Hadoop2 使用 YARN 运行 MapReduce 的过程源码分析
Posted 秦时明月0515
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop2 使用 YARN 运行 MapReduce 的过程源码分析相关的知识,希望对你有一定的参考价值。
Hadoop 使用 YARN 运行 MapReduce 的过程如下图所示:
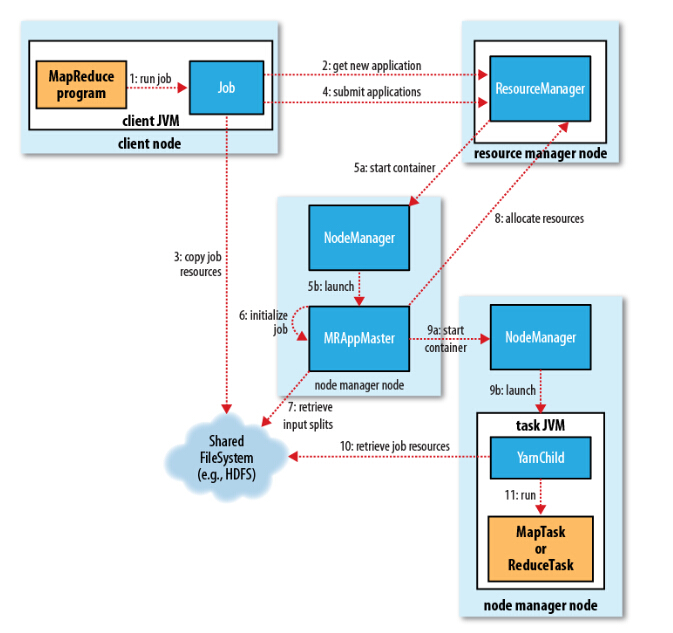
总共分为11步. 这里以 WordCount 为例, 我们在客户端终端提交作业:
# 把本地的 /home/hadoop/test.txt 文件上传到 HDFS 的 /input 下, 之后 HDFS 会对文件分块等 hadoop-2.7.3/bin/hadoop fs -put /home/hadoop/test.txt /input/ # 我们以 hadoop 自带测试例子 wordcount 为例 hadoop-2.7.3/bin/hadoop jar hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
第一步: run job ( 运行作业 )
这一步是在 Client 内部进行, hadoop jar .... 是通过 RunJar 运行的, 参考 hadoop-2.7.3/bin/hadoop
# 这段代码在 hadoop-2.7.3/bin/hadoop 中 # the core commands if [ "$COMMAND" = "fs" ] ; then CLASS=org.apache.hadoop.fs.FsShell elif [ "$COMMAND" = "version" ] ; then CLASS=org.apache.hadoop.util.VersionInfo elif [ "$COMMAND" = "jar" ] ; then CLASS=org.apache.hadoop.util.RunJar if [[ -n "${YARN_OPTS}" ]] || [[ -n "${YARN_CLIENT_OPTS}" ]]; then echo "WARNING: Use \\"yarn jar\\" to launch YARN applications." 1>&2 fi
( 未完待续 )
以上是关于Hadoop2 使用 YARN 运行 MapReduce 的过程源码分析的主要内容,如果未能解决你的问题,请参考以下文章