INN实现深入理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了INN实现深入理解相关的知识,希望对你有一定的参考价值。
参考技术AFrEIA 是实现 INN 的基础,可以理解为实现 INN 的最重要的工具包。其分为两个模块,每个模块又有很多重要的类,以下是对这些类及其方法的描述。
framework 模块包含用于构建网络模型和推断节点在向前和向后方向上执行的顺序的逻辑。该模块包括四个类。
<1> Node类
一个 Node 即为一个 INN 基础构建块。
build_modules(verbose=True)
该方法返回该结点的输出结点的维度列表。会递归调用其输入结点的 build_modules 方法。使用这些信息来初始化该结点的 pytorch.nn.Module,即构建起基础块。
run_forward(op_list)
调用该方法来确定执行到该结点前的操作顺序。会递归调用其输入结点的 run_forward 方法。每个操作被追加到全局列表 op_list 中,操作的表示形式为 (node ID, input variable IDs, output variable IDs)。
run_backward(op_list)
该方法和 run_forward 相似,只是用来确定逆向执行到该结点前的操作顺序。调用该方法前须先调用 run_forward。
<2> InputNode类
InputNode 类是 Node 类的子类,是一种特殊的结点——输入结点,表示整个 INN 网络的输入数据(及逆向过程的输出数据)。
<3>OutputNode类
OutputNode 类也是 Node 类的子类,是一种特殊的结点——输出结点,表示整个 INN 网络的输出数据(及逆向过程的输入数据)。
<4>ReversibleGraphNet类
是 torch.nn.modules.module.Module 类的子类。这个类表示了 INN 本身。这个类的构造函数会确定 node list 中的输入结点和输出结点,并调用输出结点的 build_modules 方法以获得结点间的连接关系及维度,调用输出结点的 run_forward 方法获得正向过程的所有操作及涉及的变量;再调用输入结点的 run_backward 方法获得逆向过程的所有操作及涉及的变量。
modules 模块中都是 torch.nn.Module 的子类,都是可逆的,可用于 ReversibleGraphNet 中 Node 的构建。
1. Coefficient functions
class FrEIA.modules.coeff_functs.F_conv(in_channels, channels, channels_hidden=None, stride=None, kernel_size=3, leaky_slope=0.1, batch_norm=False)
F_conv 类使用多层卷积网络实现 INN 基础构建块中的 s、t 转换。其本身是不可逆的。
class FrEIA.modules.coeff_functs.F_fully_connected(size_in, size, internal_size=None, dropout=0.0)
F_fully_connected 类使用包含四层全连接层的神经网络实现 INN 基础构建块中的 s、t 转换。其本身是不可逆的。
2. Coupling layers
F_* 类本身都是不可逆的,而 coupling_layers 层中的类就是赋予 INN 可逆能力的。
class FrEIA.modules.coupling_layers.rev_layer(dims_in, F_class=<class \'FrEIA.modules.coeff_functs.F_conv\'>, F_args=)
当转换是 F_conv 时使用 rev_layer 类实现可逆。
class FrEIA.modules.coupling_layers.rev_multiplicative_layer(dims_in, F_class=<class \'FrEIA.modules.coeff_functs.F_fully_connected\'>, F_args=, clamp=5.0)
当转换是 F_fully_connected 时使用 rev_multiplicative_layer 实现可逆,思想是基于 RealNVP 基础构建块的双向转换。
class FrEIA.modules.coupling_layers.glow_coupling_layer(dims_in, F_class=<class \'FrEIA.modules.coeff_functs.F_fully_connected\'>, F_args=, clamp=5.0)
和 rev_multiplicative_layer 相似,只是思想是基于 Glow 基础构建块的双向转换。
3. Fixed transforms
这个模块的类也都是 torch.nn.Module 的子类,用于实现一些固定转换。在构建块之间插入置换层,用于随机打乱下一层的输入元素,这使得 u = [u1,u2] 的分割在每一层都不同,也因此促进了独立变量间的交互。
