大数据Flink进阶(十三):Flink 任务提交模式
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Flink进阶(十三):Flink 任务提交模式相关的知识,希望对你有一定的参考价值。

文章目录
Flink 任务提交模式
Flink分布式计算框架可以基于多种模式部署,每种部署模式下提交任务都有相应的资源管理方式,例如:Flink可以基于Standalone部署模式、基于Yarn部署模式、基于Kubernetes部署模式运行任务,以上不同的集群部署模式下提交Flink任务会涉及申请资源、各角色交互过程,不同模式申请资源涉及到的角色对象大体相同,下面我们以Flink运行时架构流程为例来总体了解下Flink任务提交后涉及到对象交互流程,以便后续学习不同任务提交模式下任务提交流程。
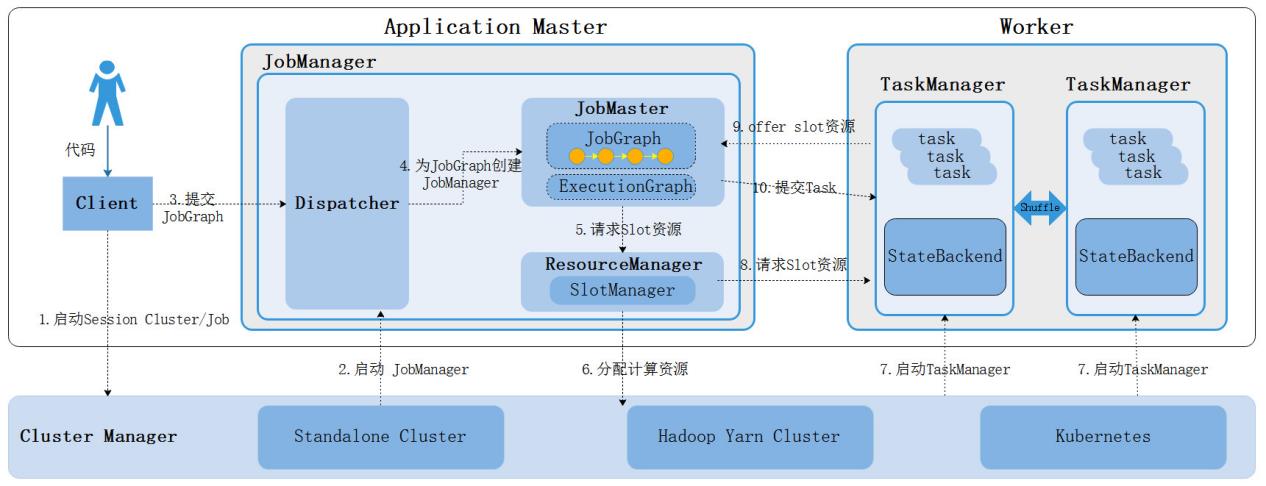
上图是Flink运行时架构流程,涉及集群启动、任务提交、资源申请分配整个流程,大体步骤如下:
- 启动Flink集群首先会启动JobManager,Standalone集群模式下同时启动TaskManager,该模式资源也就固定;其他集群部署模式会根据提交任务来动态启动TaskManager;
- 当在客户端提交任务后,客户端会将任务转换成JobGraph提交给JobManager;
- JobManager首先启动Dispatcher用于分发作业,运行Flink WebUI提供作业执行信息;
- Dispatcher启动后会启动JobMaster并将JobGraph提交给JobMaster,JobMaster会将JobGraph转换成可执行的ExecutionGraph。
- JobMaster向对应的资源管理器ResourceManager为当前任务申请Slot资源;
- 在Standalone资源管理器中会直接找到启动的TaskManager来申请Slot资源,如果资源不足,那么任务执行失败;
- 其他资源管理器会启动新的TaskManager,新启动的TaskManager会向ResourceManager进行注册资源,然后ResourceManager再向TaskManager申请Slot资源,如果资源不足会启动新的TaskManager来满足资源;
- TaskManager为对应的JobMaster offer Slot资源;
- JobMaster将要执行的task发送到对应的TaskManager上执行,TaskManager之间可以进行数据交换。
以上就是Flink任务提交的整体流程信息,在Flink中任务提交还有多种模式,不同的Flink集群部署模式支持的任务提交模式不同,对应的任务执行流程略有不同,向Flink集群中提交任务有三种任务部署模式,分别如下:
- 会话模式 - Session Mode
- 单作业模式 - Per-Job Mode(过时)
- 应用模式 - Application Mode
以上三种任务提交模式的主要区别在于Flink集群的生命周期不同、资源的分配方式不同以及Flink 应用程序的main方法执行位置(Client客户端/JobManager)不同。
下面分别进行介绍:
一、会话模式(Session Mode)
