保存任何cookie、缓存信息。就是因为这个原因,WebDriver每次调起浏览器并访问URL的时候因为没有缓存所以页面加载会非常慢(当然不仅仅是缓存,WebDriver还会去遍历一些其他东西,如虚拟网卡、代理配置等);这个慢的现象大多数是页面已经展示内容了,然后浏览器还在转圈加载,然而使用document.readyState来判断好像不现实了,因为WebDriver的get()方法默认就会等待页面加载完。所以思路就转化为,get()方法的探究。
通过官方资料查询,发现WebDriver有pageLoadStrategy加载策略这一说,地址如下:https://www.w3.org/TR/webdriver/#dfn-table-of-page-load-strategies,大家可以自己去瞧瞧。加载策略有如下三种:
none:没有说明对应关系
eager:对应ducument readiness state为”interactive”
normal:对应ducument readiness state为”complete”
从上面三种加载策略可以看到,官方除了none这种没有具体说明外,另外两种对应的正式document.readyState返回的状态。而默认的加载策略是normal,所以再次验证为什么使用document.readyState得到的值是complete。验证代码如下:
DesiredCapabilities capabilities = DesiredCapabilities.chrome();
capabilities.setCapability("pageLoadStrategy", "none");
WebDriver driver = new ChromeDriver(capabilities);
driver.get("https://www.sina.com.cn/");
System.out.println(((JavaScriptExecutor) driver).executeScript("return document.readyState"));
driver.findElement(By.name("SerchKey")).sendKeys("软件测试");
driver.findElement(By.name("SearchSubButton")).click();
System.out.println(((JavaScriptExecutor) driver).executeScript("return document.readyState"));
driver.quit();
执行代码,打印document.readyState返回的结果是loading;在使用findElement查找元素时报错“Unable to locate element”。当加载策略为none时,对应document.readyState结果是loading的时候,页面还在加载中,进行元素查找会报错,这很好理解,Dom树还在加载过程中,是无法解析任何元素的查找的,所以报错。
接下来分别尝试了eager加载策略,需要注意一点的是Chrome浏览器并不支持这种加载策略,所以改为了Firefox验证。
DesiredCapabilities capabilities = DesiredCapabilities.firefox();
capabilities.setCapability("pageLoadStrategy", "eager");
WebDriver driver = new FirefoxDriver(capabilities);
其他代码不变,执行代码打印document.readyState返回的结果是interactive,但是不同的是使用findElement查找元素没有报错,并且全部执行成功。当加载策略为eager,页面加载结果interactive时,整个DOM树加载完成,这时候就已经可以定位元素并执行操作了;根据document.readyState与WebDriver的加载策略得出以下结论:
(1)loading与none
DOM树 载入中,也就是说已经下载了html并且开始加载;这时候是无法查找元素的,get()方法的执行时间非常短,可以马上执行get()方法后面的代码。所以这时候就可以使用下面代码再次进行判断后再执行。
while(!"complete".equals(((JavascriptExecutor)driver).executeScript("return document.readyState"))){}
这样的作法好像与加载策略的默认方法没什么不同,但是WebDriver的get()方法可不仅仅是等待页面为complete而已,它还会去判断一些浏览器其他的配置。
这种情况还有一种不建议使用的方式,就是使用隐式等待,每次查找元素找不到时,等待一定时间。隐式等待在当前driver的整个生命周期中都生效,是非常适合配合none这种加载策略的。
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
新片场https://www.wode007.com/sites/73286.html 傲视网https://www.wode007.com/sites/73285.html
(2)interactive与eager
已加载完html内容,但是没有解析子资源;这时候DOM树加载完成,并且去请求子资源了,是可以查找元素并正确返回了。有个弊端就是如果一些数据是通过JavaScript去赋值的,这时候查找元素某些属性数据可能得到空。
(3)complete与normal
已加载完html内容和下载解析了子资源(JavaScript、css、image),不包含ajax异步。前面应该都没疑问,重要的是ajax异步请求的加载。如果页面上一些数据是通过ajax异步去请求并加载的,同样在ajax请求中数据响应没有及时回来的情况下,拿到的也是空。当然这并不需要担心,只要不是太大数据请求响应还是非常快速的。
以上是关于Unity离线文档使用技巧(打开慢,查找慢的问题)的主要内容,如果未能解决你的问题,请参考以下文章