class FrEIA.modules.fixed_transforms.linear_transform(dims_in, M, b)
根据 y=Mx+b 做固定转换,其中 M 是可逆矩阵。其实现为:
class FrEIA.modules.fixed_transforms.permute_layer(dims_in, seed)
随机转换输入向量列顺序。其实现为:
4. Graph topology
用于对 INN 网络结构进行调整,如构建残差 INN 等。
class FrEIA.modules.graph_topology.cat_layer(dims_in, dim)
沿给定维度合并多个张量。
class FrEIA.modules.graph_topology.channel_merge_layer(dims_in)
沿着通道从两个独立的输入合并到一个输出(用于跳过连接等)。
class FrEIA.modules.graph_topology.channel_split_layer(dims_in)
沿通道拆分以产生两个单独的输出(用于跳过连接等)。
class FrEIA.modules.graph_topology.split_layer(dims_in, split_size_or_sections, dim)
沿给定维度拆分以生成具有给定大小的单独输出的列表。
5.Reshapes
class FrEIA.modules.reshapes.flattening_layer(dims_in)
正向过程是将 N 维张量拉平为 1 维的张量。
class FrEIA.modules.reshapes.haar_multiplex_layer(dims_in, order_by_wavelet=False)
使用 Haar wavelets 将通道按宽度和高度对半分为 4 个通道。
class FrEIA.modules.reshapes.haar_restore_layer(dims_in)
使用 Haar wavelets 将 4 个通道合并为一个通道。
class FrEIA.modules.reshapes.i_revnet_downsampling(dims_in)
i-RevNet 中使用的可逆空间 downsampling。
class FrEIA.modules.reshapes.i_revnet_upsampling(dims_in)
与 i_revnet_downsampling 相反的操作。
INN 的 loss 分为两部分:前向训练的损失和后向训练的损失。前后向训练的简单过程如下:
对应的损失函数如下:
其中,L2 是一种求平方误差的损失函数;MMD 则用于求两个分布之间的差异。
这篇文章前后读了很多次,这次重读,又有许多新收获。
INN 的基础构建块是 RealNVP 中的仿射耦合层;如果要构建深度可逆网络,可将基础构建块和残差训练思想结合,i-RevNet 就是深度可逆网络。基础构建块本身是可逆结构,因此其中的 s、t 转换不需要是可逆的,其可以是任意复杂的网络结构;更重要的是,构建块的可逆性允许我们同时为正向训练和反向训练应用损失函数,并可以从任一方向计算 s 和 t 的梯度。
至于如何将输入分割为两部分,目前采用的方法是随机(但为了可逆,必须是固定的)分割。但为了实现更好的训练结果,往往在基础构建块之间加入置换层,用于 shuffle 输入,这样是为了使得每次分割得到的 u1、u2 和上一构建块分割得到的不同。如果没有置换层,那么在训练过程中,u1、u2 都是相互独立的。
正向过程的信息丢失使得逆向过程存在模糊性,如果使用贝叶斯方法,用 p(x|y) 表示这种模糊性,也是可行的,但非常复杂。实际上我们希望网络学习完整的后验分布 p(x|y),我们可以尝试预测简单分布的拟合参数(如均值和方差),或者使用分布(而非固定值)来表示网络权重,甚至两者结合,但无论如何,这将限制我们预先选择一种固定的分布或分布族。 也可以使用 cGAN,但它难以训练的,并且经常遭遇难以检测的模式崩溃。
因此,INN 中引入 latent variable z,其捕获了从 x 到 y 的正向过程中丢失的信息,即 x 与 [y,z] 形成了双射。在正向训练过程中,我们可以得到真实潜在分布 ztrue,从 ztrue 中采样,再结合 y 值,即可得到一个固定的 x 值。即,p(x|y) 转换成一个固定函数 x=g(y,z)。不过,为了易于采样,我们需要将 ztrue 调整为一个简单的分布(如标准正态分布),这样我们就可以从简单分布中采样,结合 y 值得到 x,这样的准确率依然是很高的,因为简单分布和 ztrue 之间只是一个简单映射关系。至此看来,INN 和 cGAN 思想是很接近的,不过 INN 的可逆性使得其训练过程与 cGAN 不同,也有其特殊的优点。
INN 同时对正向和逆向过程进行训练,累积网络两端的损失项的梯度。 我们还可以在 x 上添加类似 GAN 的鉴别器损失,但到目前为止,在我们的应用程序中,MMD 是足够的,因此我们可以避免对抗性训练的麻烦。在大量训练数据的支持下,我们可以训练网络拟合正向模型,由于网络的可逆构造,我们可以免费得到逆向模型。
深入理解AbstractQueuedSynchronizerReentrantLock底层实现原理
目录
为什么说ReentrantLock是独占式的锁? 又是可重入的?