Session模式下我们首先会启动一个集群,保持一个会话,这个会话中通过客户端提交作业,集群启动时所有的资源都已经确定,所以所有的提交的作业会竞争集群中的资源。这种模式适合单个作业规模小、执行时间短的大量作业。
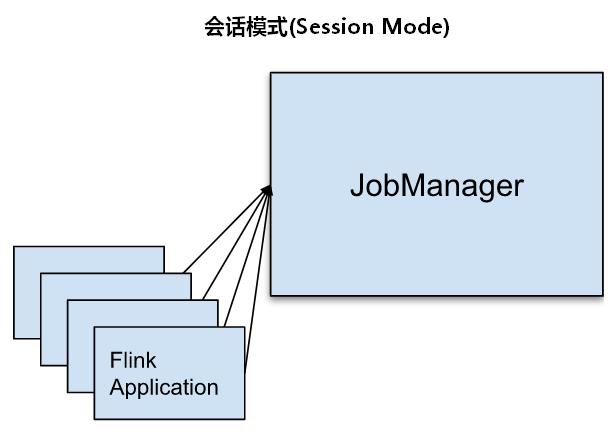
优势:只需要一个集群,所有作业提交之后都运行在这一个集群中,所有任务共享集群资源,每个任务执行完成后就释放资源。
缺点:因为集群资源是共享的,所以资源不够了,提交新的作业就会失败,如果一个作业发生故障导致TaskManager宕机,那么所有的作业都会受到影响。
二、单作业模式(Per-Job Mode)
为了更好的隔离资源,Per-job模式是每提交一个作业会启动一个集群,集群只为这个作业而生,这种模式下客户端运行应用程序,然后启动集群,作业被提交给JobManager,进而分发给TaskManager执行,作业执行完成之后集群就会关闭,所有资源也会释放。
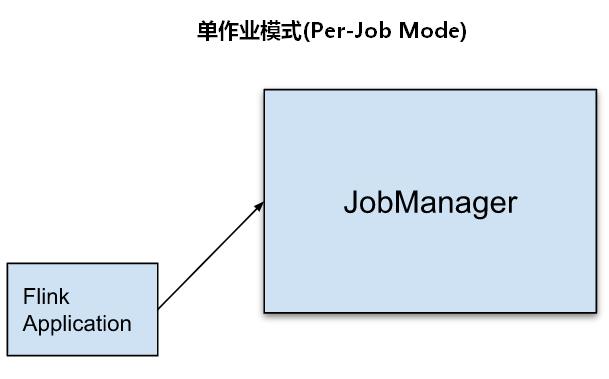
优势:这种模式下每个作业都有自己的JobManager管理,独享当下这个集群的资源,就算作业发生故障,对应的TaskManager宕机也不影响其他作业。如果一个Application有多个job组成,那么每个job都有自己独立的集群。
缺点:每个作业都在客户端向集群JobManager提交,如果一个时间点大量提交Flink作业会造成客户端占用大量的网络带宽,会加重客户端所在节点的资源消耗。
注意:Per-Job 模式目前只有yarn支持,Per-job模式在Flink1.15中已经被弃用,后续版本可能会完全剔除,替代的是Application模式,主要原因就是Application模式把main方法的初始化放到了集群组件的JobManager中,这样对于客户端来说从性能上有很大优化。
三、应用模式(Application Mode)
Session 模式和Pre-Job模式都是在客户端将作业提交给JobManager,这种方式需要占用大量的网络带宽下载依赖关系并将二进制包发送给JobManager,此外,我们往往提交多个Flink 作业都是在同一个客户端节点,这样更加剧了客户端所在节点的资源消耗,为了降低客户端这种资源消耗,我们可以使用Application Mode。
Application模式与Per-job类似,只是不需要客户端,每个Application提交之后就会启动一个JobManager,也就是创建一个集群,这个JobManager只为执行这一个Flink Application而存在,Application中的多个job都会共用该集群,Application执行结束之后JobManager也就关闭了。这种模式下一个Application会动态创建自己的专属集群(JobManager),所有任务共享该集群,不同Application之间是完全隔离的,在生产环境中建议使用Application模式提交任务。
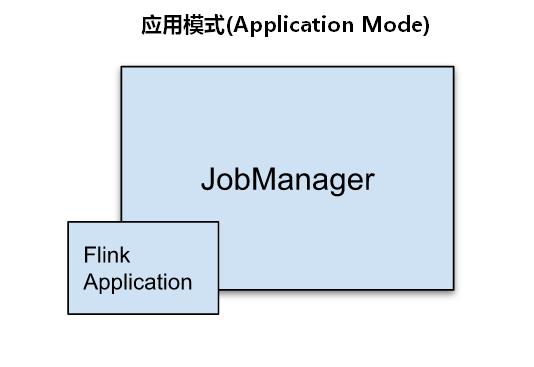
以上三种Flink任务部署方式生产环境中优先选择Application模式,三者区别总结如下:
- Session 模式是先有Flink集群后再提交任务,任务在客户端提交运行,提交的多个作业共享Flink集群;
- Per-Job模式和Application模式都是提交Flink任务后创建集群;
