搜索关键字更正 - Oracle Endeca Server
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索关键字更正 - Oracle Endeca Server相关的知识,希望对你有一定的参考价值。
做了几个Oracle Endeca 电商项目。每个项目都会有搜过关键字拼写错误更正(Spelling Correction)的需求。淘宝也有类似功能。

Oracle Endeca Sever提供了关键字拼写更正的功能。项目开发中一般只需要用这个Endeca预置功能,必要时做些调整就可。但是一直很好奇Endeca怎么知道用户拼写错了,怎么知道应该将用户输入的关键字更正为什么。闲来无事,查阅了一些资料。整理如下:
Endeca Server为关键字更正提供了两种方式:
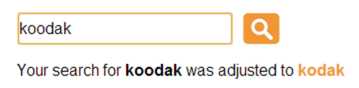
1. 自动更正 (Auto Spelling Correction): 当用户输入的关键字在系统字典文件(dictionary file)里不存在时,系统直接将用户输入的关键字替换成系统认为用户真正想输入的关键字,然后用替换后的关键字去搜索,并显示搜索结果。 一般UI如下。
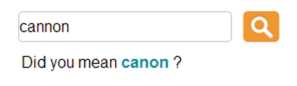
2. 拼写建议 (Explicit Spelling Suggestion): 当用户输入的关键字只能匹配到极少的结果, 如6个以下 (数量可配置),系统向用户展示搜索结果的同时从字典文件里找出匹配结果更多且和用户输入的关键字相似的关键字,并询问用户是否想切换成系统建议的关键字。如用户输入Cannon, 有3条结果,但是 Canon有几百上千条结果。系统就会向用户展示和Cannon匹配的3条结果,并且提示 Did you mean Canon? 用户点击 Canon 即可用 Canon 发起另一个搜索。
问题一: 系统字典文件是关键字建议的来源。字典文件是怎么来的呢?
字典文件里的所有单词来源于数据中所有可搜索的属性值。默认情况下,Endeca 将所有的可搜索的属性值加入字典文件。例如,数据里有300条商品。商量的可搜索属性为商品名称、颜色和描述。Endeca 就会将这300条商品中所有的商品名称、颜色和描述中含有的单词加到一个文件里,形成了字典文件。
但是当数据量很大时,字典文件就会很大,从而影响系统性能。于是Endeca提供了一个界面可以让用户配置哪些单词可以加到字典文件。从下减小字典文字的大小。配置界面如下图。
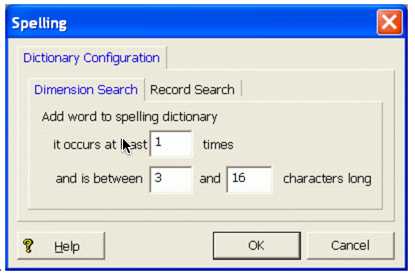
it occurs at least n times: 单词在数据源里出现过n次以上,才能被加入字典文件。商量名里有Kodar, 那Kodar在所有的商品可搜索属性里出现过5(n)次 以上才能被编入字典文件。
and is between n1 and n2 characters long: 单词长度在n1 - n2 个字符以内才能被编入字典文件。
问题二:Endeca 根据什么逻辑挑选字典文件里的单词呢?比如用户输入Kodaaar, 字典文件里有Kodar1, Kodar2, Kodar3, 那Endeca应该将Kodaaar替换成Kodar1 还是Kodar2或Kodar3呢?
暂时无解。欢迎各路大神留言指点。
参考资料:
https://docs.oracle.com/cd/E40518_01/server.761/es_dev/src/cdg_spelldym_about.html
https://docs.oracle.com/cd/E29584_01/webhelp/mdex_advDev/src/tadv_spelldym_configuring_in_devstudio.html
原文地址:http://www.cnblogs.com/lixiaoyan0203/p/6972993.html
以上是关于搜索关键字更正 - Oracle Endeca Server的主要内容,如果未能解决你的问题,请参考以下文章
无法更正 Oracle 错误 ORA-00905 SQL 中缺少关键字