深入理解AbstractQueuedSynchronizer(一)_ Dream_it_possible!的博客-CSDN博客
上一篇文章主要介绍了AQS中的底层实现原理和结构,深入理解了条件等待队列和同步等待队列,总结一下上一篇的核心知识点:
1. Node和conditionObject的作用,Node定义了处于队列中的节点状态,定义了节点的模式,共享模式还是独占锁模式,同时实现了同步队列,conditionObject类定义了条件等待队列的firstWaiter和lastWaiter节点,实现了入队、唤醒等操作。
2. 条件等待队列是一个FIFO的单链表结构,因为插入节点的时候是从单链表中指针指向的最后一个节点之后插入的,出队是指针指向最后一个的一个节点移除,实则上是一个先进先出的队列结构。
3. 同步等待队列是一个双向的链表结构,用此结构能够快速的实现节点的移除和插入,因为抢占的时候处于队列后的节点能插入到第一个,如果用单链表结构,那么效率会比较低。
4. LockSupport提供唤醒线程的底层实现,由unpark(Thread)方法去唤醒线程。
5. 处于共享模式下的多线程竞争条件下,唤醒阻塞线程时,处于在条件队列的wait的线程需要出队进入到同步等待队列, 转队列由transferForSignal(Node node)方法实现。
6. 在一个线程使用资源后释放共享锁时,如果节点的状态为SINGAL会将节点的状态置为默认值0,如果同步队列的后续结点需要被唤醒,那么同步队列里的下一个节点唤醒,保证共享资源被完全释放掉。
基于AQS中常用的实现有很多,其中ReetrantLock、Semaphore、CyclicBarrier是常见的三种实现, 下面从源代码解释ReentrantLock是怎么基于AQS实现的。