- Per-Job模式通过客户端提交Flink任务,每个Flink任务对应一个Flink集群,每个任务有很好的资源隔离性;
- Application模式是在JobManager上执行main方法,为每个Flink的Application创建一个Flink集群,如果该Application有多个任务,这些Flink任务共享一个集群。
Flink不同的集群部署模式支持不同的任务提交方式,后续会重点介绍Standalone资源管理和Yarn资源管理任务提交模式的支持。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
Flink内核原理学习任务提交流程
Flink内核原理学习之任务提交流程
文章目录
首先要知道的是,Flink作业提交是由PipelineExecutor(流水线执行器)在Flink Client生成JobGraph后将作业提交给集群的重要环节。PipelineExecutor按照集群作业执行模式主要分为Session、Per-Job、Local模式,其中Local是本地调试时使用的所以不参与后续讨论。
一、Flink任务提交流程(yarn-per-job模式)
Per-Job模式中每个任务都会在YARN上重新启动集群。根据官方文档说法,也就是JobManager创建后,然后将作业提交给在这个进程中运行的 Dispatcher,然后根据作业的资源请求惰性的分配 TaskManager。一旦作业完成,Flink Job 集群将被拆除。
由于 ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源,因此 Flink Job 集群更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
1.1 总体流程解析
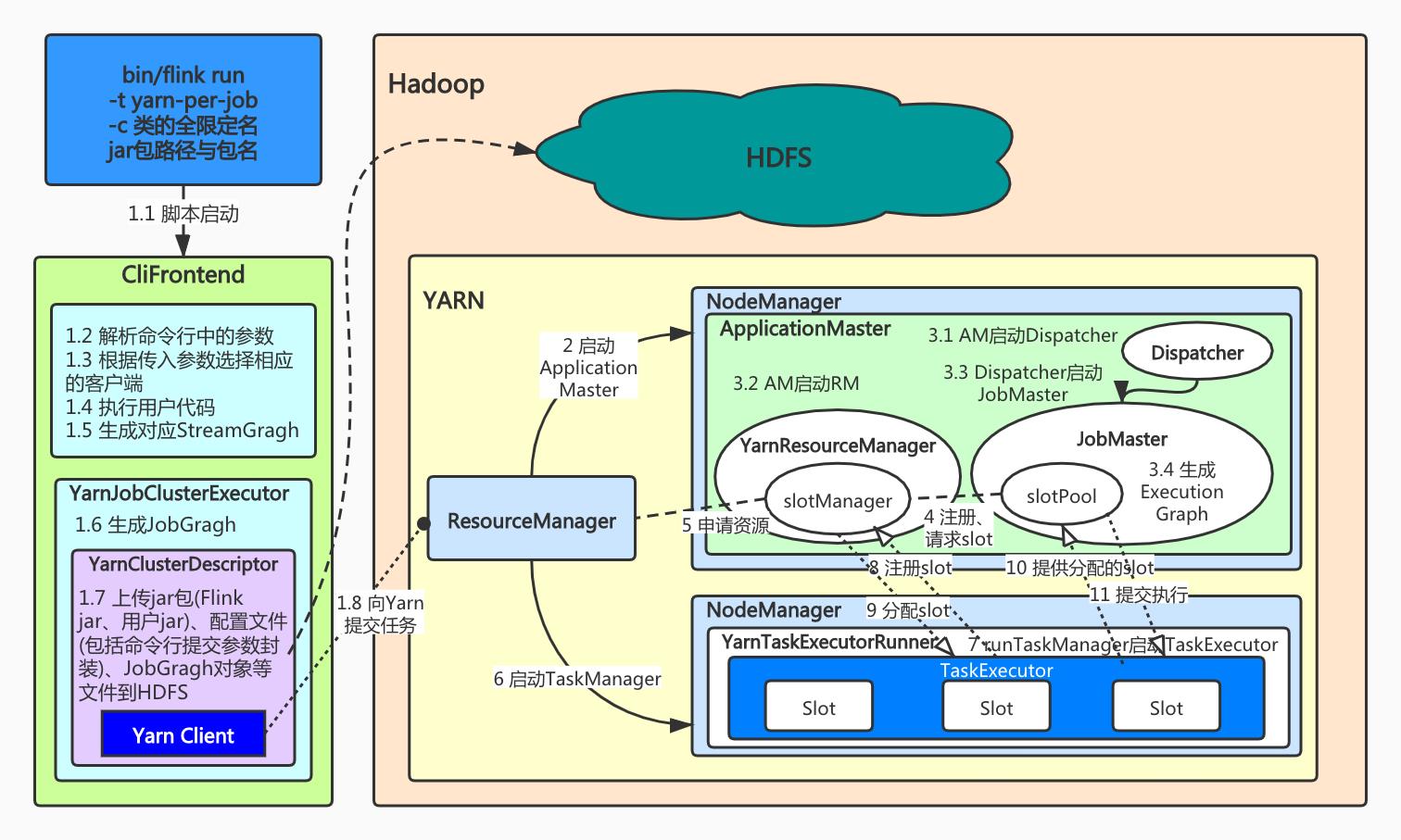
具体流程如下(未对应图中的序号,有扩充或精炼):
- 客户端阶段:
- 首先使用命令行
flink run -t yarn-per-job(1.10版本前是flink run -m yarn-cluster)来提交Per-Job任务,后面可以带其他参数,但必须指定自己作业的类全限定名和jar包。- 命令行执行后是通过CliFrontend(客户端前端)中的main方法进入后续的作业提交流程。
- 客户端中主要做了命令行参数解析并根据命令类型封装相应的客户端对象。
- 执行用户作业类中main方法中的代码,生成对应的StreamGragh。
- 在
YarnJobClusterExecutor(PipelineExecutor)中生成JobGragh。- 生成YarnClusterDescriptor,主要是上传资源到HDFS中,包括jar包(Flink的jar包和用户jar包)、应用配置(flink-conf.yaml、log4j.properties)、其他相关文件(配置类文件、JobGragh对象等)。
- 创建Yarn客户端准备向Yarn申请创建ApplicationMaster(JobManager)。
- Yarn集群阶段:
- Yarn的ResourceManager为ApplicationMaster申请到容器后,以