ReentrantLock原理解析
ReetrantLock是基于AQS实现的一把独占式的锁,实现了JDKrt包里的Lock接口。
我们都知道一把锁最常用的就是加锁和解锁,下面跟着源码去追踪ReetrantLock中的Lock()方法和unLock()方法的底层实现原理, 提出一个问题?
为什么说ReentrantLock是独占式的锁? 又是可重入的?
Lock实现
首先看ReetrantLock类里的一个抽象的镜头内部类Sync, 该抽象类有一个抽象方法Lock()方法:
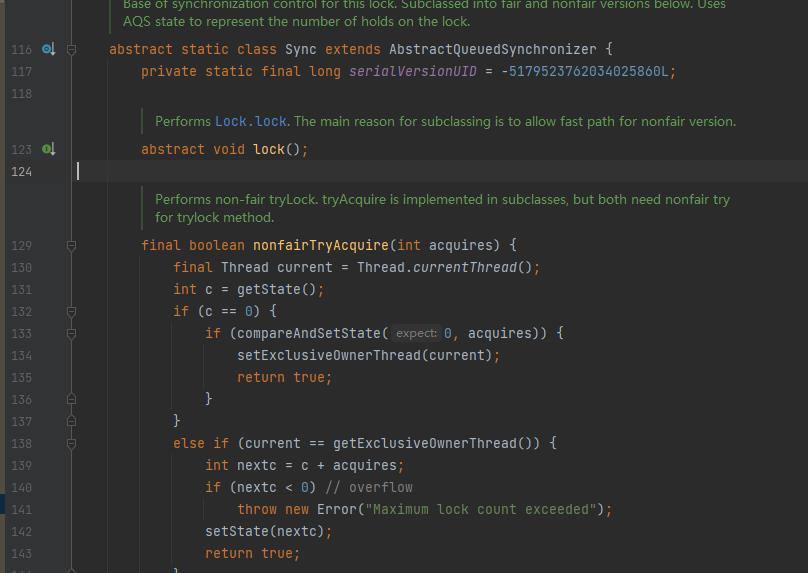
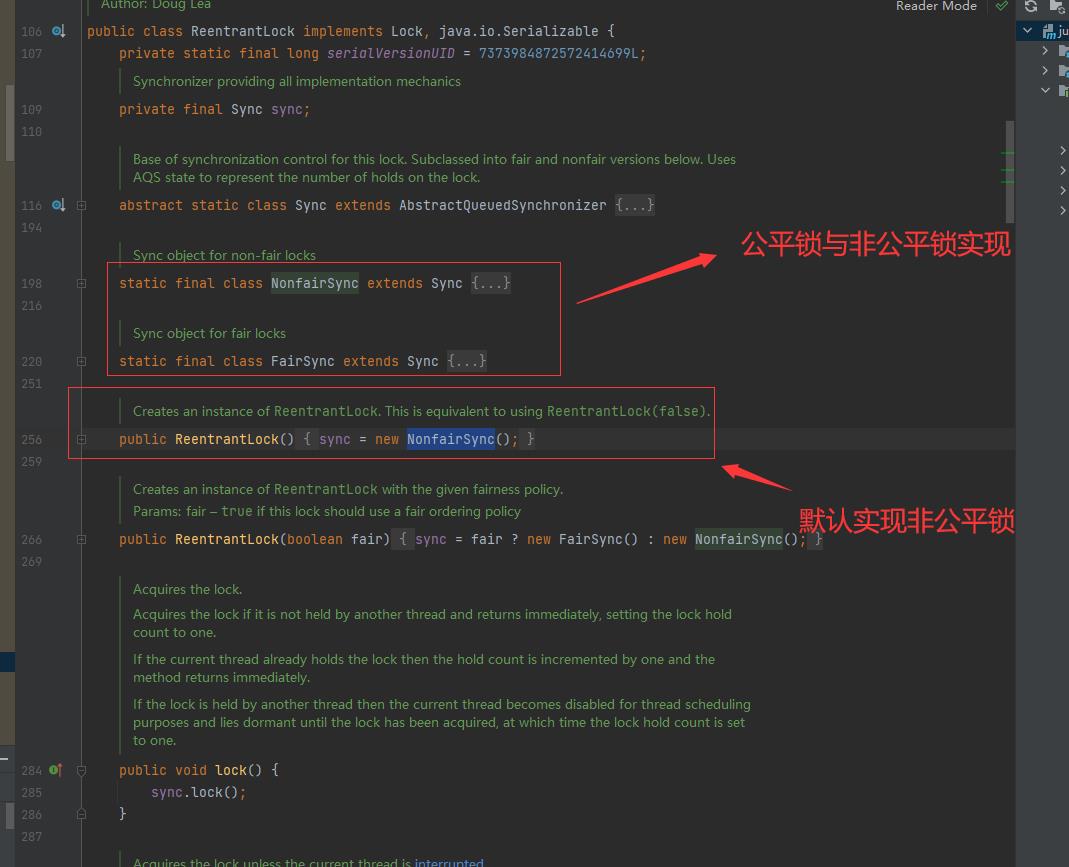
lock()抽象方法由Sync抽象类的2个实现类去实现,分别为:FairSync和UnFaiSync,默认实现是非公平锁,在ReentrantLock里的构造方法里实现:
因为默认是非公平的,我们先看非公平实现:
final void lock()
//如果state值为0,那么将state值置为1, 同时将当前线程设置到ExclusiveOWnerThread类里唯一拥有。
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
lock()方法里只有一个if..else, 判断CAS机制判断AQS中的state值是否为0,使用CAS操作保证原子性,如果为0,那么将state值置为1,同时将当前线程设置到AbstractQueuedSynchronizer的父类AbstractOwnableSynchronizer类里exclusiveOwnerThread属性里,相当于是独占的意思。如果state值为1,那么调用acquire(1)方法,接着看acquire()的实现。
此处找到了为什么ReentrantLock是独占式的答案,因为在addWaiter时,添加的Node节点是EXCLUSIVE,同时用到了exclusiveOwnerThread标记了当前线程获取到的锁,一个线程对应一个exclusiveOwnerThread。
public final void acquire(int arg)
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
//中断线程
selfInterrupt();
acquire()方法里就一个&&判断,如果成立,那么就执行selfInterrupt()方法,selfInterrupt方法比较好理解,就是条件成立那么该线程会被中断,不会继续执行,那我们把条件分解,接着看tryAcquire()方法,该方法在NonfairSync类实现:
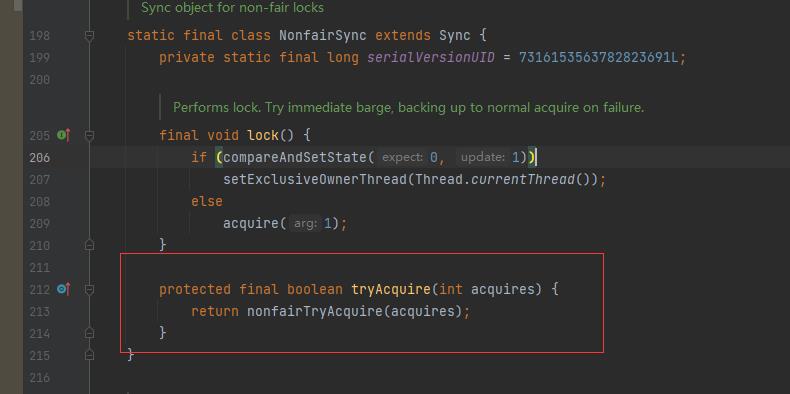
进入到nofairTryAcquire()方法:
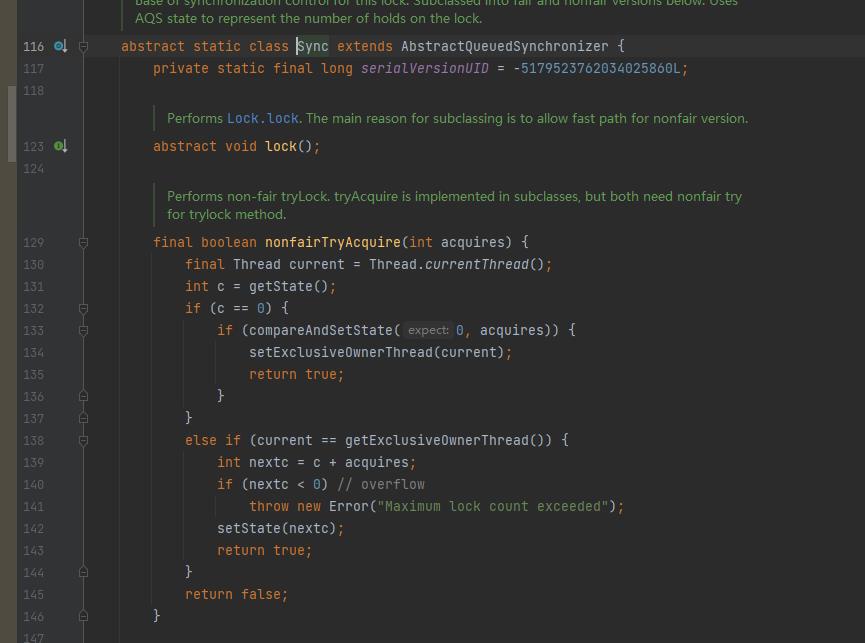
如果是处于一直加锁的状态不释放,那么过一段时间后一定会抛出Maximumlock count exceeded异常!当c的值超出了Int类型的最大数值时,那么c会变为负数,这个异常从另外一方面说明了ReentrantLock是可重入的,理解为一个线程对共享资源可以不断的加锁。
具体报错原因可以参考如下文章:
演示ReetrantLock锁的Maximum lock count exceeded问题_ Dream_it_possible!的博客-CSDN博客