YarnJobClusterEntryPoint作为集群启动入口开启JobManager进程。- AM中首先创建和启动Dispatcher和YarnResourceManager(这是Flink内部的RM,后简称YRM)。
- 在Dispatcher读取到JobGragh后,为此作业构建一个JobMaster,将作业交给JobMaster,在其中将JobGragh构建为ExecutionGragh。
- JobMaster中的SlotPool向YRM中的SlotManager申请资源。而SlotManager需要向Yarn的RM请求资源(requestNewWorker),YRM先将资源请求加入等待队列,通过心跳向YARN的RM申请新的容器来启动TaskManager进程。
- 容器就绪后,YRM在容器中启动TaskManager进程(入口为
YarnTaskExecutorRunner),调用runTaskManager启动TaskExecutor(真正的实例)。- TaskExecutor向SlotManager反向注册,汇报当前可用slot数量。SlotManager返回分配slot的信息。
- TaskExecutor根据分配信息,向对应的JobMaster提供slot。JobMaster得到消息后,向对应的slot提交任务开始执行(
submitTask)
1.2 具体组件解释
JobManager
- Dispatcher:是一个Rest接口(对于Session模式来说),不负责实际的调度执行方面的工作,而是接收JobGragh后为作业创建一个JobMaster,将工作交给JobMaster。
- JobMaster:负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster(内含soltPool)。
- ResourceManager :负责 Flink 集群中的资源提供、回收、分配 。其中的slotManager管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
TaskManager
- TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(算子链优化)
关于Gragh相关的知识将在Flink任务调度中介绍。
二、Flink任务提交流程(yarn-session模式)
Session模式顾名思义,Flink集群在Yarn上长期存在,适用于执行一些比较小而快的任务。优缺点很明显,优点在于集群长期存在省去了Dispatcher、ResourceManager、TaskManager的重复创建;缺点如官方文档中介绍的如果TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager上发生一些致命错误,它将影响集群中正在运行的所有作业。
而这种模式的首次提交作业,流程除了客户端方面的不同外其他流程与Per-Job几乎相同。当新的任务到来时,Dispatcher根据不同作业提交的JobGragh创建对应JobMaster并将工作交给它;在作业调度期间,TaskManager资源不足则由ResourceManager向Yarn请求新的容器来构建新的TaskManager。
以上是关于大数据Flink进阶(十三):Flink 任务提交模式的主要内容,如果未能解决你的问题,请参考以下文章