小结
ReetrantLock的lock()实现原理主要包含以下几点:
1) 如果当前线程能直接拿到锁,那么会将state值置为1,然后设置currentThread。
2) 如果独占锁被其他线程给抢占了,那么其他线程会先通过addWaiter(Node.EXCLUSIVE), arg)方法进入到同步等待队列里。
3) 在同步等待队列的线程的Head节点会去再此执行tryAcquire()方法,该方法的最终返回是一个boolean类型,非公平锁的最终实现nonfairTryAcquire(int acquires)方法,每次加锁成功后state值为+1, 可以重复加锁,但要避免锁没有释放的问题。
4) 步骤3) 执行成功后,代表此线程加锁成功,同步队列会重新设置Head节点,然后将p.next=null, 帮助GC回收垃圾。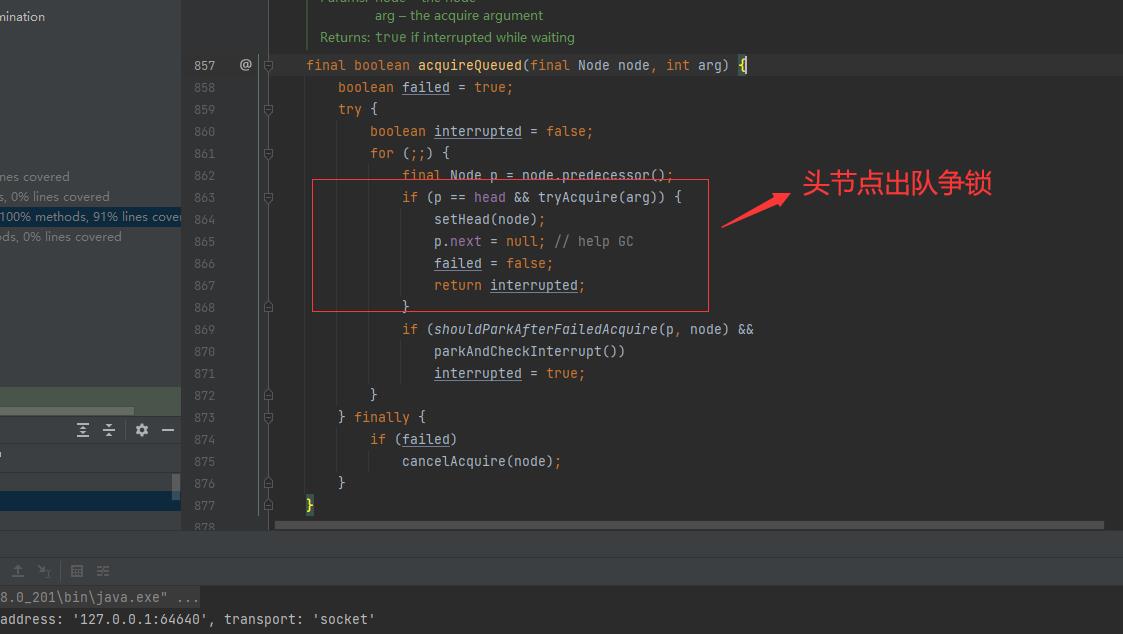
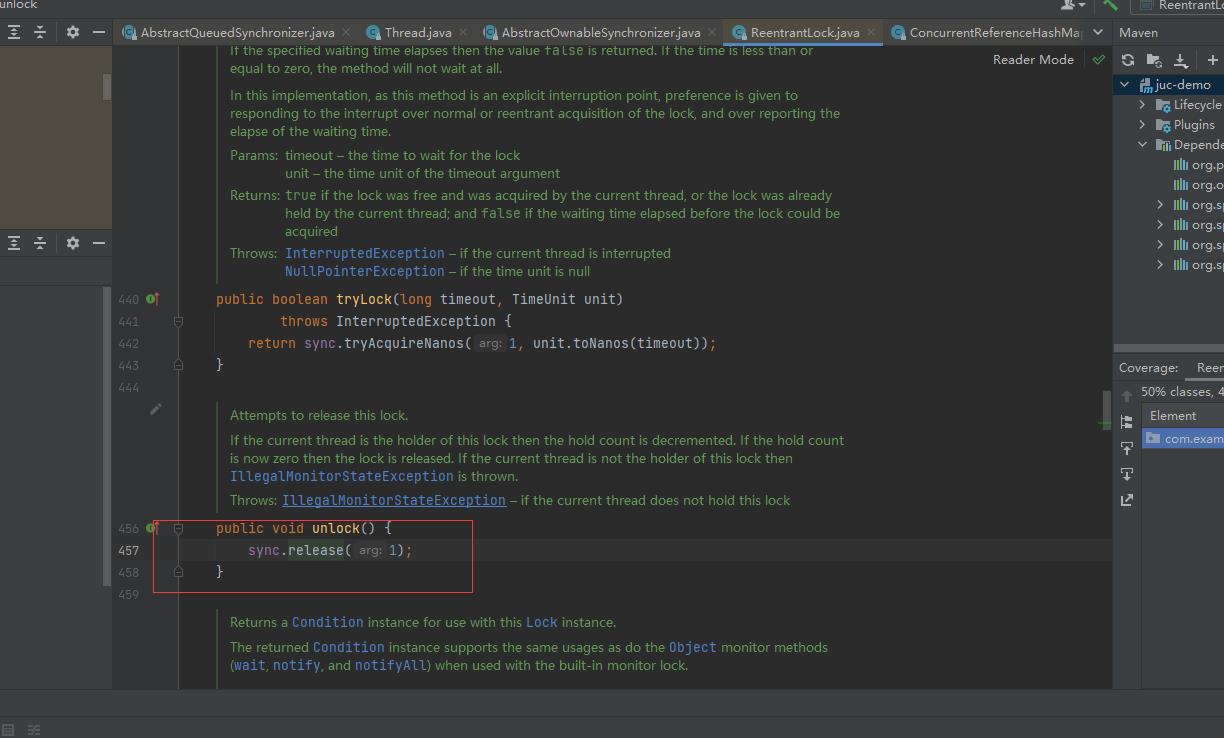
Unlock实现
unlock的实现相对于lock实现比较简单,直接调用了AbstractQueueSynchronizer里的release(int args)方法:
release方法的实现如下:
public final boolean release(int arg)
if (tryRelease(arg))
// tryRelease执行成功,那么唤醒Head的节点的下一个继承者
Node h = head;
if (h != null && h.waitStatus != 0)
// 进入到同步队列的线程默认状态是0,因此需要执行unpark操作确保唤醒
unparkSuccessor(h);
return true;
return false;
先看tryRelease, 当一个线程进入到此方法时,那么state的值会-1,由于state值是被volatile修饰的,能保证多线程环境下的可见性,tryRelease()方法原理其实很简单: 将共享的state值-1得到新值,然后将新值更新到state变量里。此处如果是其他线程Release的话,那么会抛出我们常见的IllegalMonitorStateException。
protected final boolean tryRelease(int releases)
// 来一个线程就将state-1
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 直到c,即state=0时,那么表示锁被完全释放掉。
if (c == 0)
free = true;
setExclusiveOwnerThread(null);
// 将新值更新到state里。
setState(c);
return free;
TryRelease()方法说白了就是讲自己线程加锁的state值-1, 直到state值为0,锁释放完毕, 继续看release()方法的逻辑 ,tryRelease执行成功后,将Head节点的下一个节点唤醒,因为进入到同步队列的线程默认状态是0,因此需要执行unpark,将waitStatus为SIGNAL的节点,即waitStatus的值为-1, 对SIGNAL的节点执行唤醒操作,这样的话能保证同步队列的所有线程都能够出队列,保证state值一直release到0为止,也就是确保共享资源被完全释放掉。
以上是关于INN实现深入理解的主要内容,如果未能解决你的问题,请参考以下文章